
Изменения языка T-SQL в SQL Server 2022. Часть 2
Пересказ статьи FrankDolan77. T-SQL Language Changes in SQL Server 2022 Part 2
Эта статья является второй частью, которая также посвящена изменениям в T-SQL, которые появились в этой новой версии платформы баз данных.
В предыдущей статье обсуждались DISTINCT FROM, DATE_BUCKET, GENERATE_SERIES, GREATEST/LEAST, STRING_SPLIT и DATETRUNC. Здесь я рассмотрю APPROX_PERCENTILE_CONT, APPROX_PERCENTILE_DISC и функции манипуляции битами. Будут рассмотрены также изменения в FIRST_VALUE, LAST_VALUE и LTRIM/RTRIM/TRIM.
Это поверхностный взгляд на эти функции языка, т.к я все еще экспериментирую, изучая их. Я оцениваю SQL Server 2022 с точки зрения перспективы апгрейда системы, поэтому основное внимание уделяется возможности этих изменений в языке сделать более простым написание кода. В моих экспериментах используется SQL Server 2022 RC0.
APPROX_PERCENTILE_CONT
Функция PERCENTILE_CONT уже имеется в T-SQL. Эта функция возвращает значение из набора данных на основе заданного процентиля. Это оконная функция, требующая в предложении OVER() значение, ближайшее к процентилю, которое не обязательно может существовать в данных. Если я выполню простой запрос из Docs в базе данных AdventureWorks, то увижу следующее:
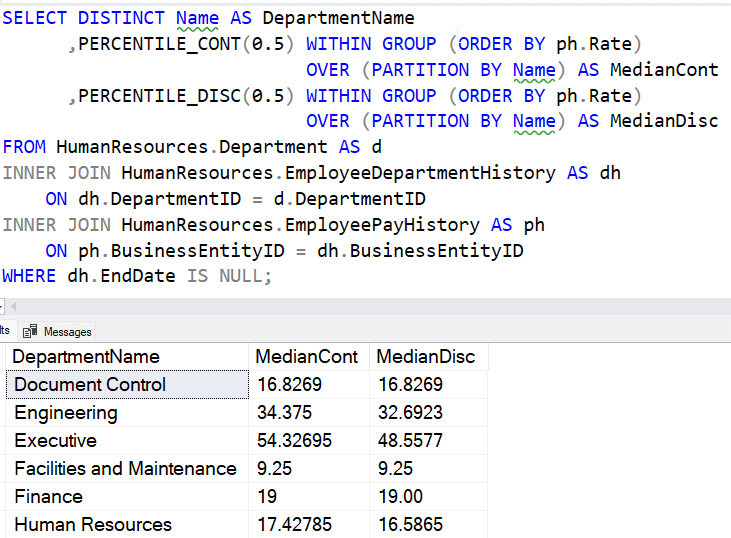
Приблизительная версия этой функции пытается получить приблизительное значение той же функции без необходимости читать все данные. Это значение должно находиться в тех же пределах спецификации ошибки. Microsoft Docs говорит об этой функции так:
Эта функция возвращает приблизительное интерполированное значение из набора значений в группе на основе значения процентиля и спецификации сортировки. Так как это приблизительная функция, результат будет находиться в пределах ошибки, основанной на ранге, с определенным доверительным уровнем. Значение процентиля, возвращаемое этой функцией, основано на непрерывном распределении значений столбца, и результат будет интерполирован. Из-за этого результат может отличаться от значений в наборе данных. Одним из распространенных вариантов использования этой функции является предотвращение выбросов данных. Эту функцию можно использовать в качестве альтернативы PERCENTILE_CONT для больших наборов данных, где приемлема незначительная ошибка с более быстрым откликом по сравнению с точным значением процентиля с медленным откликом.
Т.е. если вы можете допустить приблизительное значение и хотите минимизировать требуемые ресурсы, эта функция поможет. Она подобна функции APPROX_COUNT_DISCTINCT.
Это не оконная функция, и она не использует предложение OVER. Имеется предложение группировки, и я могу там указать порядок. Если выполнить это на наборе данных AdventureWorks, будут получены те же самые результаты.
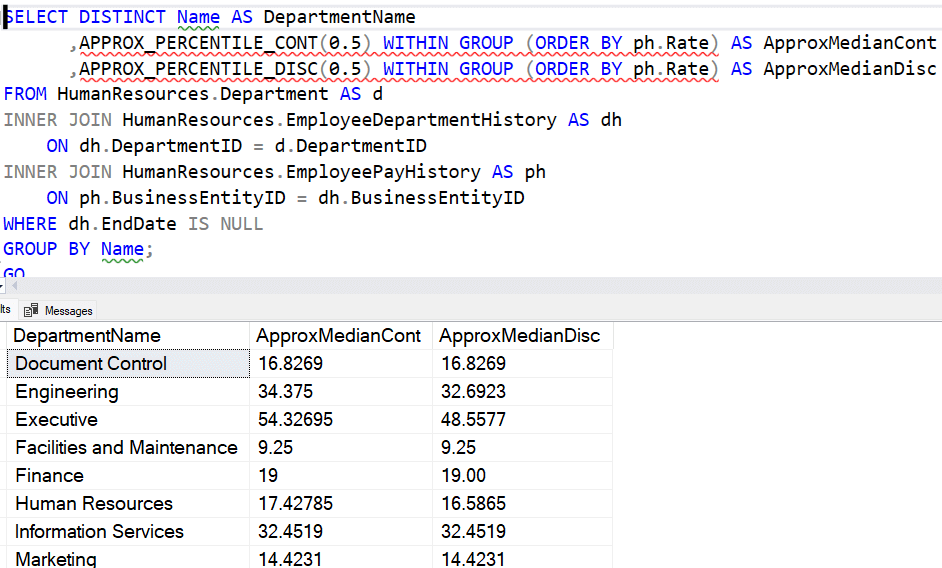
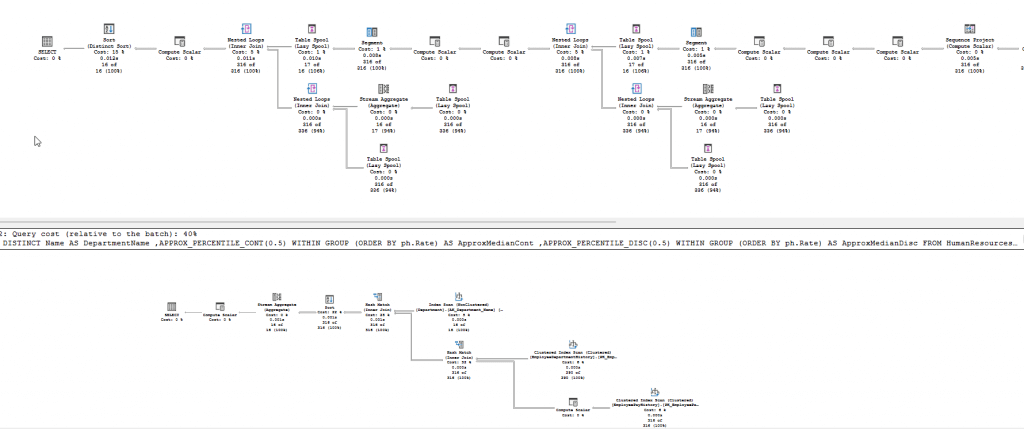
Если посмотреть план выполнения, видно, что приблизительная версия использует значительно более простой план. На скриншоте сверху показан план для PERCENTILE_CONT, а внизу - для APPROX_PERCENTILE_CONT.
APPROX_PERCENTILE_DISC
Функции PERCENTILE_DISC и APPROX_PERCENTILE_DISC связаны аналогичным образом, при этом новая приблизительная функция выполняется быстрее и менее требовательна к ресурсам, потенциально за счет точности. Обе эти функции будут опять же возвращать значение на основе процентиля данных.
Как и с функциями выше, я получаю те же значения в AdventureWorks как для точной, так и для приблизительной функций. Формы планов выполнения выглядят похожим образом с существенно более простым планом для приблизительной функции.
Побитовые операции
В 2022 было добавлено несколько побитовых функций, позволяющих получать результаты битового сдвига. Битовое кодирование и манипуляция - это то, что можно использовать как набор переключателей, которые быстрее и проще установить, чем использовать значения отдельных столбцов. По моему мнению, это труднее читать, но этот тип операций используется в некоторых внутренних настройках. Например, число @@options на самом деле представляет собой набор установленных битов.
Чтобы проще было объяснить, давайте возьмем число. Например, если взять 64, оно в двоичном хранении является установкой 7 бита. Это значение 1000000. Я могу увидеть его в SELECT, используя функцию AND (&) с этим значением. Взгляните на это, и вы увидите, что каждый бит основан на степени числа 2.
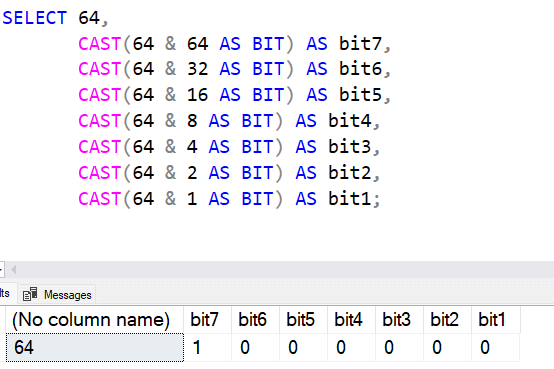
Следующие функции будут воздействовать на эти биты с помощью различных операций.
LEFT_SHIFT()
Функция LEFT_SHIFT() выполняет сдвиг битов влево, как можно догадаться. В этом случае, если выполнить ее для значения 64, то получим:
SELET LEFT_SHIFT(64,1) as NewValue
NewValue
-------------
128Функция требует двух параметров.
- Выражение - целое ли двоичное значение, которое не является большим объектом (LOB)
- Число битов для сдвига влево
Возвращаемое значение - новое двоичное или целое число. Сдвиг выполняется над двоичным значением, поэтому это число типа BIGINT.
Если я выполню это для числа 32 со сдвигом 1, то я получу 64. Это то, что ожидалось, если посмотреть на оба набора битов. Я использовал запрос с UNION, чтобы было проще это увидеть. Вот код:
DECLARE @number int = 32, @new int;
SELECT left_shift(@number, 1)
SELECT @new = left_shift(@number, 1)
SELECT @number,
CAST(@number & 128 AS BIT) AS bit8,
CAST(@number & 64 AS BIT) AS bit7,
CAST(@number & 32 AS BIT) AS bit6,
CAST(@number & 16 AS BIT) AS bit5,
CAST(@number & 8 AS BIT) AS bit4,
CAST(@number & 4 AS BIT) AS bit3,
CAST(@number & 2 AS BIT) AS bit2,
CAST(@number & 1 AS BIT) AS bit1
UNION
SELECT @new,
CAST(@new & 128 AS BIT) AS bit8,
CAST(@new & 64 AS BIT) AS bit7,
CAST(@new & 32 AS BIT) AS bit6,
CAST(@new & 16 AS BIT) AS bit5,
CAST(@new & 8 AS BIT) AS bit4,
CAST(@new & 4 AS BIT) AS bit3,
CAST(@new & 2 AS BIT) AS bit2,
CAST(@new & 1 AS BIT) AS bit1;А вот результат. Как видно, 1 сдвинулась на одну позицию влево. Сдвиг также использует 0 для заполнения позиций справа.

Если я повторю это с числом 27, то получу 54. Побитовый сдвиг - это способ умножения на основание, которым является 2. Другими словами, это удваивает значение для каждого сдвигаемого бита.

RIGHT_SHIFT()
Как можно догадаться, взаимной функцией к LEFT_SHIFT() является RIGHT_SHIFT(). Эта функция перемещает биты вправо, сдвиг на каждый бит есть деление на 2.
Давайте использовать тот же самый код, приведенный выше, но с этой новой функцией. Теперь мы видим, что если начать с 64 и сдвинуть 2 раза вправо, то получим 16. Это означает 64/2 = 32 и 32/2 дает 16. Вот этот код:
DECLARE @number INT = 64, @new INT, @shifts INT = 2;
SELECT right_shift(@number, @shifts)
SELECT @new = right_shift(@number, @shifts)
SELECT @number,
CAST(@number & 128 AS BIT) AS bit8,
CAST(@number & 64 AS BIT) AS bit7,
CAST(@number & 32 AS BIT) AS bit6,
CAST(@number & 16 AS BIT) AS bit5,
CAST(@number & 8 AS BIT) AS bit4,
CAST(@number & 4 AS BIT) AS bit3,
CAST(@number & 2 AS BIT) AS bit2,
CAST(@number & 1 AS BIT) AS bit1
UNION
SELECT @new,
CAST(@new & 128 AS BIT) AS bit8,
CAST(@new & 64 AS BIT) AS bit7,
CAST(@new & 32 AS BIT) AS bit6,
CAST(@new & 16 AS BIT) AS bit5,
CAST(@new & 8 AS BIT) AS bit4,
CAST(@new & 4 AS BIT) AS bit3,
CAST(@new & 2 AS BIT) AS bit2,
CAST(@new & 1 AS BIT) AS bit1;И результаты. Обратите внимание, что бит 7 сдвинут на 2 позиции вправо.

Что произойдет, если дважды сдвинуть 54? Число 27 не делится на 2 нацело. Вы могли бы догадаться, что мы получим целую часть результата деления (13) с отбрасыванием десятичной части (.5). Это целочисленное деление. Вот результаты битового сдвига.

В другом примере давайте дважды сдвинем вправо 100. Все единички сдвигаются вправо с заполнением нулями позиций слева.

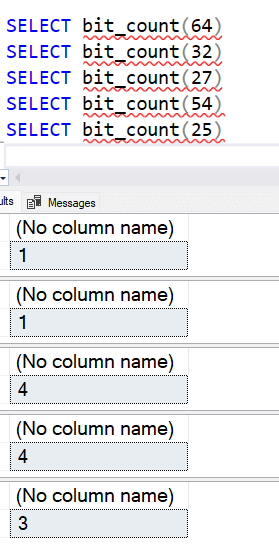
BIT_COUNT()
Функция BIT_COUNT() предназначена для подсчета числа битов, установленных в 1, в числовом или двоичном выражениях. Я точно не знаю, для чего это может вам понадобиться, хотя если допустить, что это набор переключателей, то вы получите число переключателей, установленных в 1. Можно представить себе что-то типа посещаемости класса, где каждый студент имеет свое место. Тогда пусть бит 1 - это Фрэнк, бит 2 - Эми, бит 3 - Марк и т.д. Я могу закодировать посещаемость установкой этих битов, а затем посчитать посещаемость студентов класса с помощью этой функции.
Используя примеры выше, мы должны получить такие результаты с помощью этой функции:
- 64 = 1
- 32 = 1
- 27 = 4
- 54 = 4
- 25 = 3
Вот что дает функция:
GET_BIT()
Как можно ожидать, GET_BIT() возвращает значение числового (или двоичного) выражения. Подобно LEFT_SHIFT(), нам потребуется второй параметр, которым является сдвиг бита. 0 - это крайний справа бит, поэтому, если я хочу получить третий бит из 100, я ищу 0. Вы можете увидеть результаты ниже, но бит 3 фактически является четвертым справа, поскольку мы стартуем с 0.
Замечание. Я перенумеровал биты из кода выше.
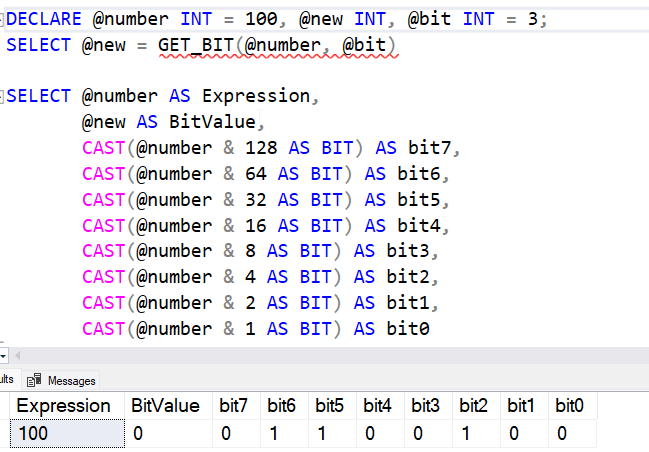
Если вернуться к примеру с посещаемостью, я могу получить присутствие конкретного студента, указав его место в качестве значения, чтобы узнать был ли он в классе.
SET_BIT()
SET_BIT() является обратной к функции GET_BIT(). Она позволяет вам установить значение бита в выражении. Интересно, что вы можете не указывать значение, если хотите установить его в 1. Если вы хотите установить 0, то следует указать третьим параметром 0.
Вот код, который показывает установку 3-го бита в значении 100. Значение бита 3 равно 0 в 100, и если я не укажу третий параметр, этот бит будет установлен в 1. Эта позиция в двоичном значении является переключателем для 8, поэтому это фактически добавляет к значению 8 или 2^3. Вот код:
DECLARE @number INT = 100, @new INT, @bit INT = 3;
SELECT @new = SET_BIT(@number, @bit)
SELECT @number AS Expression,
CAST(@number & 128 AS BIT) AS bit7,
CAST(@number & 64 AS BIT) AS bit6,
CAST(@number & 32 AS BIT) AS bit5,
CAST(@number & 16 AS BIT) AS bit4,
CAST(@number & 8 AS BIT) AS bit3,
CAST(@number & 4 AS BIT) AS bit2,
CAST(@number & 2 AS BIT) AS bit1,
CAST(@number & 1 AS BIT) AS bit0
UNION
SELECT @new,
CAST(@new & 128 AS BIT) AS bit7,
CAST(@new & 64 AS BIT) AS bit6,
CAST(@new & 32 AS BIT) AS bit5,
CAST(@new & 16 AS BIT) AS bit4,
CAST(@new & 8 AS BIT) AS bit3,
CAST(@new & 4 AS BIT) AS bit2,
CAST(@new & 2 AS BIT) AS bit1,
CAST(@new & 1 AS BIT) AS bit0
;
GOРезультат, как показано ниже, равен 108.

По сути это способ добавлять или вычитать значение из целого числа.
FIRST_VALUE() / LAST_VALUE()
Эти функции были в SQL Server последних версий. Однако обе FIRST_VALUE() и LAST_VALUE() приобрели два предложения. Мы можем добавить одно из этих предложений в функцию:
- IGNORE NULLS - игнорирует значения NULL в наборе данных при вычислении первого значения по разбиению.
- RESPECT NULLS - учитывает значения NULL в наборе данных при вычислении первого значения по разбиению.
Это означает, что если в разбиении (наборе данных) имеются значения NULL, мы можем либо включать, либо исключать их из рассмотрения. В качестве примера я получил набор данных в виртуальной таблице, которая упорядочивает несколько сегментов данных. Вот код:
SELECT bucket,
FIRST_VALUE(val) OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS firstvalue,
LAST_VALUE(val) OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lastvalue
FROM ( VALUES
('a', 1, 'first'),
('a', 2, NULL),
('a', 3, 'LAST'),
('b', 1, NULL),
('b', 2, 'mid'),
('b', 3, 'last'),
('c', 1, 'first'),
('c', 2, 'mid1'),
('c', 3, 'mid2'),
('c', 4, NULL)
) A(bucket, bucketorder, val)Если я выполню функцию в версии 2019, то увижу NULL-значения.
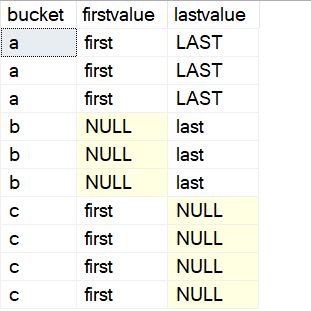
Я могу добавить в 2022 предложение для IGNORE NULLS. Оно указывается за функцией перед предложением OVER(). Вот код:
SELECT bucket,
FIRST_VALUE(val) IGNORE NULLS OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS firstvalue,
LAST_VALUE(val) IGNORE NULLS OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lastvalue
FROM ( VALUES
('a', 1, 'first'),
('a', 2, NULL),
('a', 3, 'LAST'),
('b', 1, NULL),
('b', 2, 'mid'),
('b', 3, 'last'),
('c', 1, 'first'),
('c', 2, 'mid1'),
('c', 3, 'mid2'),
('c', 4, NULL)
) A(bucket, bucketorder, val)Теперь в том же наборе данных NULL-значения отсутствуют.

Если я добавлю RESPECT NULLS, то получу те же результаты, что в 2019. Это означает, что RESPECT NULLS принимается по умолчанию.
LTRIM()
Есть изменение и в функции LTRIM() в SQL Server 2022, которое позволяет отсечь конкретные символы. По умолчанию это пробел, но вы можете это изменить. В описании функции говорится, что она удаляет char(32) или другие символы в начале строки. Это не работает в CTP 2.1, но работает в RC0. Вот код примера:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
LTRIM(STRINGVALUE,' '),
LEN(LTRIM(StringValue,' ')) AS TrimLength
FROM (
VALUES
(' String1'),
(' String2'),
(' String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('bbbString4bbbb')
) A(StringValue)
GOВ этом коде я удаляю пробелы в строке слева. Если посмотреть на строки, там есть 4 значения, имеющих пробелы слева (string1, string2, string2, and string5). Когда я выполняю код, то получаю такой результат:

Эти 4 строки короче, поскольку удалены пробелы. Пробелы бывает сложно увидеть, поэтому я указываю длину. Теперь давайте удалим другой символ. Я удалю 'a' с помощью этого кода:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
LTRIM(STRINGVALUE,'a'),
LEN(LTRIM(StringValue,'a')) AS TrimLength
FROM (
VALUES
(' String1'),
(' String2'),
(' String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('bbbString4bbbb')
) A(StringValue)
GOВ этих результатах только string4 содержит a в начале строки, и все они удалены.

Кажется, можно также удалить несколько символов, как показывает следующий код:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
LTRIM(STRINGVALUE,'The'),
LEN(LTRIM(StringValue,'The')) AS TrimLength
FROM (
VALUES
('The quick brown fox'),
('The end of the story'),
('TheThe Boat')
) A(StringValue)
GOИ результат:
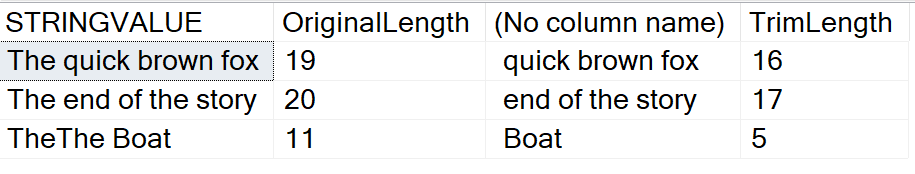
Заметьте, что удаляется не слово "The", а любые из этих символов в начале строки. Т.е. если "t", "h" или "e" находятся в начале строки, они удаляются. Это означает, что SELECT LTRIM('tehhts', 'the') вернет только 's'.
RTRIM()
Подобно LTRIM(), RTRIM() также изменилась, позволяя удалять заданные символы справа. Вот пример:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
RTRIM(STRINGVALUE,'b'),
LEN(RTRIM(StringValue,'b')) AS TrimLength
FROM (
VALUES
(' String1'),
(' String2'),
(' String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('String6bbbb')
) A(StringValue)
GOРезультаты похожи на LTRIM(), но символы удаляются справа.
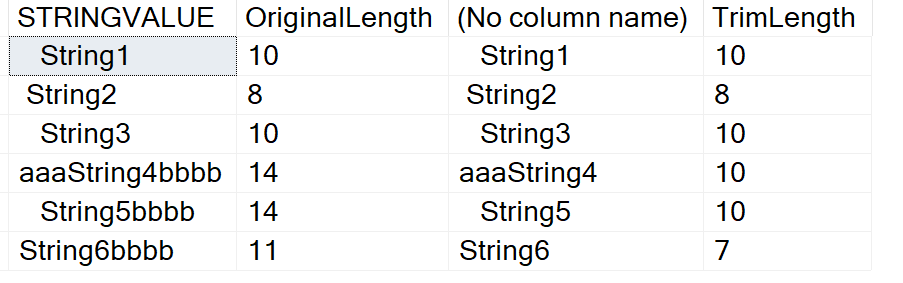
Это полезная функция, т.к. иногда мы получаем лишние символы, вводимые клиентами и отличные от пробела, которые требуется удалить.
TRIM()
TRIM() тоже была усилена, но синтаксис отличается. Новый синтаксис для 2022 приведен в Docs:
TRIM ( [ LEADING | TRAILING | BOTH ] [символы FROM ] строка )Я могу добавить LEADING, чтобы получить поведение LTRIM, TRAILING для RTRIM или BOTH для TRIM. Потом идет строка, которая содержит символы, которые я хочу удалить, затем сама строка. Необычный выбор синтаксиса, хотя читается хорошо. Некоторые примеры в коде:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
TRIM(BOTH 'b' FROM STRINGVALUE),
LEN(TRIM(BOTH 'b' FROM STRINGVALUE)) AS TrimLength
FROM (
VALUES
(' b String1b'),
(' String2b'),
('b String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('bString6bbbb')
) A(StringValue)
GOЕсли мы ищем строки, где 'b' находится в начале и в конце строки, то обнаружим, что в строках string1, string2, string3, string4, string5 и string6 должны быть удалены символы b. Результаты это подтверждают:
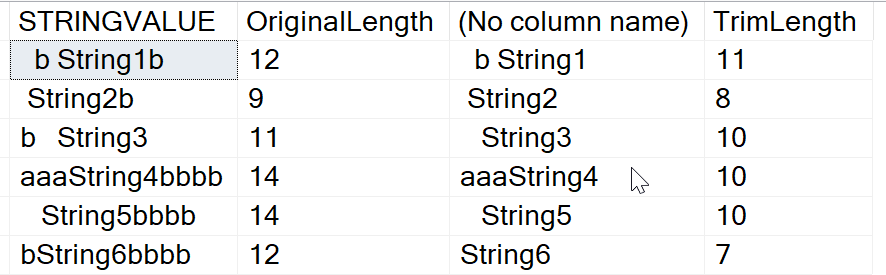
Строка string1 не содержит первым символом b, поскольку там находится пробел, а мы не добавили пробел в поисковый параметр. Но в строке string3 лидирующий символ b удален. В string6 были удалены и лидирующий, и концевой символы.
Очевидно, что это удобно при удалении нескольких разных начальных символов, но я думаю, что это может вызвать проблемы с кодом, который имеет несколько символов, как, например, в случае, когда мы хотим удалить "Mr. " из "Mr. XX YY", но в строке "Mr. Michael" будут удалены обе буквы M. Забавная функция.
Итоги
Тут есть интересные функции. Мне нравятся приближенные функци, т.к. они могут сэкономить ресурсы, хотя я не знаю, использовал бы я их, если сейчас мы не используем PERCENTILE_CONT и PERCENTILE_DISC. Побитовые сдвиги заставляют меня задуматься о том, где мы могли бы получить выгоду при кодировании переключателей. Я думаю, что здесь были бы полезны настройки конфгурации, хотя я бы обеспокоился сложностью кодирования и постоянным объяснением их заказчикам.
Функции TRIM дают хорошее улучшение, но беспокоят возможные проблемы с множественными символами. В то же время я не знаю, хотел ли я иметь несколько операторов TRIM. Трудно сказать, насколько они полезны в свете опасности их использования.
Статьи блога по теме
Крутая штука в SQL Server 2022 – IS DISTINCT FROM
Мои любимые улучшения T-SQL в SQL Server 2022
SQL Server 2022: Появление функции DATETRUNC, поэтому вы можете обрезать даты и прочее
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой