
Как думать подобно SQL Server: точка перехода - что это?
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine: What’s the Tipping Point?
В последней статье я добавил в наш запрос DisplayName и Age - два столбца, которых не было в нашем некластеризованном индексе:
SELECT LastAccessDate, Id, DisplayName, Age
FROM dbo.Users
WHERE LastAccessDate > '2018-09-02 04:00'
ORDER BY LastAccessDate;В результате я получил поиск ключа в плане выполнения:
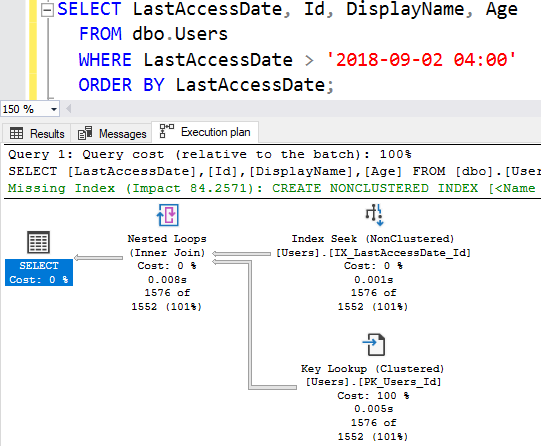
Я потратил много времени, говоря о перегрузке, которую вносит каждый поиск ключа. Проницательные читатели из моей аудитории, вероятно, заметили дату 2018-09-02 04:00 и подумали о довольно странном переключении мной даты в той истории.
Давайте выполним запрос просто на один час раньше.
Мы получили всего 1576 строк, начиная с 2 сентября в 4:00 (поскольку экспорт данных, которые я использую, был сделан 2 сентября 2018). Теперь попробуем взять 3:00:
SELECT LastAccessDate, Id, DisplayName, Age
FROM dbo.Users
WHERE LastAccessDate > '2018-09-02 03:00'
ORDER BY LastAccessDate;И SQL Server проигнорировал мой индекс:
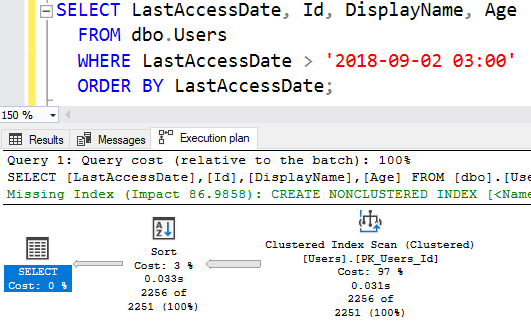
Хотя возвращается только 2256 строк, SQL Server предпочел просто просканировать всю таблицу, а не использовать комбинацию поиска по индексу + поиска ключа. В таблице имеется 299398 строк; и хотя мы запросили МЕНЕЕ ОДНОГО ПРОЦЕНТА СОДЕРЖИМОГО ТАБЛИЦЫ, индекс был проигнорирован.
Это правильное решение?
Чтобы выяснить это, давайте заставим использовать индекс.
Я выполню подряд два запроса - первый, позволяющий серверу самому решить, какой индекс использовать, и второй, навязывающий некластеризованный индекс с помощью хинта запроса:
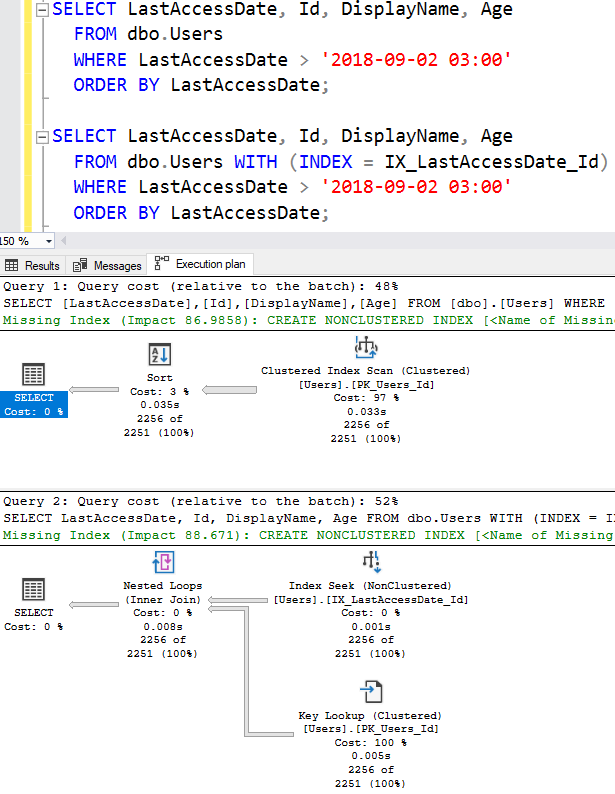
Теперь проверим число логических чтений на вкладке Messages:
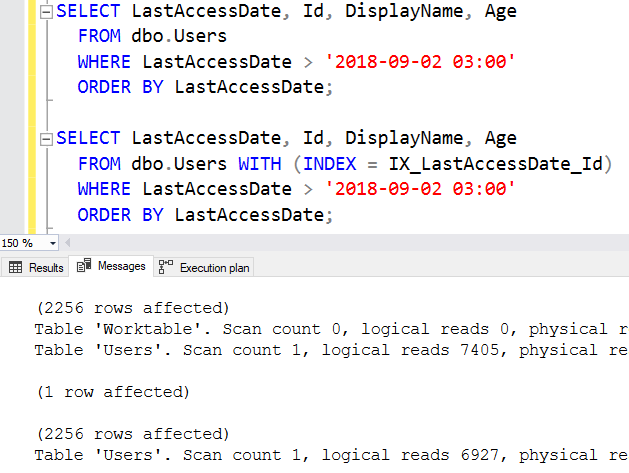
Когда мы выполняем сканирование таблицы, это дает 7405 чтений.
При использовании индекса имеем 6927 чтений, при том, что мы получаем только 2256 строк.
Хочется сказать, что SQL Server был неправ, но есть одно но: сканирование таблицы предсказывает 7405 чтений вне зависимости от того, сколько строк возвращает запрос. Это безопасное решение, когда SQL Server просто не может быть точно уверен, сколько строк будет возвращено. Если я в запросе укажу время всего лишь на один час раньше, 2:00:
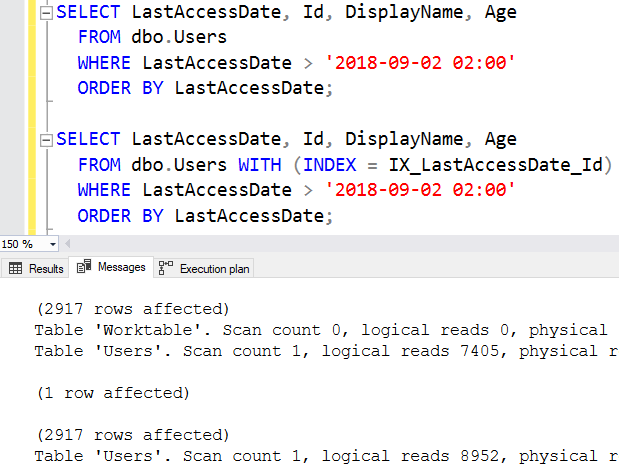
Теперь, когда 2917 строк соответствуют нашему фильтру, сканирование кластерного индекса окупается: читается меньше строк, чем в комбинации поиска по индексу и поиска ключа. Стоимость поиска ключа все более дорожает с каждым дополнительным выполнением.
Если мы вернемся назад на один день, разница станет огромной:
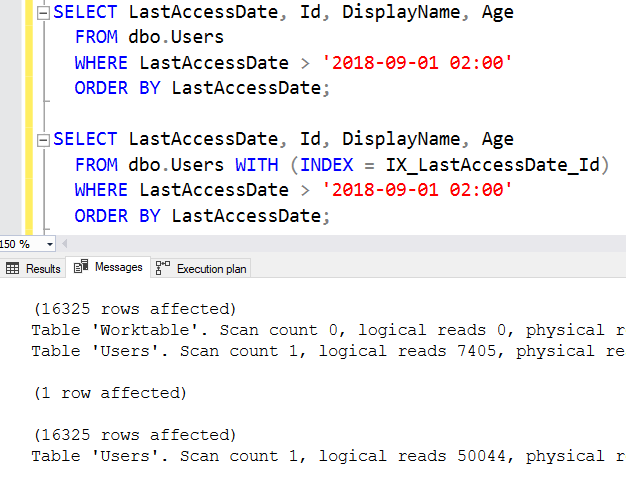
Мы получаем только 16325 строк - около 5% процентов таблицы - и даже если мы используем индекс, то делаем такое число логических чтений, которое эквивалентно более чем семикратному чтению всей таблицы. Именно эту проблему SQL Server пытается предотвратить, когда поиск ключей читает больше страниц, чем занимает таблица.
Наши значения 2:00-4:00 в предложении WHERE окружают точку перехода.
Хотя мы всего лишь вернули менее 1% пользователей, SQL Server уже считает более эффективным сканировать всю таблицу, а не использовать индекс.
В наших примерах запрос с 3:00 допустил лишь незначительную ошибку, выбрав консервативную сторону сканирования кластерного индекса, когда поиск по индексу + поиск ключа был бы более эффективным. Но кого это волнует в данном примере? Ведь разница была менее 500 чтений страниц. Я удовлетворен этим решением.
Итак, как SQL Server выясняет, какой из планов - поиск по индексу или сканирование таблицы - более предпочтителен до фактического выполнения запроса? Здесь вступает в дело статистика, и мы будем об этом говорить в следующей статье этой серии.
Одно решение - расширить индекс.
Когда вы видите в плане выполнения поиск по индексу + поиск ключа, наведите мышку на key lookup и посмотрите на список вывода (Output List):
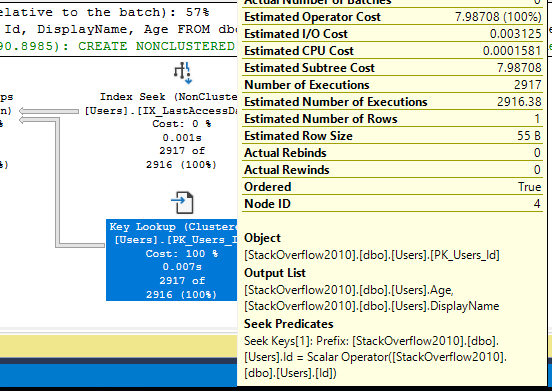
А теперь задавайте вопросы:
Может мой запрос обойтись меньшим числом строк? В целом проблема с точкой перехода опирается на число строк, которые возвращает запрос. Если вы можете сделать постраничную разбивку, делайте. Если вы можете ограничить число строк непосредственно или заставить пользователей выполнять более селективный поиск, также делайте это. Когда вы реально хотите масштабироваться, важно все.
Может мой запрос иметь меньше столбцов? Иногда пишут SELECT * не из-за лени, а потому, что действительно необходимы все столбцы. Чем больше столбцов нам требуется, тем меньше меня беспокоит поиск ключей - потому что я просто не могу позволить себе хранить несколько копий полной таблицы с разными сортировками.
Насколько велики столбцы? Если они велики - NVARCHAR(MAX), VARCHAR(MAX), JSON, XML и т.д., то дискуссия прекращается. Меня устроит стоимость поиска ключей. Мне бы не хотелось добавлять их в индексы только потому, что они занимают слишком много места.
Насколько часто обновляются столбцы? SQL Server не имеет асинхронных индексов: каждый индекс постоянно должен быть синхронизирован с кластеризованным индексом. Например, если столбец Age постоянно меняется, то может иметь смысл не дублировать его по многочисленным индексам, поскольку мы столкнемся с блокировками на этих индексах при выполнении обновлений. (Для вставки и удаления это не столь важно, так как в любом случае нам приходится обращаться к индексам, независимо от того, сколько столбцов они содержат).
Если нам нужны эти столбцы, следует ли добавлять их в некластеризованный индекс? Добавляя их, мы могли бы полностью избавиться от поиска ключей.
Здесь нет твердокаменных ответов относительно правильных или ошибочных действий, только поиск компромиссов ждет вас на пути повышения производительности. Когда вы начинаете, то действительно не замечаете, когда SQL server советует перейти от поиска по индексу к сканированию таблицы, поскольку ваши данные относительно малы. По мере роста данных и требования ваших пользователей повысить производительность эти вещи начинают приобретать большое значение.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой