
Индексы: когда селективность столбца не является обязательным требованием
Пересказ статьи Mike Byrd. Indexes: When Column Selectivity Is Not Always A Requirement
Недавно я столкнулся с одним из устоявшихся убеждений, что первый столбец индекса должен быть высоко селективным, т.е. он должен указывать на одну или незначительное число строк. Это не всегда так, и я покажу вам почему.
В прошлом я неоднократно говорил, что при определении индекса первый столбец должен быть высоко селективным. Я подкреплял это утверждение примером, что "пол" не является в этом смысле хорошим полем данных, т.к. оно не селективно. Данные здесь содержат либо М (мужчина), либо Ж (женщина). Однако давайте рассмотрим очень простой случай, когда пол в первом столбце определения индекса может улучшить производительность запроса.
В аттаче находится скрипт (установка и тестовые примеры), который иллюстрирует, что может произойти при наличии и отсутствии покрывающего индекса, а также каким образом переопределение покрывающего индекса может изменить производительность запроса. Строки 19-41 создают таблицу dbo.Customer в базе TempDB и заполняют её данными из базы данных AdventureWorks2017.
При таким образом определенной таблице рассмотрим следующий запрос (строки 97-106). Я также включаю вывод фактического плана запроса (Ctrl-M):
Возвращается 359 строк. Полная стоимость плана 0,171855 при 217 логических чтениях и сканировании кластеризованного индекса. План запроса выглядит так:
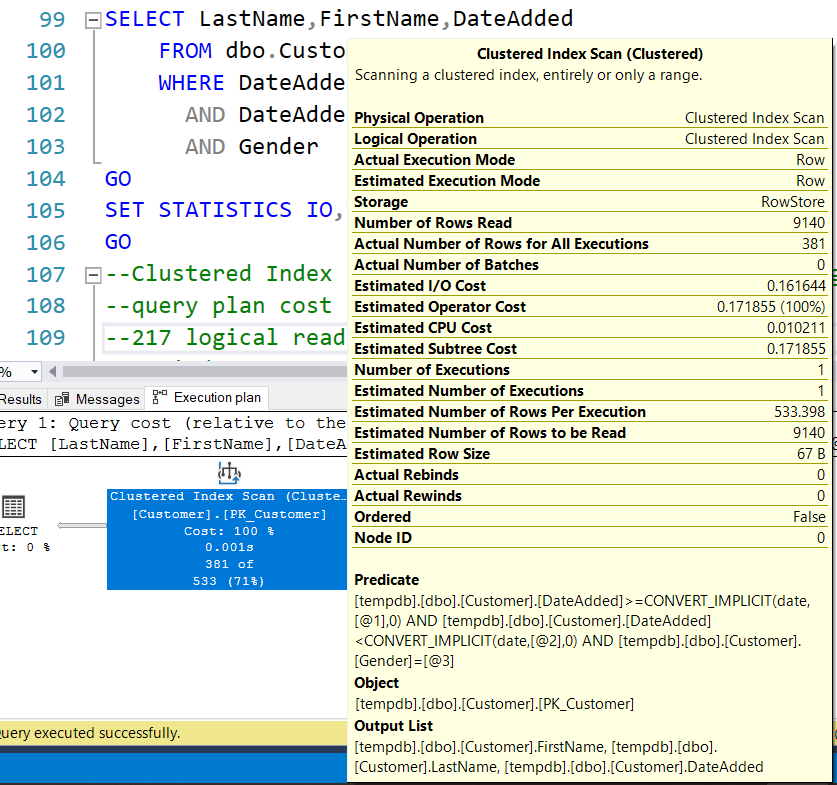
Обратите внимание, что оператор запроса имеет только предикат, выполняющий фильтрацию по DateAdded и Gender. Никаких индексов рекомендовано не было.
Однако, рассматривая запрос, мы можем добавить покрывающий индекс, о чем говорилось выше. Заметьте, что я выбрал первым столбцом столбец даты (т.к. он более селективный, чем столбец Gender).
Теперь, если снова выполнить тот же запрос, мы получим тот же результат, но стоимость запроса составит 0,005594 при 6 логических чтениях и поиске в некластеризованном индексе. План запроса теперь выглядит так:
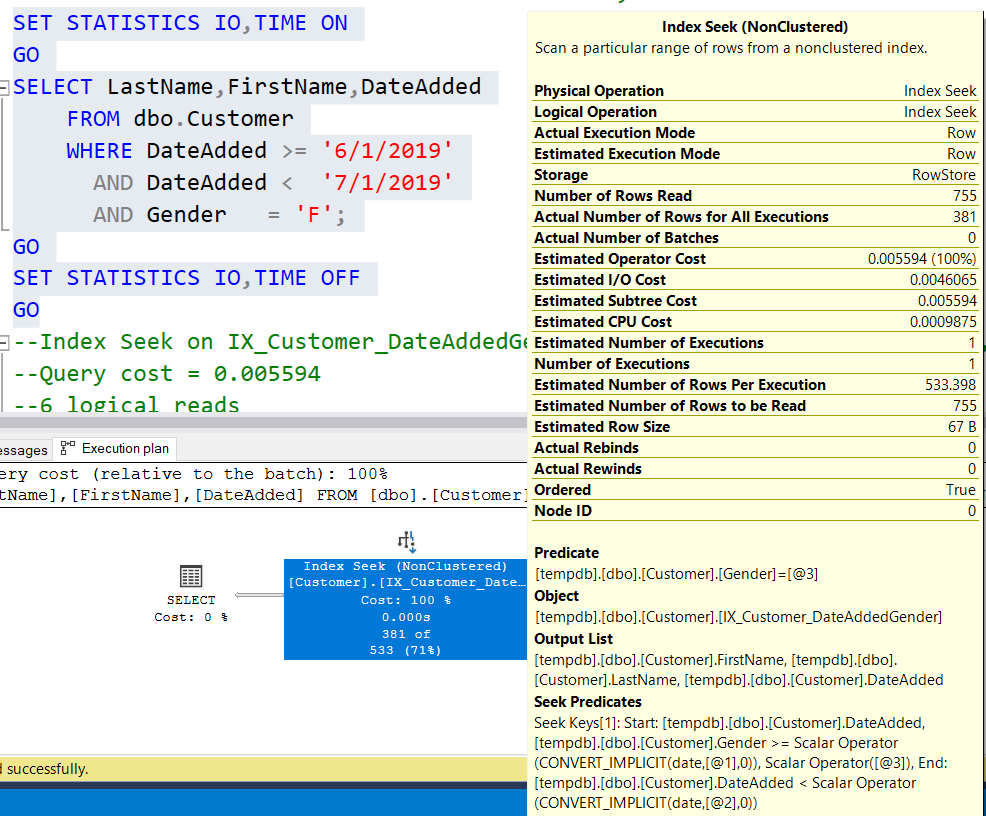
Теперь мы имеем поисковый предикат (Seek Predicate) на DateAdded и фильтрующий предикат на DelFlag при серьезном улучшении стоимости запроса (и меньшем числе логических чтений).
Но мы знаем, что оптимизатор может извлечь преимущество от поиска строк в возрастающем или убывающем порядке. Давайте переопределим покрывающий индекс, как показано ниже:
Перезапустив исходный запрос с этим новым индексом, мы получим стоимость запроса 0,0053502 (немного ниже по сравнению с предыдущим запросом), 4 логических чтения и новый поиск в некластеризованном индексе. Если мы посмотрим план запроса:
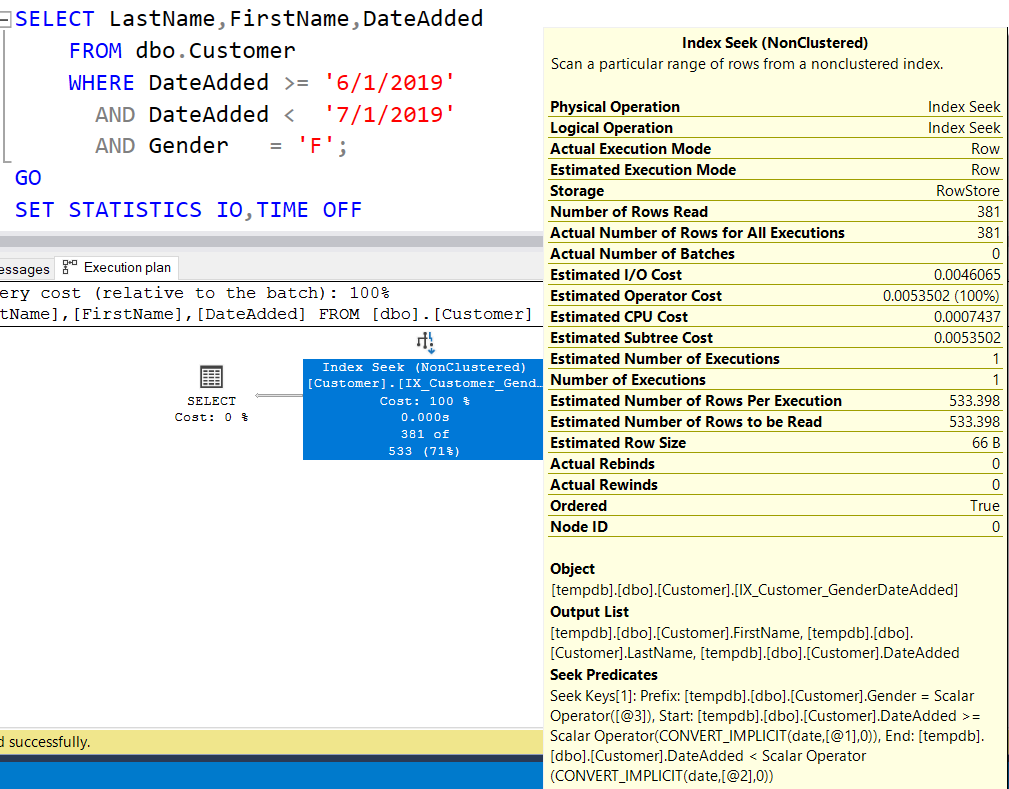
то увидим, что теперь мы имеем и Gender, и DateAdded в поисковом предикате (Seek Predicate), который, наиболее вероятно, и вызвал незначительное уменьшение стоимости запроса.
Если вы подумали о третьем запросе, он имеет Gender первым столбцом, а DateAdded - вторым. В поисковом предикате все строки с Female сгруппированы вместе, а столбец DateAdded упорядочен по возрастанию. Очевидно, что это облегчает оптимизатору запросов перейти непосредственно к надлежащим строкам только за один, а не за два прохода, как в исходном некластеризованном индексе на основе (DateAdded, Gender).
Рассмотренный случай является довольно тривиальным примером, но весьма показательным того, как определение столбцов может влиять на производительность запроса. Таблица Customer в этом примере содержит немногим меньше 10000 строк. Значительно большая таблица при правильных индексах может дать существенную разницу в производительности в рабочем окружении. Я надеюсь, что эта статья даст вам повод задуматься, и эти размышления помогут нам преодолеть пандемию.
В аттаче находится скрипт (установка и тестовые примеры), который иллюстрирует, что может произойти при наличии и отсутствии покрывающего индекса, а также каким образом переопределение покрывающего индекса может изменить производительность запроса. Строки 19-41 создают таблицу dbo.Customer в базе TempDB и заполняют её данными из базы данных AdventureWorks2017.
При таким образом определенной таблице рассмотрим следующий запрос (строки 97-106). Я также включаю вывод фактического плана запроса (Ctrl-M):
SET STATISTICS IO, TIME ON
GO
SELECT LastName,FirstName,DateAdded
FROM dbo.Customer
WHERE DateAdded >= '6/1/2019'
AND DateAdded < '7/1/2019'
AND Gender = 'F';
GO
SET STATISTICS IO, TIME OFF
GOВозвращается 359 строк. Полная стоимость плана 0,171855 при 217 логических чтениях и сканировании кластеризованного индекса. План запроса выглядит так:
Обратите внимание, что оператор запроса имеет только предикат, выполняющий фильтрацию по DateAdded и Gender. Никаких индексов рекомендовано не было.
Однако, рассматривая запрос, мы можем добавить покрывающий индекс, о чем говорилось выше. Заметьте, что я выбрал первым столбцом столбец даты (т.к. он более селективный, чем столбец Gender).
CREATE INDEX IX_Customer_DateAddedGender ON dbo.Customer
(DateAdded ASC, Gender ASC)
INCLUDE (LastName,FirstName)Теперь, если снова выполнить тот же запрос, мы получим тот же результат, но стоимость запроса составит 0,005594 при 6 логических чтениях и поиске в некластеризованном индексе. План запроса теперь выглядит так:
Теперь мы имеем поисковый предикат (Seek Predicate) на DateAdded и фильтрующий предикат на DelFlag при серьезном улучшении стоимости запроса (и меньшем числе логических чтений).
Но мы знаем, что оптимизатор может извлечь преимущество от поиска строк в возрастающем или убывающем порядке. Давайте переопределим покрывающий индекс, как показано ниже:
DROP INDEX IX_Customer_DateAddedGender ON dbo.Customer
CREATE INDEX IX_Customer_GenderDateAdded ON dbo.Customer
(Gender ASC, DateAdded ASC)
INCLUDE (LastName,FirstName)Перезапустив исходный запрос с этим новым индексом, мы получим стоимость запроса 0,0053502 (немного ниже по сравнению с предыдущим запросом), 4 логических чтения и новый поиск в некластеризованном индексе. Если мы посмотрим план запроса:
то увидим, что теперь мы имеем и Gender, и DateAdded в поисковом предикате (Seek Predicate), который, наиболее вероятно, и вызвал незначительное уменьшение стоимости запроса.
Если вы подумали о третьем запросе, он имеет Gender первым столбцом, а DateAdded - вторым. В поисковом предикате все строки с Female сгруппированы вместе, а столбец DateAdded упорядочен по возрастанию. Очевидно, что это облегчает оптимизатору запросов перейти непосредственно к надлежащим строкам только за один, а не за два прохода, как в исходном некластеризованном индексе на основе (DateAdded, Gender).
Заключение
Рассмотренный случай является довольно тривиальным примером, но весьма показательным того, как определение столбцов может влиять на производительность запроса. Таблица Customer в этом примере содержит немногим меньше 10000 строк. Значительно большая таблица при правильных индексах может дать существенную разницу в производительности в рабочем окружении. Я надеюсь, что эта статья даст вам повод задуматься, и эти размышления помогут нам преодолеть пандемию.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой