
Еще о выборе и порядке столбцов многостолбцовых некластеризованных индексов
Пересказ статьи Mike Byrd. More on Column Choice and Order for Multi-column Non-Clustered Indexes
В прошлом году я публиковал статьи по индексам, в частности, "Индексы: когда селективность столбца не является обязательным требованием" и "Оптимизатор запросов предлагает неправильный индекс и план запроса - почему?". Эта статья является просто продолжением темы взаимодействия оптимизатора с мастером индексов.
Мы все слышали или читали о том, что следует всегда определять индекс (для конкретного запроса), используя первыми столбцы, участвующие в выражениях равенства предложения WHERE; но сегодня давайте рассмотрим пример и посмотрим, что произойдет.
Рассмотрим следующий запрос. Он из AdventureWorks 2017, модифицированный скриптом от Jonathan Kehayias. База данных содержит таблицу Sales.SalesOrderHeader, в которой число строк увеличено с 31465 до 1258600, удалены все некластеризованные индексы и перекошены данные для SalesPersonID = 289 (чтобы иметь больше строк):
Мы получаем результирующий набор из 58967 строк, 29295 логических чтений, время ЦПУ 588 мс и прошедшее время (ElapsedTime) 584 мс (времена взяты из плана выполнения XML). Интересно, что времена из плана выполнения XML не совпадают с временами из результатов SET STATISTICS ON - интересно, какие из них верные; возможно, разберусь к следующей статье. План выполнения выглядит так:
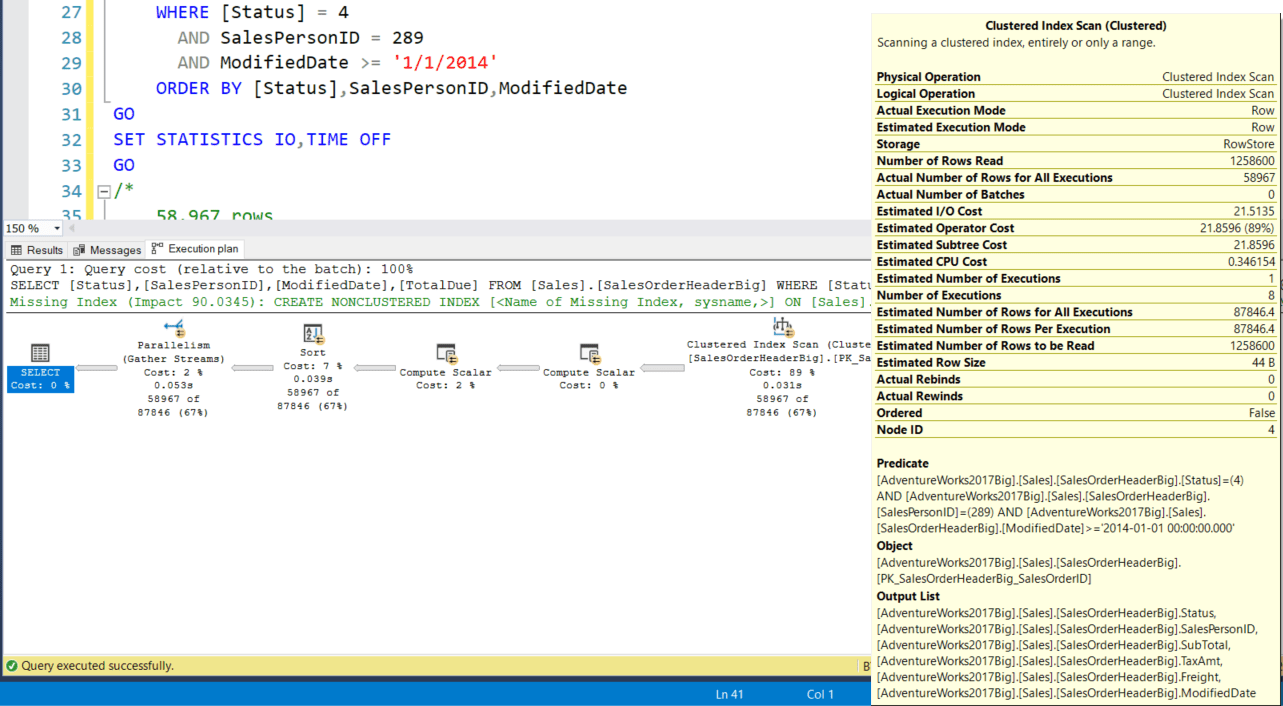
Этот план содержит сканирование кластеризованного индекса, а стоимость запроса равна 24,4894.
Я также пробовал изменить порядок столбцов в предложении WHERE, но результаты (и план выполнения) оказались идентичными, за исключением порядка столбцов в Predicate, где условия на параметры были в том же порядке, который указывался в предложении WHERE.
План запроса также предлагал отсутствующий покрывающий индекс вида
Заметьте, что столбцы предлагаемого индекса, Status и SalesPersonID, имеют тот же порядок, что и в предложении WHERE. Первые два столбца используют оператор "=", а третий столбец - ">=". Также обратите внимание, что SS2019 параметризует запрос.
Теперь давайте рассмотрим 3 различных индекса (первым является предлагаемый), при этом последние два содержат те же столбцы, что и первый, но в другом порядке.
Обратите внимание, что я использую Row Compression (сжатие строк) во всех трех индексах. За мои 12+ лет использования сжатия строк еще не обнаружено их пагубного влияния на производительность, и почти во всех случаях имелось существенное улучшение производительности при уменьшении числа логических чтений (SQL Server 2008 Table Compression (logicalread.com)).
Итак, если вы повторно выполните исходный запрос, мы по-прежнему получим 58967 строк и поиск в некластеризованном индексе, время выполнения ЦП 41 мс, прошедшее время 551 мс, число логических чтений 174, стоимость запроса 0.306444 при следующем плане выполнения:
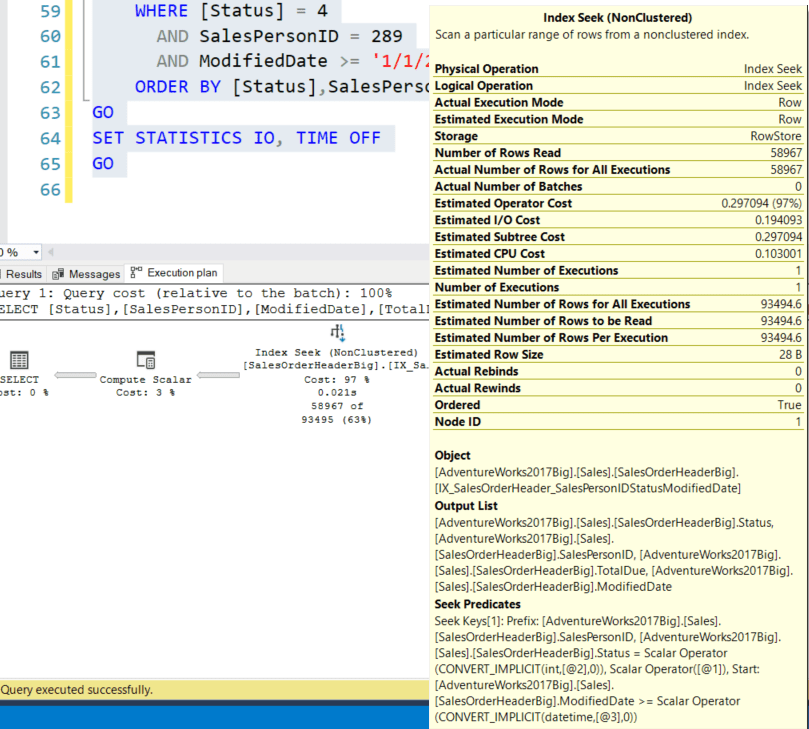
Теперь мы получаем Seek Predicate (поисковый предикат) на всех трех столбцах индекса, но ПОСТОЙТЕ! План запроса использовал второй индекс (а не предложенный первый): IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate. Хмм, оптимизатор запросов предложил один индекс, а фактическое выполнение использовало совсем другой (переставлены Status и SalesPersonID). Мы еще поговорим об этом ниже, но сначала давайте заставим запрос использовать отсутствующий индекс в исходном запросе:
Мы получаем тот же самый результирующий набор (58967 строк) при ЦП = 42мс, времени выполнения 547, логических чтениях 182 и стоимости запроса 0,30707 в соответствии со следующим планом:
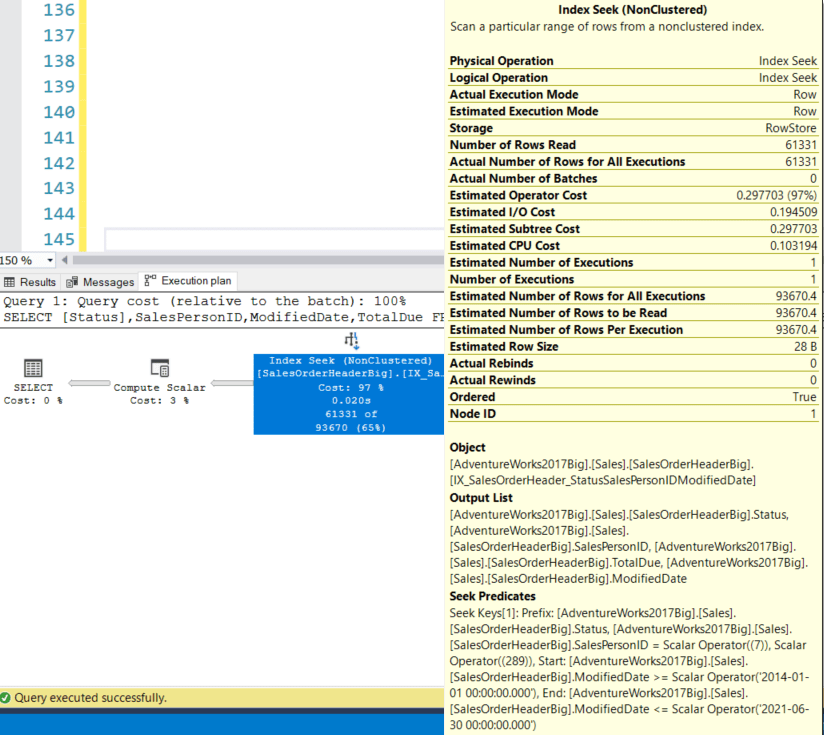
Существенно тот же план, но немного выше показатели времени ЦП, логических чтений и стоимости запроса. Теперь параметрами Seek Predicate являются Status, SalesPersonID и ModifiedDate. Опять же мы поговорим об этом немного позже.
Теперь для полноты картины давайте заставим запрос использовать третий индекс (в определении индекса первый столбец ModifiedDate):
Мы получили тот же результат (58967 строк), но при стоимости запроса 3,43921, ЦП = 118мс, времени выполнения = 535, логических чтениях = 2868 и следующем плане запроса:
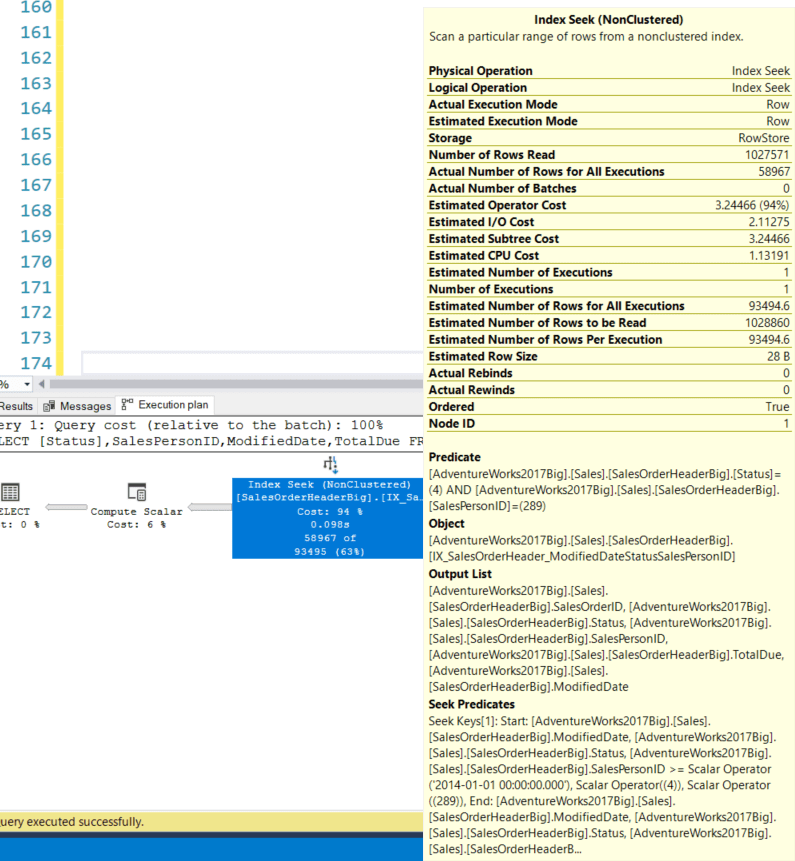
По-прежнему в целом разумная производительность, но теперь в этом плане запроса у нас есть Seek Predicate на ModifiedDate и Predicate на столбцах Status и SalesPersonID. Скачок в логических чтениях вызван тем, как организованы данные в применяемом индексе. Мы увидим это ниже. Но пока все 3 индекса улучшили производительность - просто один больше, чем два других, и это не был предложенный индекс.
Сначала давайте посмотрим на данные, и то, как заполнен каждый столбец. Если выполнить следующий запрос:
мы получим (скриншот части результирующего набора):
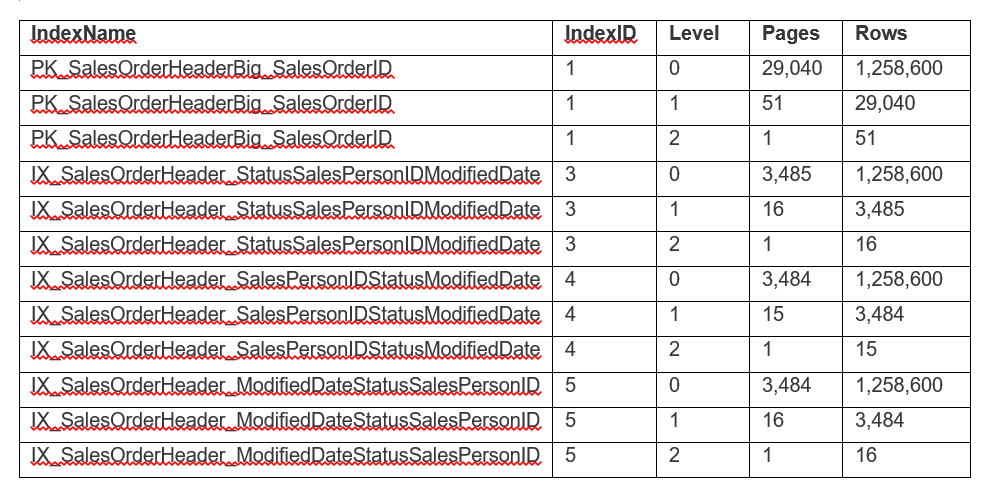
Каждый индекс имеет корневую страницу, один промежуточный уровень и один листовой уровень (данные) при почти равных требованиях к пространству для каждого некластеризованного индекса. Но это не говорит нам о том, как организованы данные внутри каждого индекса.
Давайте рассмотрим, как каждый индекс сортирует данные. Предлагаемый индекс IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate использует первым столбец Status, за которым следуют SalesPersonID и Modified Date. Давайте посмотрим на показанное ниже частичное представление данных, отсортированное каждым индексом:
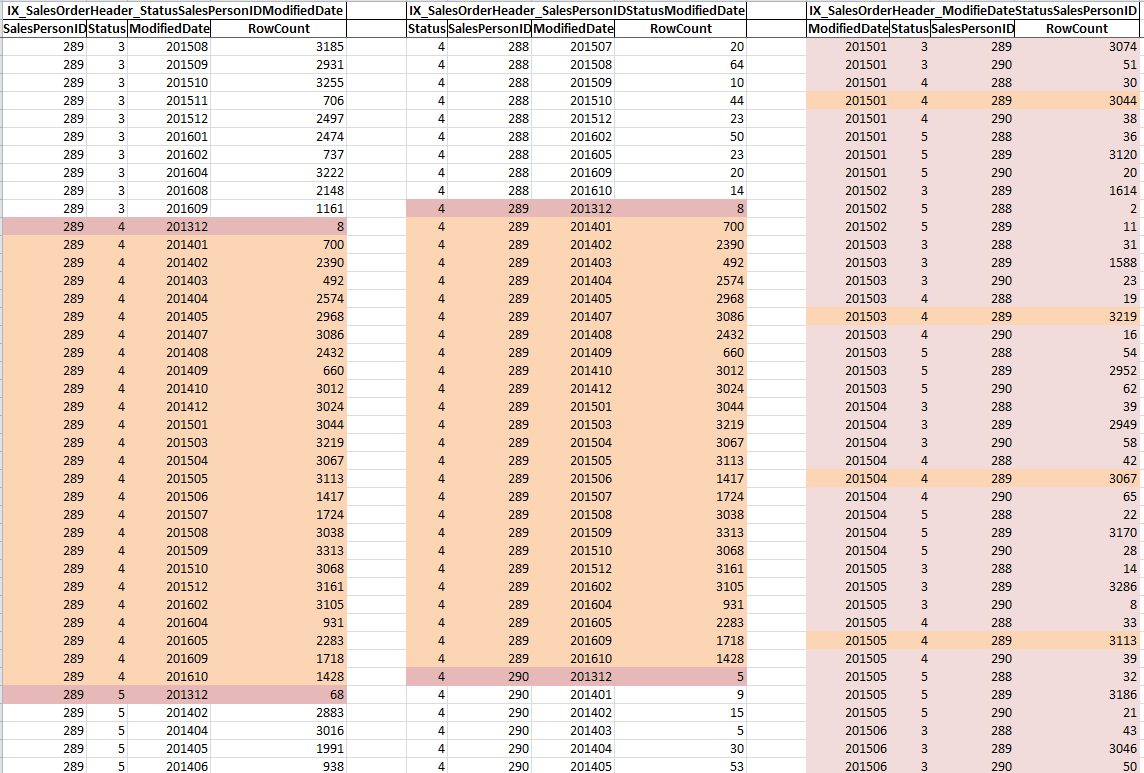
В этом случае, когда задан оператор "=" для Status и SalesPersonID, оптимизатор может сразу перейти к строкам Status = 4 и SalesPersonID = 289, поскольку в определении индекса ModifiedDate является третьим столбцом, и данные уже отсортированы. Поэтому оптимизатор может непосредственно перейти к указанным строкам (это поиск) и вернуть только эти строки (это Seek Predicate), и то же самое применимо к второму индексу IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate. Единственная разница в том, как отсортированы данные на индексных страницах. Обратите внимание, что индекс IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate содержит на одну промежуточную и одну листовую страницу меньше.
Однако, если посмотреть на IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID, можно увидеть, что данные отсортированы по дате, и вам нужно пропустить несколько строк, чтобы перейти к следующим искомым значениям Status и SalesPersonID. Это приводит к значительно большему числу чтений страниц, что видно на ранее представленных результатах.
Хотя я неоднократно слышал, что мастер индексов поддерживает тот же порядок столбцов, что и столбцы в предложении WHERE, использующие оператор равенства, я не могу это доказать, но мне неизвестно и обратное.
Итак, при написании запросов и создании индексов для этих запросов вам необходимо принимать в расчет, какие критерии следует использовать в предложении WHERE запроса. Выбор и порядок столбцов в индексе должен сначала использовать параметры для критериев равенства, а затем, возможно, получить преимущество от упорядочения в соответствии с критериями больше или меньше в предложении WHERE.
В прилагаемом скрипте содержатся все операторы T-SQL из статьи, а также комментарии и большинство результирующих наборов.
Ресурсы: MultiColumnIndexScript.txt
Сценарий
Рассмотрим следующий запрос. Он из AdventureWorks 2017, модифицированный скриптом от Jonathan Kehayias. База данных содержит таблицу Sales.SalesOrderHeader, в которой число строк увеличено с 31465 до 1258600, удалены все некластеризованные индексы и перекошены данные для SalesPersonID = 289 (чтобы иметь больше строк):
SET STATISTICS IO, TIME ON
GO
SELECT [Status],SalesPersonID,ModifiedDate,TotalDue
FROM Sales.SalesOrderHeaderBig
WHERE [Status] = 4
AND SalesPersonID = 289
AND ModifiedDate >= '1/1/2014'
ORDER BY [Status],SalesPersonID,ModifiedDate
GO
SET STATISTICS IO, TIME OFF
GOМы получаем результирующий набор из 58967 строк, 29295 логических чтений, время ЦПУ 588 мс и прошедшее время (ElapsedTime) 584 мс (времена взяты из плана выполнения XML). Интересно, что времена из плана выполнения XML не совпадают с временами из результатов SET STATISTICS ON - интересно, какие из них верные; возможно, разберусь к следующей статье. План выполнения выглядит так:
Этот план содержит сканирование кластеризованного индекса, а стоимость запроса равна 24,4894.
Я также пробовал изменить порядок столбцов в предложении WHERE, но результаты (и план выполнения) оказались идентичными, за исключением порядка столбцов в Predicate, где условия на параметры были в том же порядке, который указывался в предложении WHERE.
План запроса также предлагал отсутствующий покрывающий индекс вида
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate
ON Sales.SalesOrderHeaderBig ([Status] ASC, SalesPersonID ASC, ModifiedDate ASC)
INCLUDE (TotalDue) Заметьте, что столбцы предлагаемого индекса, Status и SalesPersonID, имеют тот же порядок, что и в предложении WHERE. Первые два столбца используют оператор "=", а третий столбец - ">=". Также обратите внимание, что SS2019 параметризует запрос.
Теперь давайте рассмотрим 3 различных индекса (первым является предлагаемый), при этом последние два содержат те же столбцы, что и первый, но в другом порядке.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate
ON Sales.SalesOrderHeaderBig ([Status] ASC, SalesPersonID ASC, ModifiedDate ASC)
INCLUDE (TotalDue)
WITH (Data_Compression = ROW)
GO
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate
ON Sales.SalesOrderHeaderBig (SalesPersonID ASC,[Status] ASC, ModifiedDate ASC)
INCLUDE (TotalDue)
WITH (Data_Compression = ROW)
GO
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID
ON Sales.SalesOrderHeaderBig ( ModifiedDate ASC,[Status] ASC, SalesPersonID ASC)
INCLUDE (TotalDue)
WITH (Data_Compression = ROW)
GOОбратите внимание, что я использую Row Compression (сжатие строк) во всех трех индексах. За мои 12+ лет использования сжатия строк еще не обнаружено их пагубного влияния на производительность, и почти во всех случаях имелось существенное улучшение производительности при уменьшении числа логических чтений (SQL Server 2008 Table Compression (logicalread.com)).
Итак, если вы повторно выполните исходный запрос, мы по-прежнему получим 58967 строк и поиск в некластеризованном индексе, время выполнения ЦП 41 мс, прошедшее время 551 мс, число логических чтений 174, стоимость запроса 0.306444 при следующем плане выполнения:
Теперь мы получаем Seek Predicate (поисковый предикат) на всех трех столбцах индекса, но ПОСТОЙТЕ! План запроса использовал второй индекс (а не предложенный первый): IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate. Хмм, оптимизатор запросов предложил один индекс, а фактическое выполнение использовало совсем другой (переставлены Status и SalesPersonID). Мы еще поговорим об этом ниже, но сначала давайте заставим запрос использовать отсутствующий индекс в исходном запросе:
SELECT [Status],SalesPersonID,ModifiedDate,TotalDue
FROM Sales.SalesOrderHeaderBig
WITH (INDEX (IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate))
WHERE [Status] = 7
AND SalesPersonID = 289
AND ModifiedDate BETWEEN '1/1/2014' AND '6/30/2021'
ORDER BY [Status],SalesPersonID,ModifiedDateМы получаем тот же самый результирующий набор (58967 строк) при ЦП = 42мс, времени выполнения 547, логических чтениях 182 и стоимости запроса 0,30707 в соответствии со следующим планом:
Существенно тот же план, но немного выше показатели времени ЦП, логических чтений и стоимости запроса. Теперь параметрами Seek Predicate являются Status, SalesPersonID и ModifiedDate. Опять же мы поговорим об этом немного позже.
Теперь для полноты картины давайте заставим запрос использовать третий индекс (в определении индекса первый столбец ModifiedDate):
SET STATISTICS IO,TIME ON
GO
SELECT [Status],SalesPersonID,ModifiedDate,TotalDue
FROM Sales.SalesOrderHeaderBig
WITH (INDEX (IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID))
WHERE [Status] = 4
AND SalesPersonID = 289
AND ModifiedDate BETWEEN '1/1/2014' AND '6/30/2021'
ORDER BY [Status],SalesPersonID,ModifiedDate
GO
SET STATISTICS IO,TIME OFF
GOМы получили тот же результат (58967 строк), но при стоимости запроса 3,43921, ЦП = 118мс, времени выполнения = 535, логических чтениях = 2868 и следующем плане запроса:
По-прежнему в целом разумная производительность, но теперь в этом плане запроса у нас есть Seek Predicate на ModifiedDate и Predicate на столбцах Status и SalesPersonID. Скачок в логических чтениях вызван тем, как организованы данные в применяемом индексе. Мы увидим это ниже. Но пока все 3 индекса улучшили производительность - просто один больше, чем два других, и это не был предложенный индекс.
Почему?
Сначала давайте посмотрим на данные, и то, как заполнен каждый столбец. Если выполнить следующий запрос:
dbcc showcontig ('Sales.SalesOrderHeaderBig') with tableresults, all_indexes, all_levels;мы получим (скриншот части результирующего набора):
Каждый индекс имеет корневую страницу, один промежуточный уровень и один листовой уровень (данные) при почти равных требованиях к пространству для каждого некластеризованного индекса. Но это не говорит нам о том, как организованы данные внутри каждого индекса.
Давайте рассмотрим, как каждый индекс сортирует данные. Предлагаемый индекс IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate использует первым столбец Status, за которым следуют SalesPersonID и Modified Date. Давайте посмотрим на показанное ниже частичное представление данных, отсортированное каждым индексом:
В этом случае, когда задан оператор "=" для Status и SalesPersonID, оптимизатор может сразу перейти к строкам Status = 4 и SalesPersonID = 289, поскольку в определении индекса ModifiedDate является третьим столбцом, и данные уже отсортированы. Поэтому оптимизатор может непосредственно перейти к указанным строкам (это поиск) и вернуть только эти строки (это Seek Predicate), и то же самое применимо к второму индексу IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate. Единственная разница в том, как отсортированы данные на индексных страницах. Обратите внимание, что индекс IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate содержит на одну промежуточную и одну листовую страницу меньше.
Однако, если посмотреть на IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID, можно увидеть, что данные отсортированы по дате, и вам нужно пропустить несколько строк, чтобы перейти к следующим искомым значениям Status и SalesPersonID. Это приводит к значительно большему числу чтений страниц, что видно на ранее представленных результатах.
Хотя я неоднократно слышал, что мастер индексов поддерживает тот же порядок столбцов, что и столбцы в предложении WHERE, использующие оператор равенства, я не могу это доказать, но мне неизвестно и обратное.
Заключение
Итак, при написании запросов и создании индексов для этих запросов вам необходимо принимать в расчет, какие критерии следует использовать в предложении WHERE запроса. Выбор и порядок столбцов в индексе должен сначала использовать параметры для критериев равенства, а затем, возможно, получить преимущество от упорядочения в соответствии с критериями больше или меньше в предложении WHERE.
В прилагаемом скрипте содержатся все операторы T-SQL из статьи, а также комментарии и большинство результирующих наборов.
Ресурсы: MultiColumnIndexScript.txt
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой