
Что нового в SQL Server 2019: Более быстрые функции
Пересказ статьи Brent Ozar. What’s New in SQL Server 2019 CTP 2.1: Faster Functions
Некоторое время назад мы обсуждали официальную публикацию о том, как Майкрософт работала над ускорением выполнения пользовательских функций. Теперь, когда вышла следующая предварительная версия (CTP 2.1) SQL Server 2019, вы можете познакомиться с тем, как достигается рост производительности (документация). Давайте посмотрим, как это работает.
Будем использовать базу данных StackOverflow2010. Пусть наша компания имеет скалярную пользовательскую функцию, которая вычисляет, сколько значков (бейджей) заработал пользователь:
Раньше производительность этой функции была отстойной. Если я ограничусь 1000 пользователей, и вызову функцию для подсчета количества их бейджей:
план выполнения выглядит просто:
Но вот что действительно ужасно:
Метрики:
Моя база данных должна быть в режиме совместимости с 2019, чтобы иметь доступ к магии встраивания функций. Запустите тот же запрос снова, и метрики станут резко отличаться:
План выполнения выглядит хуже:
Вероятно, вашей первой мыслью было: "Мать природа, этот план выглядит более тяжелым", но главное здесь то, что он теперь показывает ту работу, которая заключена в функции. Прежде вы должны были использовать инструменты типа sp_BlitzCache, чтобы выяснить, какие функции вызывались, и насколько часто.
Теперь вы можете видеть, что SQL Server строит спул, или, как любит говорить Эрик, пассивно-агрессивное построение своего собственного отсутствующего индекса на лету, не беспокоя вас сообщениями о необходимости его создания (заметим, что в плане нет запроса пропущенного индекса):
Великолепно! Это означает, что я могу легко пофиксить проблему, просто сделав настройку индекса. Дополнительно я должен знать, как сделать этот уровень настройки индекса, но это - кусок пирога, когда внезапно план с очевидностью показывает то, что он реально делает.
В документации перечисляется множество конструкций T-SQL, которые могут или не могут встраиваться:
Но чтение этого потребует от вас открытия кода и в ваших пользовательских функциях, и это одна из главных причин профессионального самоубийства. А я не хочу лишить читателей.
Вместо этого загрузим предварительный выпуск SQL Server 2019, установим его на тестовую VM, восстановим туда вашу базу данных и выполним:
Новый столбец is_inlineable скажет вам, которая из ваших функций может встраиваться:
Затем, чтобы узнать, какая из ваших функций вызывается наиболее часто на рабочем сервере, используйте sp_BlitzCache:
Проведите их инвентаризацию, и пока вы там смотрите на функции, попробуйте выполнить сортировку по CPU, Reads или Memory Grant как альтернативу. Ищите табличные переменные, большое выделение памяти, или малое выделение, которое приводит к ее утечке, поскольку SQL Server 2019 улучшил и это тоже.
Это позволит вам построить бизнес-модель обслуживания. Вы сможете объяснить, какие из ваших запросов могут волшебным образом ускориться после апгрейда, и какое влияние на ваш SQL Server это окажет в целом без изменения кода. Это особенно ценно для приложений третьих сторон, когда вы не можете менять код, но требуется поднять производительность.
CREATE OR ALTER FUNCTION dbo.ScalarFunction ( @uid INT )
RETURNS BIGINT
WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING
AS
BEGIN
DECLARE @BCount BIGINT;
SELECT @BCount = COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = @uid
GROUP BY b.UserId;
RETURN @BCount;
END;
GO
Раньше производительность этой функции была отстойной. Если я ограничусь 1000 пользователей, и вызову функцию для подсчета количества их бейджей:
SELECT TOP 1000
u.DisplayName,
dbo.ScalarFunction(u.Id)
FROM dbo.Users AS u
GO
план выполнения выглядит просто:
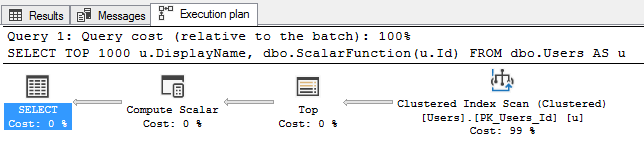 План 2017 скрывает работу со скалярами
План 2017 скрывает работу со скалярами
Но вот что действительно ужасно:
- Он не показывает всего, что делает скалярная функция.
- Он сильно занижает сделанную работу (скаляры имеют фиксированную крошечную стоимость, не зависящую от проделанной работы).
- Он не показывает логические чтения, выполненные функцией.
- И, конечно, он вызывает эту функцию 1000 раз - по разу на каждого возвращаемого пользователя.
Метрики:
- Время выполнения: 17 секунд.
- Время CPU: 56 секунд.
- Логические чтения: 6643089.
Давайте теперь проверим в SQL Server 2019
Моя база данных должна быть в режиме совместимости с 2019, чтобы иметь доступ к магии встраивания функций. Запустите тот же запрос снова, и метрики станут резко отличаться:
- Время выполнения: 4 секунды.
- Время CPU: 4 секунды.
- Логические чтения: 3247991 (все еще плохо, но по мне терпимо).
План выполнения выглядит хуже:
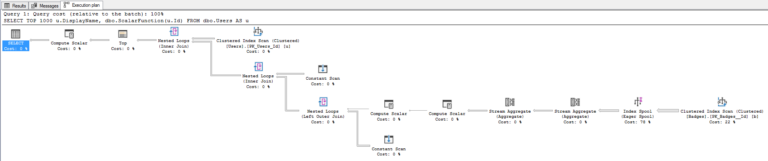 План 2019 демонстрирует ужасы встроенной функции
План 2019 демонстрирует ужасы встроенной функции
Вероятно, вашей первой мыслью было: "Мать природа, этот план выглядит более тяжелым", но главное здесь то, что он теперь показывает ту работу, которая заключена в функции. Прежде вы должны были использовать инструменты типа sp_BlitzCache, чтобы выяснить, какие функции вызывались, и насколько часто.
Теперь вы можете видеть, что SQL Server строит спул, или, как любит говорить Эрик, пассивно-агрессивное построение своего собственного отсутствующего индекса на лету, не беспокоя вас сообщениями о необходимости его создания (заметим, что в плане нет запроса пропущенного индекса):
 Спул
Спул
Великолепно! Это означает, что я могу легко пофиксить проблему, просто сделав настройку индекса. Дополнительно я должен знать, как сделать этот уровень настройки индекса, но это - кусок пирога, когда внезапно план с очевидностью показывает то, что он реально делает.
Как узнать, будут ли ваши функции выполняться быстрей
В документации перечисляется множество конструкций T-SQL, которые могут или не могут встраиваться:
Требования встраивания скалярных UDF
Но чтение этого потребует от вас открытия кода и в ваших пользовательских функциях, и это одна из главных причин профессионального самоубийства. А я не хочу лишить читателей.
Вместо этого загрузим предварительный выпуск SQL Server 2019, установим его на тестовую VM, восстановим туда вашу базу данных и выполним:
SELECT * FROM sys.sql_modules;
Новый столбец is_inlineable скажет вам, которая из ваших функций может встраиваться:
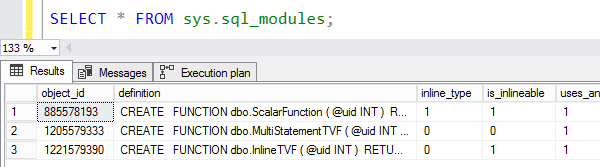 sys.sql_modules
sys.sql_modules
Затем, чтобы узнать, какая из ваших функций вызывается наиболее часто на рабочем сервере, используйте sp_BlitzCache:
sp_BlitzCache @SortOrder = 'executions';
Проведите их инвентаризацию, и пока вы там смотрите на функции, попробуйте выполнить сортировку по CPU, Reads или Memory Grant как альтернативу. Ищите табличные переменные, большое выделение памяти, или малое выделение, которое приводит к ее утечке, поскольку SQL Server 2019 улучшил и это тоже.
Это позволит вам построить бизнес-модель обслуживания. Вы сможете объяснить, какие из ваших запросов могут волшебным образом ускориться после апгрейда, и какое влияние на ваш SQL Server это окажет в целом без изменения кода. Это особенно ценно для приложений третьих сторон, когда вы не можете менять код, но требуется поднять производительность.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой