
Поиск по индексу мало что значит
Пересказ статьи Brent Ozar. “Index Seek” Doesn’t Mean Much.
Когда вы видите “index seek” в плане выполнения, это не означает, что SQL Server прыгает точно к той строке, которую вы ищете. Это означает лишь то, что SQL Server ищет в первом столбце индекса.
Это особенно вводит в заблуждение для индексов, у которых первый столбец не очень селективный.
Чтобы это объяснить, я возьму одну из больших баз Stack Overflow и создам этот индекс на таблице Users:
А затем выполню следующий запрос:
Действительный план выполнения покажет поиск по индексу:
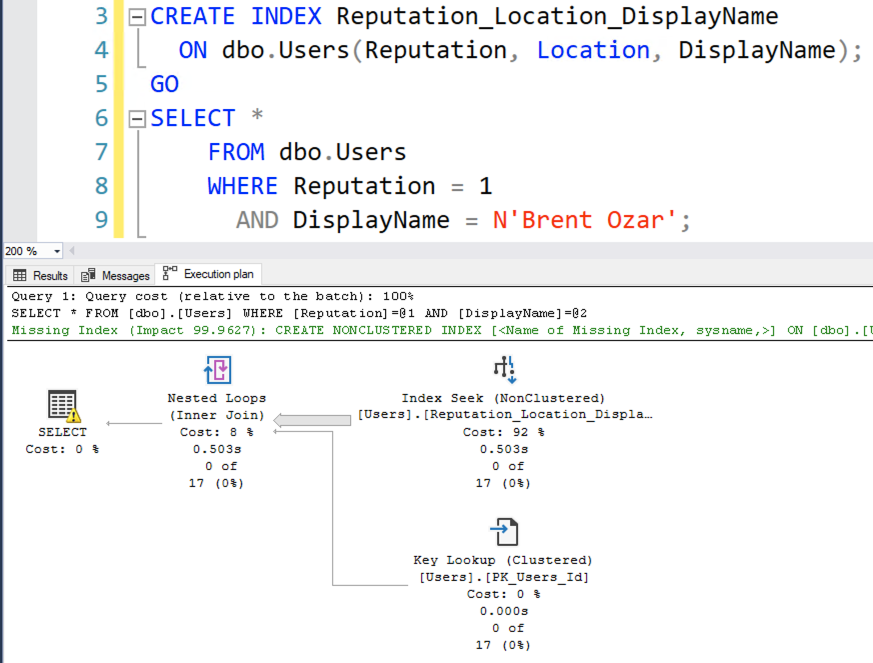
Но если навести мышку на index seek, то всплывающее окно покажет детали:

Посмотрите на “Number of Rows Read” - мы читаем 6044557 строк, чтобы получить ровно 0 строк. Это не то, что вы или я на самом деле называем поиском по индексу - мы прочитали 2/3 всей таблицы!
Проблема заключается в том, что термин “Index Seek” имеет отношение только к тому, как мы получаем доступ к первому столбцу индекса. В нижней части скриншота термин “Seek Predicates” (предикаты поиска) указывает, что на самом деле нам нужно было искать Reputation = 1, но, к сожалению, есть миллионы пользователей, которые имеют такую репутацию.
Немного выше на скриншоте термин “Predicate” (предикат) указывает, что у нас есть остаточный предикат, который мы не можем найти. Я хочу, чтобы он назывался предикат сканирования, поскольку мы сканируем все строки, которые удовлетворяют нашему предикату поиска; мы сканируем их все, поскольку они не упорядочены, чтобы помочь нам в поиске.
Конечно, технически DisplayName находится в индексе - но это не второй столбец в индексе, поэтому не имеет значения, находится он в ключе или во включенных столбцах.
Когда вы видите Index Seek в плане, прежде чем решить, что это хорошее использование индекса, сравните Number of Rows Read (число прочитанных строк) с Actual Number of Rows (действительное число строк). Если ваш запрос читает много больше строк, чем он действительно производит, вы можете существенно улучшить производительность, настроив индексы.
CREATE INDEX Reputation_Location_DisplayName
ON dbo.Users(Reputation, Location, DisplayName);А затем выполню следующий запрос:
SELECT *
FROM dbo.Users
WHERE Reputation = 1
AND DisplayName = N'Brent Ozar';Действительный план выполнения покажет поиск по индексу:
Но если навести мышку на index seek, то всплывающее окно покажет детали:
Посмотрите на “Number of Rows Read” - мы читаем 6044557 строк, чтобы получить ровно 0 строк. Это не то, что вы или я на самом деле называем поиском по индексу - мы прочитали 2/3 всей таблицы!
Проблема заключается в том, что термин “Index Seek” имеет отношение только к тому, как мы получаем доступ к первому столбцу индекса. В нижней части скриншота термин “Seek Predicates” (предикаты поиска) указывает, что на самом деле нам нужно было искать Reputation = 1, но, к сожалению, есть миллионы пользователей, которые имеют такую репутацию.
Немного выше на скриншоте термин “Predicate” (предикат) указывает, что у нас есть остаточный предикат, который мы не можем найти. Я хочу, чтобы он назывался предикат сканирования, поскольку мы сканируем все строки, которые удовлетворяют нашему предикату поиска; мы сканируем их все, поскольку они не упорядочены, чтобы помочь нам в поиске.
Конечно, технически DisplayName находится в индексе - но это не второй столбец в индексе, поэтому не имеет значения, находится он в ключе или во включенных столбцах.
Когда вы видите Index Seek в плане, прежде чем решить, что это хорошее использование индекса, сравните Number of Rows Read (число прочитанных строк) с Actual Number of Rows (действительное число строк). Если ваш запрос читает много больше строк, чем он действительно производит, вы можете существенно улучшить производительность, настроив индексы.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой