
Столбец identity в SQL Server
Пересказ статьи Greg Larsen. SQL Server identity column
При проектировании таблицы базы данных может потребоваться столбец, который заполнялся бы различными числами при вставке каждой строки. Столбец identity может оказаться хорошим способом для автоматического заполнения числового столбца всякий раз, когда вставляется строка. В этой статье я буду обсуждать, что представляет собой столбец identity, и как он работает.
Что такое столбец identity в SQL Server?
Столбец identity - это числовой столбец в таблице, который автоматически получает целое значение, когда вставляется строка. Столбцы identity часто определяются как integer, но они также могут быть объявлены как bigint, smallint, tinyint, или numeric и decimal, если задан масштаб 0. Столбец identity также не может шифроваться с помощью симметричного ключа, но может с помощью прозрачного шифрования данных (Transparent Data Encryption - TDE). Кроме того, определения столбцов identity не должно допускать значений NULL. Одним из недостатков при использовании столбца identity является то, что в таблице может быть только один столбец identity. Если более одного числового поля в таблице должны заполняться автоматически, обратите внимание на объект sequence (последовательность), который в данной статье рассматриваться не будет.
Значения автоматически генерируются для каждой вставляемой строки на основе свойства seed (начальное значение) и increment (приращение) столбца identity. При определении столбца identity используется следующий синтаксис:
IDENTITY [ (seed , increment) ]Seed - это первое значение, загружаемое в таблицу, а increment добавляется к предыдущему значению identity, создавая следующее значение последовательности. Должны быть указаны оба значения seed и increment , если вы хотите изменить значения, принимаемые по умолчанию. Если эти значения не указываются, принимаются значения по умолчанию, равные 1.
Определение столбца identity в операторе CREATE TABLE
При проектировании таблицы большинство архитекторов данных создают макет, поэтому первым столбцом в таблице является столбец identity. На самом деле это только стандартная практика, а не требование к столбцу identity. Любой столбец в таблице может быть столбцом identity, но такой столбец может быть в таблице только один. В скрипте 1 создается новая таблица с именем Widget, которая содержит столбец identity.
Скрипт 1: Создание таблицы со столбцом identity
CREATE TABLE Widget
(
WidgetID int identity(1,1) not null,
WidgetName varchar(100) not null,
WidgetDesc varchar(200) not null
);WidgetID является столбцом identity, с начальным значением 1 и приращением 1.
Начальное значение определяет значение identity для первой строки, вставляемой в таблицу. Значение приращения используется для определения значения identity для последующих строк, вставляемых в таблицу. Для каждой строки, вставляемой после первой строки, значение приращения добавляется к текущему значению identity для определения значения identity новой добавляемой строки. Текущим значением является целое значение столбца identity последней вставленной строки в таблицу. Чтобы посмотреть как это работает, выполните скрипт 2.
Скрипт2: Код вставки и вывода трех строк, добавленных в таблицу Widget
INSERT INTO Widget VALUES
('thingamajig','A jig you cannot remember'),
('doodad','A hair style you cannot remember'),
('whatchamacallit', 'A thing for which you cannot remember');
SELECT * FROM Widget;При выполнении скрипта 2 будет получен следующий вывод:

В скрипте 2 во вновь созданную таблицу вставляются три строки. Скрипт предоставляет значения только для столбцов WidgetName и WidgetDesc, но не для столбца WidgetID. Значение для столбца WidgetID для первой вставленной строки определяется значением seed в операторе CREATE TABLE, который приведен в скрипте 1. Значение 2 столбца WidgetID для строки с WidgetName doodad было получено добавлением приращения 1 к последнему вставленному значению identity. Значение 3 столбца WidgetID для строки с WidgetName whatchamacallit получило свое значение добавлением 1 к значению identity, использованному для второй вставленной строки.
Помните, что начальное значение и приращение не обязаны быть равными по 1; они могут быть любыми подходящими для таблицы значениями. Например, таблица может использовать начальное значение 1000 и приращение 10, как я сделал для столбца WidgetID.
Скрипт 3: Использование различных значений seed и increment
CREATE TABLE DifferentSeedIncrement
(
ID int identity(1000,10),
A varchar(100),
B varchar(200)
);Столбец ID в скрипте 3 не имеет определения свойства NOT NULL в операторе CREATE TABLE, как я делал это для столбца identity в скрипте 1. Требование not null для столбца можно опустить, поскольку за сценой ядро базы данных автоматически добавляет свойство NOT NULL для любого столбца identity при его создании.
Я оставляю вам выполнение кода в скрипте 3 и вставку нескольких строк в таблицу DifferentSeedIncrement. Тогда вы сами сможете увидеть генерацию значений ID для каждой новой строки, вставляемой в таблицу DifferentSeedIncrement, и как таблица определена для SQL Server.
Уникальность столбца identity
Создание столбца identity в таблице не означает, что значение identity будет уникальным. Причина, по которой значения столбца identity могут не быть уникальными, состоит в том, что SQL Server позволяет вставлять значения identity вручную, а также начальное значение может быть сброшено. Я буду обсуждать вставку значений identity, а также сброс начального значения в следующей статье. Документация SQL Server ясно утверждает, что уникальность может быть наложена с помощью первичного ключа, ограничения уникальности или уникального индекса. Следовательно, гарантия, чтобы столбец identity содержал только уникальные значения, должна быть обеспечена один из вышеупомянутых объектов.
Идентификация столбцов и их определений в базе данных
Существует много способов идентифицировать столбцы identity и их определения в базе данных. Один из них - использовать браузер объектов SQL Server, хотя столбец identity не может быть обнаружен в простом отображении столбцов в таблице, как показано на рис.1.
Рис.1: Отображение определений столбцов для таблиц, созданных скриптами 1 и 3
Для выяснения того, какой столбец действительно является столбцом identity, необходимо посмотреть свойства столбца. Для этого выполните щелчок правой кнопкой на Object Explorer, а затем на пункте Properties в выпадающем контекстном меню. На рис.2 показаны свойства столбца WidgetID в таблице Widget.
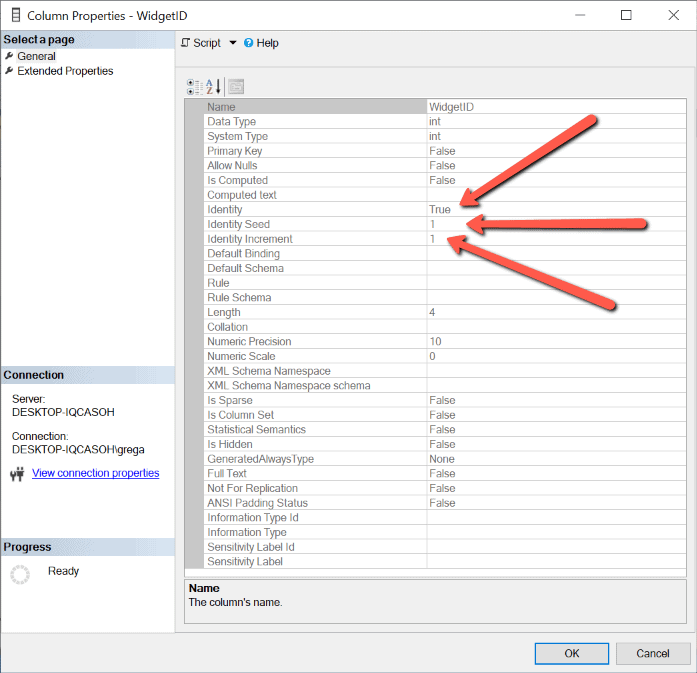
Рис.2: Свойства столбца dbo.Widget.WidgetId
Если свойство Identity имеет значение True, то этот столбец является столбцом Identity. Также показаны начальное значение и приращение.
Использование свойств браузера объектов для идентификации столбцов Identity в базе данных с множеством таблиц может потребовать времени. Другим методом для вывода всех столбцов Identity в базе данных является использование представления sys.identity_column, как показано в коде T-SQL скрипта 4.
Скрипт 4: Вывод всех значений Identity в базе данных
SELECT
OBJECT_SCHEMA_NAME(tables.object_id, db_id())
AS SchemaName,
tables.name As TableName,
identity_columns.name as ColumnName,
identity_columns.seed_value,
identity_columns.increment_value,
identity_columns.last_value
FROM sys.tables tables
JOIN sys.identity_columns identity_columns
ON tables.object_id=identity_columns.object_id
GO Скрипт 4 возвращает такой результат:

Обратите внимание, что столбец last_value для значения DifferentSeedIncrement столбца TableName имеет значение NULL. Это означает, что никаких строк не было вставлено в эту таблицу, поэтому LastValue (последнее значение) не имеет значения.
Добавление столбца identity в существующую таблицу
Существующий столбец нельзя изменить, чтобы он стал столбцом identity, но можно добавить новый столбец identity в существующую таблицу. Чтобы показать, как это может быть сделано, выполните код в скрипте 5. Это скрипт создает новую таблицу, добавляет две строки, а затем меняет таблицу, чтобы добавить новый столбец identity.
Скрипт 5: Добавление столбца identity
CREATE TABLE Invoices
(
InvoiceDate date,
InvoiceNumber varchar(100),
PayTo varchar (100)
);
INSERT INTO Invoices VALUES
(getdate(), 'GL_0001', 'Greg Larsen'),
(getdate(), 'GL_0002', 'Greg Larsen');
-- Добавить столбец Identity
ALTER TABLE Invoices
ADD InvoiceID int identity;
-- Просмотр строк
SELECT * FROM Invoices;Результат выполнения скрипта:

На рисунке видно, что добавлен новый столбец InvoiceID, это столбец был автоматически заполнен значениями identity для всех существующих строк.
Изменение существующей таблицы для определения столбца identity
Как уже говорилось, SQL Server не позволяет использовать команду ALTER TABLE/ALTER COLUMN для непосредственного преобразования существующего столбца в столбец identity. Однако есть вариант модификации существующего столбца таблицы, чтобы он стал столбцом identity. Следующий пример демонстрирует вариант, который использует рабочую таблицу для изменения столбца в существующей таблице на столбец identity.
Чтобы выполнить модификацию существующего столбца в столбец identity, скрипт использует команду ALTER TABLE … SWITCH. Опция SWITCH была добавлена в оператор ALTER TABLE в SQL Server 2005 как часть функции секционирования. Код T-SQL в скрипте 6 использует временную таблицу и опцию SWITCH для поддержки преобразования существующего столбца в столбец identity.
Скрипт 6: Преобразование существующего столбца в столбец identity
DROP TABLE Invoices -- очищаем от предыдущего примера
GO
-- Шаг 1: Создание таблицы Invoices и наполнение её данными
CREATE TABLE Invoices
(
InvoiceID int NOT NULL,
InvoiceDate date,
InvoiceNumber varchar(100),
PayTo varchar (100)
);
INSERT INTO Invoices VALUES
(1, getdate(), 'GL_0001', 'Greg Larsen'),
(2, getdate(), 'GL_0003', 'Greg Larsen');
-- Шаг 2: создание временной рабочей таблицы с той же схемой, но имеющей столбец identity
CREATE TABLE Invoices2
(
InvoiceID int identity(1,1),
InvoiceDate date,
InvoiceNumber varchar(100),
PayTo varchar (100)
);
-- Шаг 3: Переключение таблиц, удаление исходной и переименование
ALTER TABLE Invoices SWITCH TO Invoices2;
-- удаление исходной таблицы
DROP TABLE Invoices;
-- Переименование временной таблицы в имя исходной таблицы
EXEC sp_rename 'Invoices2','Invoices';
-- Шаг 4: Обновление текущего значения seed для новой таблицы Invoices
DBCC CHECKIDENT('Invoices');Скрипт 6 проходит 4 шага, чтобы преобразовать существующий столбец в столбец identity. Ниже перечислено то, что нужно иметь в виду при использовании этого метода для добавления столбца identity в существующую таблицу:
Чтобы использовать опцию SWITCH в операторе ALTER TABLE, столбец в исходной таблице, изменяемый на столбец identity, не должен допускать NULL-значений. Если он допускает NULL, то операции switch будут неудачны.
Не забудьте сбросить начальное значение столбца identity новой таблицы с помощью команды DBCC CHECKIDENT. Если этого не сделать, то следующая вставленная строка будет использовать исходной значение seed, и могут возникать дубликаты значений identity, если столбец не является первичным ключом или не имеет ограничения уникальности, или уникального индекса на столбце identity.
Перед запуском команды ALTER TABLE… SWITCH необходимо удалить все внешние ключи.
Если на исходной таблице существуют индексы, то временная таблица также должна иметь точно те же самые индексы, или оператор switch завершится неудачно.
При выполнении команды ALTER TABLE …SWITCH не должно быть других транзакций, обращающихся к этой таблице. Все новые транзакции не будут запущены пока выполняется операция switch.
При переключении таблиц разрешения безопасности могут быть потеряны, поскольку разрешения безопасности связаны с целевой таблицей, когда выполняется операция переключения. Поэтому убедитесь, что разрешения исходной таблицы воссоздаются на целевой таблице либо до, либо сразу после операции переключения.
Повторное заполнение столбца identity
В предыдущем примере я выполнял повторное заполнение столбца identity с помощью оператора DBCC CHECKIDENT. Имеются другие причины, почему столбец DBCC CHECKIDENT требует повторного заполнения, например, когда несколько строк были неправильно вставлены в таблицу, или ошибочные строки были удалены. Ошибочно вставленные строки вызывают возрастание текущего значения identity для каждой добавленной строки. Таким образом, после удаления всех неправильных строк следующая строка будет использовать следующее значение identity и оставит большой зазор в значениях identity. Если допущена эта ошибка, то повторное заполнение значений identity гарантирует отсутствие больших зазоров пропущенных значений identity.
Для повторного заполнения значений identity в таблице используется команда DBCC CHECKIDENT. Эта команда имеет следующий синтаксис:
DBCC CHECKIDENT
(
имя_таблицы
[, { NORESEED | { RESEED [, новое_значение_seed ] } } ]
)
[ WITH NO_INFOMSGS ] Параметр имя_таблицы - это имя таблицы, которая содержит спецификацию identity. Таблица должна содержать столбец identity, в противном случае при выполнении команды DBCC CHECKINDENT возникает ошибка. Если никакие опции не указаны в этой команде, текущее значение identity будет сброшено к максимальному существующему значению в столбце identity.
Опция NORESEED предписывает не изменять начальное значение (seed). Эта опция полезна для определения текущего и максимального значения identity. Если текущее и максимальное значения различны, то значение identity должно быть повторно заполнено.
Когда текущее значение identity меньше максимального, или существует большой зазор в значениях identity, для сброса текущего значения identity может использоваться опция RESEED. Опция RESEED может быть указана с новое_значение_seed или без него. Если новое_значение_seed не указано, текущее значение identity будет установлено в максимальное значение, записанное в столбце identity указанной таблицы.
Скрипт 6 показывает, как повторно заполнить значение столбца identity с помощью команды DBCC CHECKINDENT без использования опции RESEED. В скрипте 7 показан код T-SQL, который устанавливает текущее значение seed в 2 используя опцию RESEED.
Скрипт 7: Использование опции RESEED
DBCC CHECKIDENT('Invoices',RESEED,2);Будьте осторожны с использованием опции RESEED с новым значением seed. SQL Server не заботится о том, какое значение используется для нового начального значения. Если новое значение установлено в значение, которое меньше максимального значения seed в таблице, могут возникнуть дублирующиеся значения identity.
Столбец identity в SQL Server
Столбец identity будет автоматически генерировать и заполнять значениями числовой столбец всякий раз, когда новая строка вставляется в таблицу. Столбец identity использует текущее значение seed, а также значение инкремента для генерации нового значения identity для каждой вставляемой строки. Здесь рассмотрены основные аспекты использования столбца identity. В следующей статье будут изучены некоторые нюансы столбцов identity.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой