
Чем отличается LAG от других методов
Пересказ статьи Kathi Kellenberger. How LAG compares to other techniques
Первые оконные функции появились у Microsoft в SQL Server 2005. Это были ROW_NUMBER, RANK, DENSE_RANK, NTILE и оконные агрегаты. Многие, включая и меня, использовали эти функции, не осознавая, что они являются частью особой группы. В 2012 Microsoft добавила еще несколько: LAG и LEAD, FIRST_VALUE и LAST_VALUE, PERCENT_RANK и CUME_DIST, PERCENTILE_CONT и PERCENTILE_DISC. Также появилась возможность получать накопительные итоги и выполнять скользящие вычисления.
Эти функции продвигались как средство улучшения производительности по сравнению со старыми методами, однако это не всегда так. Все еще существовали проблемы производительности, связанные с агрегатными функциями, введенными в 2005, и четырьмя функциями, введенными в 2012. В 2019 Microsoft ввела пакетный режим на построчном хранилище, доступный для Enterprise и Developer Editions, который может улучшить производительность оконных агрегатов и четырех статистических функций из 2012.
Я начинала писать эту статью для сравнения некоторых решений на базе оконных функций с традиционными решениями. Я обнаружила, что существует так много способов написать запрос, который включает столбец из другой строки, что эта статья свелась к оконным функциям LAG и LEAD.
Включение столбца из другой строки обычно означает некое самосоединение. Подчас этот код трудно написать, и он не очень хорошо работает. Функция LAG может использоваться для того, чтобы вытащить предыдущую строку без самосоединения. При наличии адекватных индексов использование LAG решает эти проблемы. LEAD работает аналогично LAG, за исключением того, что берется последующая строка.
Вот пример использования LAG на базе данных AdventureWorks:
Запрос возвращает список товаров и даты, когда они были заказаны. Он использует функцию DATEDIFF для сравнения даты текущего заказа с датой предыдущего заказа, определяемой с помощью LAG. Предложение OVER для LAG требует предложения ORDER BY. Здесь порядок задается OrderDate, поскольку именно так должны быть выстроены строки, чтобы находить предыдущую дату. На рис.1 показан фрагмент результата.
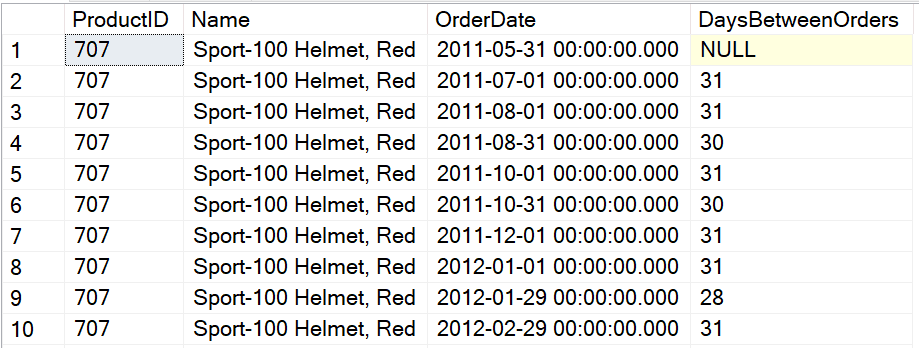
Рис.1. Фрагмент результатов выполнения запроса, использующего LAG
Время выполнения запроса менее секунды, около 300 мс, и требует только 365 логических чтений, что показано на рис.2.

Рис.2. Логические чтения запроса с LAG
Я пробовала несколько методов, чтобы посмотреть, можно ли написать запрос, который бы выполнялся лучше без использования LAG. Хотя база данных невелика, выполнение запросов требовало некоторого времени в зависимости от метода.
Метод самосоединения болезненно медленный. Сохранение первой строки заказа каждого товара в результатах требует LEFT JOIN, и это было настолько медленно, что я убила запрос спустя несколько минут. Вместо этого следующий запрос пропускает строку NULL для каждого продукта.
Запрос выполнился за 20 секунд и имел 3103 логических чтения, как показано на рис.3.

Рис.3. Логические чтения запроса с самосоединением
Запрос использует функцию MAX для нахождения предыдущей OrderDate и фильтрацию для нахождения строк в SOH2 с OrderDate меньше чем OrderDate в SOD.
Можно ли улучшить производительность самосоединения при помощи производной таблицы? Вот запрос, чтобы выяснить это:
Я была удивлена, обнаружив, что этот запрос отработал за 2 секунды, несмотря на то, что логических чтений было намного больше!

Рис.4. Логические чтения запроса с производной таблицей
Это весьма хорошо, хотя и не так, как для запроса с LAG.
Еще один способ решить задачу - это запрос с общим табличным выражением (CTE):
Этот запрос также выполняется за 2 секунды с тем же числом логических чтений, что и для производной таблицы. Что тут происходит? CTE не сохраняет результаты для повторного использования - обращение к таблицам происходит дважды - но соединения и некоторые другие операторы отличаются. Оптимизатор смог найти лучшие планы, используя производные таблицы или CTE.
Оператор APPLY часто используется для улучшения производительности запросов. Имеется два варианта: CROSS APPLY и OUTER APPLY, аналоги JOIN и LEFT JOIN. Оператор APPLY может использоваться для решения многих интересных запросов, и в этом случае OUTER APPLY заменяет LEFT JOIN.
Этот запрос выполнялся 12 секунд и имел колоссальное число логических чтений - 86,281,577!

Рис.5. Логические чтения запроса с OUTER APPLY
В этом сценарии OUTER APPLY действует подобно вызову функции по разу для каждой строки во внешнем запросе, чего, вероятно, не было бы, если бы не использовался оператор «меньше».
Можно использовать TOP(1) вместо MAX, но тогда запрос внутри OUTER APPLY также должен быть упорядочен, и результаты не станут лучше.
Поскольку любой из методов требует уникального списка ProductID, Name, OrderDate, эти строки можно сохранить во временной таблице.
Временная таблица существенно улучшила время - 1,4 секунды. К реальным таблицам обращение выполнялось один раз - при создании временной таблицы. затем временная таблица дважды сканировалась и соединялась методом вложенных циклов.

Рис.6. Часть плана выполнения при использовании временной таблицы
Добавление индекса для временной таблицы может еще больше улучшить производительность. Этот скрипт выполнялся примерно 700 мс.
Самосоединение тоже улучшилось при использовании временной таблицы, возвращая результат только за 3 секунды даже при использовании LEFT JOIN, что было невозможно ранее.
Производительность пользовательских скалярнозначных функций была улучшена в 2019 при помощи встраивания (inlining). Я надеялась, что производительность не будет слишком плохой, поскольку у меня запущена версия SQL Server 2019. К сожалению, оператор "меньше" (<) убивает производительность. Даже добавление индекса на OrderDate не слишком помогает. Я убила запрос после 25 секунд выполнения.
Поскольку я убила запрос до его завершения, я не уверена, сколько он мог бы выполняться. План выполнения выглядит достаточно простым, но он не показывает, что функция вызывалась много раз.

Рис.7. План выполнения для скалярной UDF
Я часто слышала, как говорят: "Просто преобразуйте это в табличнозначную функцию", - когда возникают проблемы с UDF. Однако все еще возможно сделать "плохие вещи" также и с табличнозначными функциями. Существует два типа табличнозначных функций: многооператорная и встаиваемая (inline). Многооператорные табличнозначные функции (MSTVF) могут иметь циклы, блоки IF и табличные переменные, поэтому они плохо масштабируются.
Встраиваемые табличнозначные функции (ITVF) допускают только единственный запрос. Конечно, функция может содержать плохо написанный запрос, но в целом они обеспечивают лучшую производительность. Однако в этом случае производительность все же не так хороша, как при использовании LAG. Заметим, что вызов ITVF также использует OUTER APPLY.
ITVF занимает около 12 секунд на выполнение и свыше 59 миллионов логических чтений при использовании временной таблицы.

Рис.8. Логические чтения для ITVF
Были дебаты, стоит ли включать раздел, посвященный курсорам, поскольку я не хотела провоцировать кого-либо начинать с решения на базе курсора. Однако я вспомнила другую ситуацию, когда решение с курсором выполнялось быстрей по сравнению с другими методами. В результате я включила этот раздел. Курсоры - это еще один инструмент в вашем арсенале T-SQL. Они могут лежать на дне ящика и немного заржаветь от редкого использования, но, тем не менее, это инструмент.
Необходимо отметить, что при выполнении решения с курсором важно выключить вывод фактического плана выполнения (или других методов, которые вы можете использовать для захвата плана выполнения) и статистики. С этим отключением скрипт выполняется примерно за 2 секунды!
Вероятно, существует даже больше способов написать запрос (как кто-то на презентации настаивал, что представление будет всегда опережать LAG), но маловероятно, чтобы другие методы работали быстрее LAG, когда вам нужен столбец из предыдущей строки. Вот результаты для каждого метода:
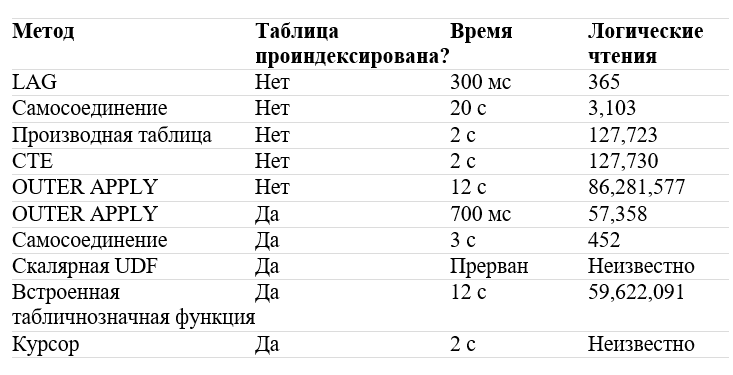
Когда OUTER APPLY работает с предварительно агрегированной временной таблицей, он выполняется почти так же хорошо, как и LAG. В противном случае, другие методы выполняются за 2 секунды или более.
Для этой конкретной задачи производительность LAG является наилучшей. Урок, который следует извлечь отсюда, заключается в том, что имеется много способов написать запрос, поэтому пробуйте разные методы, если вы испытываете проблемы с производительностью.
Я начинала писать эту статью для сравнения некоторых решений на базе оконных функций с традиционными решениями. Я обнаружила, что существует так много способов написать запрос, который включает столбец из другой строки, что эта статья свелась к оконным функциям LAG и LEAD.
Включить столбец из другой строки с помощью LAG
Включение столбца из другой строки обычно означает некое самосоединение. Подчас этот код трудно написать, и он не очень хорошо работает. Функция LAG может использоваться для того, чтобы вытащить предыдущую строку без самосоединения. При наличии адекватных индексов использование LAG решает эти проблемы. LEAD работает аналогично LAG, за исключением того, что берется последующая строка.
Вот пример использования LAG на базе данных AdventureWorks:
SET STATISTICS IO, TIME ON;
--LAG
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate,
DATEDIFF(DAY, LAG(SOH.OrderDate)
OVER(PARTITION BY PROD.ProductID
ORDER BY SOH.OrderDate),SOH.OrderDate) AS DaysBetweenOrders
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY PROD.ProductID, PROD.Name, SOH.OrderDate
ORDER BY PROD.ProductID, SOH.OrderDate;Запрос возвращает список товаров и даты, когда они были заказаны. Он использует функцию DATEDIFF для сравнения даты текущего заказа с датой предыдущего заказа, определяемой с помощью LAG. Предложение OVER для LAG требует предложения ORDER BY. Здесь порядок задается OrderDate, поскольку именно так должны быть выстроены строки, чтобы находить предыдущую дату. На рис.1 показан фрагмент результата.
Рис.1. Фрагмент результатов выполнения запроса, использующего LAG
Время выполнения запроса менее секунды, около 300 мс, и требует только 365 логических чтений, что показано на рис.2.
Рис.2. Логические чтения запроса с LAG
Я пробовала несколько методов, чтобы посмотреть, можно ли написать запрос, который бы выполнялся лучше без использования LAG. Хотя база данных невелика, выполнение запросов требовало некоторого времени в зависимости от метода.
Сомосоединение
Метод самосоединения болезненно медленный. Сохранение первой строки заказа каждого товара в результатах требует LEFT JOIN, и это было настолько медленно, что я убила запрос спустя несколько минут. Вместо этого следующий запрос пропускает строку NULL для каждого продукта.
--Самосоединение
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate,
DATEDIFF(DAY, MAX(SOH2.OrderDate), SOH.OrderDate) AS DaysBetweenOrders
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
JOIN Sales.SalesOrderDetail AS SOD2
ON SOD2.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH2
ON SOH2.SalesOrderID = SOD2.SalesOrderID
WHERE SOH2.OrderDate < SOH.OrderDate
GROUP BY PROD.ProductID
, PROD.Name
, SOH.OrderDate
, SOD2.ProductID
ORDER BY PROD.ProductID, SOH.OrderDate;Запрос выполнился за 20 секунд и имел 3103 логических чтения, как показано на рис.3.
Рис.3. Логические чтения запроса с самосоединением
Запрос использует функцию MAX для нахождения предыдущей OrderDate и фильтрацию для нахождения строк в SOH2 с OrderDate меньше чем OrderDate в SOD.
Производная таблица
Можно ли улучшить производительность самосоединения при помощи производной таблицы? Вот запрос, чтобы выяснить это:
--Производные таблицы
SELECT S1.ProductID, S1.Name, S1.OrderDate,
DATEDIFF(DAY,MAX(S2.OrderDate),S1.OrderDate) AS DaysBetweenOrders
FROM
(SELECT Prod.ProductID, Prod.Name, SOH.OrderDate
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY PROD.ProductID
, PROD.Name
, SOH.OrderDate
) AS S1
LEFT JOIN (
SELECT SOD.ProductID, SOH.OrderDate
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY SOD.ProductID
, SOH.OrderDate
) AS S2
ON S2.ProductID = S1.ProductID AND S1.OrderDate > S2.OrderDate
GROUP BY S1.ProductID
, S1.Name
, S1.OrderDate
ORDER BY S1.ProductID, S1.OrderDate;Я была удивлена, обнаружив, что этот запрос отработал за 2 секунды, несмотря на то, что логических чтений было намного больше!
Рис.4. Логические чтения запроса с производной таблицей
Это весьма хорошо, хотя и не так, как для запроса с LAG.
Общее табличное выражение
Еще один способ решить задачу - это запрос с общим табличным выражением (CTE):
--CTE
WITH Products AS (
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY PROD.ProductID, PROD.Name, SOH.OrderDate
)
SELECT P1.ProductID, P1.Name, P1.OrderDate,
DATEDIFF(DAY, MAX(P2.OrderDate), P1.OrderDate) AS DaysBetweenOrders
FROM Products P1
LEFT JOIN Products P2
ON P2.ProductID = P1.ProductID
WHERE P1.OrderDate > P2.OrderDate
GROUP BY P1.ProductID, P1.Name, P1.OrderDate;Этот запрос также выполняется за 2 секунды с тем же числом логических чтений, что и для производной таблицы. Что тут происходит? CTE не сохраняет результаты для повторного использования - обращение к таблицам происходит дважды - но соединения и некоторые другие операторы отличаются. Оптимизатор смог найти лучшие планы, используя производные таблицы или CTE.
OUTER APPLY
Оператор APPLY часто используется для улучшения производительности запросов. Имеется два варианта: CROSS APPLY и OUTER APPLY, аналоги JOIN и LEFT JOIN. Оператор APPLY может использоваться для решения многих интересных запросов, и в этом случае OUTER APPLY заменяет LEFT JOIN.
--OUTER APPLY
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate,
DATEDIFF(DAY, S2.PrevOrderDate, SOH.OrderDate) AS DaysBetweenOrders
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
OUTER APPLY (
SELECT MAX(SOH2.OrderDate) AS PrevOrderDate
FROM Sales.SalesOrderDetail AS SOD2
JOIN Sales.SalesOrderHeader AS SOH2
ON SOH2.SalesOrderID = SOD2.SalesOrderID
WHERE SOD2.ProductID = PROD.ProductID
AND SOH2.OrderDate < SOH.OrderDate) S2
GROUP BY DATEDIFF(DAY, S2.PrevOrderDate, SOH.OrderDate)
, PROD.ProductID
, PROD.Name
, SOH.OrderDate
ORDER BY PROD.ProductID, SOH.OrderDate;
Этот запрос выполнялся 12 секунд и имел колоссальное число логических чтений - 86,281,577!
Рис.5. Логические чтения запроса с OUTER APPLY
В этом сценарии OUTER APPLY действует подобно вызову функции по разу для каждой строки во внешнем запросе, чего, вероятно, не было бы, если бы не использовался оператор «меньше».
Можно использовать TOP(1) вместо MAX, но тогда запрос внутри OUTER APPLY также должен быть упорядочен, и результаты не станут лучше.
Временная таблица
Поскольку любой из методов требует уникального списка ProductID, Name, OrderDate, эти строки можно сохранить во временной таблице.
--OUTER APPLY with Temp table
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList PL
OUTER APPLY (
SELECT MAX(PL1.OrderDate) AS OrderDate
FROM #ProductList AS PL1
WHERE PL1.ProductID = PL.ProductID
AND PL1.OrderDate < PL.OrderDate
) AS PrevOrder
GROUP BY DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate)
, PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;Временная таблица существенно улучшила время - 1,4 секунды. К реальным таблицам обращение выполнялось один раз - при создании временной таблицы. затем временная таблица дважды сканировалась и соединялась методом вложенных циклов.
Рис.6. Часть плана выполнения при использовании временной таблицы
Добавление индекса для временной таблицы может еще больше улучшить производительность. Этот скрипт выполнялся примерно 700 мс.
--Индексированная временная таблица и OUTER APPLY
CREATE CLUSTERED INDEX IDX_ProductList ON #ProductList
(ProductID, OrderDate);
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList PL
OUTER APPLY (
SELECT MAX(PL1.OrderDate) AS OrderDate
FROM #ProductList AS PL1
WHERE PL1.ProductID = PL.ProductID
AND PL1.OrderDate < PL.OrderDate
) AS PrevOrder
GROUP BY DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate)
, PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;Самосоединение тоже улучшилось при использовании временной таблицы, возвращая результат только за 3 секунды даже при использовании LEFT JOIN, что было невозможно ранее.
--Самосоединение с временной таблицей
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY, MAX(PL2.OrderDate), PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList AS PL
LEFT JOIN #ProductList AS PL2
ON PL2.ProductID = PL.ProductID AND PL.OrderDate > PL2.OrderDate
GROUP BY PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;Скалярная пользовательская функция
Производительность пользовательских скалярнозначных функций была улучшена в 2019 при помощи встраивания (inlining). Я надеялась, что производительность не будет слишком плохой, поскольку у меня запущена версия SQL Server 2019. К сожалению, оператор "меньше" (<) убивает производительность. Даже добавление индекса на OrderDate не слишком помогает. Я убила запрос после 25 секунд выполнения.
--Скалярная UDF
GO
CREATE OR ALTER FUNCTION [dbo].[GetPreviousOrderDate]
(
@ProductID INT, @OrderDate DATETIME
)
RETURNS DATETIME
AS
BEGIN
DECLARE @PrevOrderDate DATETIME;
SELECT @PrevOrderDate = MAX(OrderDate)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOD.ProductID = @ProductID AND SOH.OrderDate < @OrderDate;
-- Возвращает результат функции
RETURN @PrevOrderDate;
END;
GO
CREATE INDEX test_index ON Sales.SalesOrderHeader (OrderDate);
GO
--Вызов функции
SELECT PL.ProductID, PL.Name, PL.OrderDate,
dbo.GetPreviousOrderDate(PL.ProductID, PL.OrderDate)
FROM #ProductList AS PL
GROUP BY PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;Поскольку я убила запрос до его завершения, я не уверена, сколько он мог бы выполняться. План выполнения выглядит достаточно простым, но он не показывает, что функция вызывалась много раз.
Рис.7. План выполнения для скалярной UDF
Табличнозначные функции
Я часто слышала, как говорят: "Просто преобразуйте это в табличнозначную функцию", - когда возникают проблемы с UDF. Однако все еще возможно сделать "плохие вещи" также и с табличнозначными функциями. Существует два типа табличнозначных функций: многооператорная и встаиваемая (inline). Многооператорные табличнозначные функции (MSTVF) могут иметь циклы, блоки IF и табличные переменные, поэтому они плохо масштабируются.
Встраиваемые табличнозначные функции (ITVF) допускают только единственный запрос. Конечно, функция может содержать плохо написанный запрос, но в целом они обеспечивают лучшую производительность. Однако в этом случае производительность все же не так хороша, как при использовании LAG. Заметим, что вызов ITVF также использует OUTER APPLY.
--Встраиваемая табличнозначная функция
GO
CREATE OR ALTER FUNCTION dbo.ITVF_GetPrevDate
(
@ProductID INT, @OrderDate DATETIME
)
RETURNS TABLE
AS
RETURN
(
-- Добавьте сюда оператор SELECT со ссылками на параметры
SELECT MAX(SOH.OrderDate) AS PrevOrderDate
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOD.ProductID = @ProductID
AND SOH.OrderDate < @OrderDate
)
GO
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY,IGPD.PrevOrderDate,PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList AS PL
OUTER APPLY [dbo].[ITVF_GetPrevDate] (PL.ProductID,PL.OrderDate) IGPD
ORDER BY PL.ProductID, PL.OrderDate;ITVF занимает около 12 секунд на выполнение и свыше 59 миллионов логических чтений при использовании временной таблицы.
Рис.8. Логические чтения для ITVF
Курсор
Были дебаты, стоит ли включать раздел, посвященный курсорам, поскольку я не хотела провоцировать кого-либо начинать с решения на базе курсора. Однако я вспомнила другую ситуацию, когда решение с курсором выполнялось быстрей по сравнению с другими методами. В результате я включила этот раздел. Курсоры - это еще один инструмент в вашем арсенале T-SQL. Они могут лежать на дне ящика и немного заржаветь от редкого использования, но, тем не менее, это инструмент.
Необходимо отметить, что при выполнении решения с курсором важно выключить вывод фактического плана выполнения (или других методов, которые вы можете использовать для захвата плана выполнения) и статистики. С этим отключением скрипт выполняется примерно за 2 секунды!
--Курсор
--Важно! Также отключите фактический план выполнения (Actual Execution Plan)
SET STATISTICS IO, TIME OFF
GO
ALTER TABLE #ProductList
ADD DaysBetweenOrders INT;
GO
DECLARE @LastProductID INT, @ProductID INT;
DECLARE @LastOrderDate DATETIME, @OrderDate DATETIME;
DECLARE @DaysBetweenOrders INT;
DECLARE Products CURSOR FAST_FORWARD FOR
SELECT p.ProductID, P.OrderDate
FROM #ProductList AS P
ORDER BY p.ProductID, P.OrderDate
;
OPEN Products;
FETCH NEXT FROM Products INTO @ProductID, @OrderDate;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @LastProductID = @ProductID BEGIN
SET @DaysBetweenOrders = DATEDIFF(DAY,@LastOrderDate,@OrderDate);
UPDATE #ProductList SET DaysBetweenOrders = @DaysBetweenOrders
WHERE ProductID = @ProductID AND OrderDate =@OrderDate;
END;
SELECT @LastOrderDate = @OrderDate, @LastProductID = @ProductID;
FETCH NEXT FROM Products INTO @ProductID, @OrderDate;
END
CLOSE Products;
DEALLOCATE Products;
SELECT P.ProductID
, P.Name
, P.OrderDate
, P.DaysBetweenOrders
FROM #ProductList AS P
ORDER BY P.ProductID, P.OrderDate;Сравнение LAG с другими методами
Вероятно, существует даже больше способов написать запрос (как кто-то на презентации настаивал, что представление будет всегда опережать LAG), но маловероятно, чтобы другие методы работали быстрее LAG, когда вам нужен столбец из предыдущей строки. Вот результаты для каждого метода:
Когда OUTER APPLY работает с предварительно агрегированной временной таблицей, он выполняется почти так же хорошо, как и LAG. В противном случае, другие методы выполняются за 2 секунды или более.
Для этой конкретной задачи производительность LAG является наилучшей. Урок, который следует извлечь отсюда, заключается в том, что имеется много способов написать запрос, поэтому пробуйте разные методы, если вы испытываете проблемы с производительностью.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой