
Столбцы, допускающие NULL-значения, и производительность
Пересказ статьи DANIEL HUTMACHER. Nullable columns and performance
Яд NULL
Рассмотрим следующий скрипт:
--- Создаем внешнюю таблицу и добавим в нее несколько строк
CREATE TABLE #outer (
i int NOT NULL,
CONSTRAINT PK PRIMARY KEY CLUSTERED (i)
);
INSERT INTO #outer (i) VALUES (1);
WHILE (@@ROWCOUNT<100000)
INSERT INTO #outer (i)
SELECT MAX(i) OVER ()+i
FROM #outer;
--- Создадим внутреннюю таблицу, и наполним ее копией данных из внешней таблицы
--- минус 10 случайных строк:
CREATE TABLE #inner (
i int NULL
);
CREATE UNIQUE CLUSTERED INDEX UCIX ON #inner (i);
INSERT INTO #inner (i)
SELECT i
FROM #outer;
--- Удаляем 10 случайных строк, чтобы стало интересней
DELETE TOP (10) FROM #inner;
Теперь рассмотрим несколько простых запросов с IN(). Начнем с этого:
SELECT
FROM #outer
WHERE i IN (SELECT i FROM #inner);
Он приводит к действительно хорошему соединению merge join, поскольку обе таблицы имеют одинаковые кластеризованные индексы на столбце, по которому выполняется соединение.
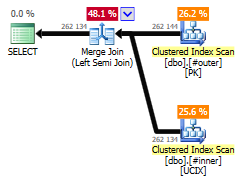 Замечательная простота
Замечательная простота
Что произойдет, если мы поменяем IN() на NOT IN()?
SELECT
FROM #outer
WHERE i NOT IN (SELECT i FROM #inner);
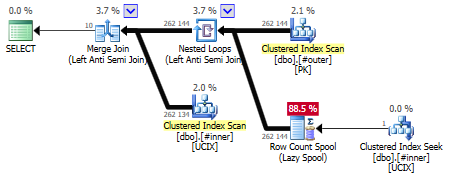 Почему так сложно?
Почему так сложно?
Мы ожидали, что полусоединение (Semi Join) превратится в анти-полусоединение (Anti Semi Join), однако план теперь содержит ветвь вложенных циклов (Nested Loop) с Row Count Spool - о чем это? Оказывается, что Row Count Spool, наряду с поиском в индексе, имеет отношение к NOT IN() и тому факту, что мы просматриваем столбец, допускающий NULL-значения. Помним, что
x NOT IN (y, z, NULL)
всегда возвращает false, поскольку NULL может представлять что-угодно, в том числе x. И это имеет отношение к внутренней таблице, если там содержатся NULL-значения.
Поэтому поиск по кластеризованному индексу внизу справа фактически проверяет, имеется ли
NULL-значение в столбце соединения внутренней таблицы, и, если есть, всё соединение соответствующего Merge Join между внутренней и внешней таблицами не вернет строк.
Упрощение плана
Есть несколько способов сделать план проще.
Устранение NULL
Вы могли бы изменить тип столбеца, чтобы он не допускал NULL-значений (тогда SQL Server не будет сначала проверять наличие NULL-значений), или вы могли бы просто сообщить SQL Server'у игнорировать NULL-значения, исключив их в предложении WHERE:
SELECT
FROM #outer
WHERE i NOT IN (SELECT i FROM #inner
WHERE i IS NOT NULL);
 Назад к использованию Merge Join
Назад к использованию Merge Join
Использование NOT EXISTS вместо NOT IN
Вы могли бы переписать запрос на использование конструкции NOT EXISTS, которая будет оптимизирована на формирование точно такого же плана с Merge Join, как и показанного выше.
SELECT
FROM #outer AS o
WHERE NOT EXISTS (SELECT i FROM #inner AS i
WHERE o.i=i.i);
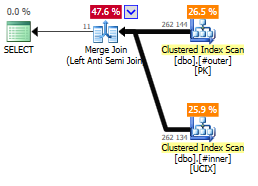 Left Anti Join
Left Anti Join
Вы можете написать запрос с LEFT JOIN и предложением WHERE, но то, что улучшает читабельность, приведет к добавлению лишнего оператора Filter, который может замедлить запрос.
SELECT o.*
FROM #outer AS o
LEFT JOIN #inner AS i ON o.i=i.i
WHERE i.i IS NULL;
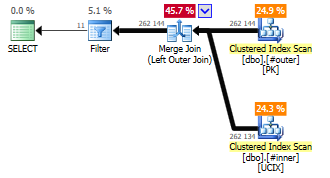 Сначала собираем, потом фильтруем
Сначала собираем, потом фильтруем
Чудеса теоретико-множественных операций
Вы можете использовать оператор EXCEPT. Он генерирует в этом случае тот же самый план; недостатком является то, что вы можете вернуть только ключевые столбцы. Но зато EXCEPT не сравнивает NULL-значения в отличии от оператора равенства в обычном соединении.
SELECT i FROM #outer
EXCEPT
SELECT i FROM #inner;
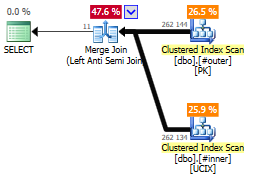 Соединение Left Anti Semi, но сканирование вместо поиска
Соединение Left Anti Semi, но сканирование вместо поиска
"... но кто создает столбцы, допускающие NULL-значения, если их там фактически нет?" - слышу я ваш вопрос.
Хорошо, что вы спросили. Существует много способов сделать это случайно. Один из них - использовать SELECT...INTO в новую временную таблицу. При этом наследуется спецификация NULL столбца-источника.
Другим способом является использование CREATE TABLE без явного указания NOT NULL.
CREATE TABLE #inner (
i int
)
Если вы не укажите ни "NULL", ни "NOT NULL", то по умолчанию используется "NULL".
Почему об этом стоит беспокоиться
На самом деле запрос в этом примере будет проверять внутренюю таблицу на NULL значения только один раз (оператор Spool), и для этой проверки будет использоваться поиск по индексу, т.к. столбец индексирован. Поэтому вряд ли следует ожидать здесь проблем с производительностью.
Однако ситуация гораздо хуже в следующем примере, который использует базу данных Stack Overflow, где ничего этого нет:
SELECT u.Id AS UserId,
u.DisplayName,
COUNT(*) AS UnansweredWithin24Hours
FROM dbo.Users AS u
INNER JOIN dbo.Posts AS p ON
u.Id=p.OwnerUserId AND
p.PostTypeId=1
WHERE p.Id NOT IN (SELECT ParentId
FROM dbo.Posts
WHERE PostTypeId=2
AND CreationDate<=DATEADD(hour, 24, p.CreationDate))
GROUP BY u.Id, u.DisplayName
Столбец ParentId в Posts допускает NULL и не индексирован, поэтому получаемый план выполнения завершается выполнением Nested Loop для каждой строки в Posts с каждой строкой в "p". Пофиксив проблему NULL-значений рассмотренными выше способами, для выполнения запроса потребуется лишь несколько секунд вместо часов.
 Исходный запрос. Выполняется часами на всех ядрах
Исходный запрос. Выполняется часами на всех ядрах
Простое добавление “AND ParentId IS NOT NULL” к подзапросу в NOT IN(), дает:
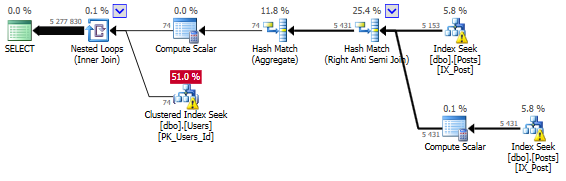 Улучшенный запрос. Секунды на одном ядре
Улучшенный запрос. Секунды на одном ядре
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой