
Стоит ли использовать STRING_SPLIT в SQL Server 2022?
Пересказ статьи Brent Ozar. Should You Use SQL Server 2022’s STRING_SPLIT?
Функция STRING_SPLIT была улучшена в SQL Server 2022, так что теперь она может гарантировано возвращать упорядоченный список. Однако только это и было улучшено - по-прежнему остались критичные связанные с этой функцией проблемы производительности.
Давайте возьмем базу данных Stack Overflow и таблицу Users, создадим индекс на Location, а затем протестируем пару запросов, которые используют STRING_SPLIT для разбора параметра, которым является список местоположения:
Эти два запроса приводят к немного разнящимся фактическим планам выполнения, но способ поведения STRING_SPLIT одинаков в обоих случаях, поэтому я собираюсь взять только первый запрос для использования в качестве иллюстрации:
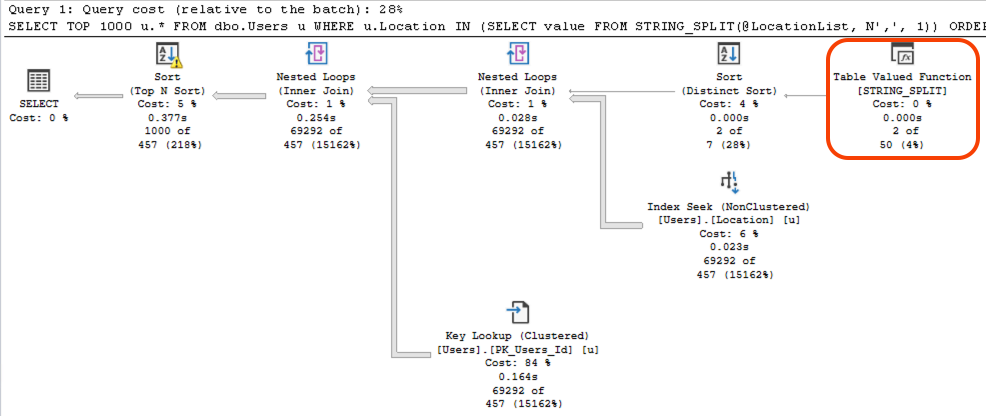
Эта выделенная красным часть имеет две проблемы:
В результате и все остальное в плане запроса обречено. Все оценки являются мусором. SQL Server выберет неправильные индексы, не ту таблицу обработает первой, примет неверные решения относительно параллелизма, совершенно ошибется при выделении памяти т.д.
Подобно тому, что я писал о DATETRUNC, это не делает STRING_SPLIT плохим инструментом. Это совершенно замечательный инструмент, если вам нужно распарсить строку в список значений - но не используйте его в предложении WHERE, так сказать. Не полагайтесь на его хорошую работу в больших запросах, которые включают соединения с другими таблицами.
Одним возможным решением является сбрасывание содержимого строки сначала во временную таблицу:
Фактический план выполнения ведет себя лучше, чем в предыдущих примерах. Вы можете увидеть полный план, щелкнув по ссылке, но я тут хочу остановиться на секции, относящейся к STRING_SPLIT, и поиске в индексе:
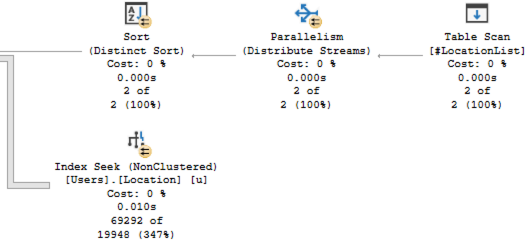
Этот план лучше, потому что:
Ууууу! Просто помните, что временные таблицы похожи на OPTION (RANDOM RECOMPILE), о чем я говорил в лекции об основах TempDB.
CREATE INDEX Location ON dbo.Users(Location);
SET STATISTICS IO ON;
GO
CREATE OR ALTER PROC dbo.usp_GetUsersByLocation_Subquery
@LocationList NVARCHAR(4000) AS
SELECT TOP 1000 u.*
FROM dbo.Users u
WHERE u.Location IN (SELECT value FROM STRING_SPLIT(@LocationList, N',', 1))
ORDER BY u.Reputation DESC;
GO
CREATE OR ALTER PROC dbo.usp_GetUsersByLocation_Join
@LocationList NVARCHAR(4000) AS
SELECT TOP 1000 u.*
FROM STRING_SPLIT(@LocationList, N',', 1) l
INNER JOIN dbo.Users u ON l.value = u.Location
ORDER BY u.Reputation DESC;
GO
EXEC usp_GetUsersByLocation_Subquery N'India,China';
EXEC usp_GetUsersByLocation_Join N'India,China';Эти два запроса приводят к немного разнящимся фактическим планам выполнения, но способ поведения STRING_SPLIT одинаков в обоих случаях, поэтому я собираюсь взять только первый запрос для использования в качестве иллюстрации:
Эта выделенная красным часть имеет две проблемы:
- SQL Server не знает, сколько строк будет получено из текстовой строки, поэтому жестко кодирует приблизительную оценку из 50 элементов.
- SQL Server не знает, каким будет содержимое этих строк, либо - он не знает, будет ли это India, China или Hafnarfjörður
В результате и все остальное в плане запроса обречено. Все оценки являются мусором. SQL Server выберет неправильные индексы, не ту таблицу обработает первой, примет неверные решения относительно параллелизма, совершенно ошибется при выделении памяти т.д.
Подобно тому, что я писал о DATETRUNC, это не делает STRING_SPLIT плохим инструментом. Это совершенно замечательный инструмент, если вам нужно распарсить строку в список значений - но не используйте его в предложении WHERE, так сказать. Не полагайтесь на его хорошую работу в больших запросах, которые включают соединения с другими таблицами.
Обход проблем, связанных с STRING_SPLIT
Одним возможным решением является сбрасывание содержимого строки сначала во временную таблицу:
CREATE OR ALTER PROC dbo.usp_GetUsersByLocation_TempTable
@LocationList NVARCHAR(4000) AS
BEGIN
SELECT value
INTO #LocationList
FROM STRING_SPLIT(@LocationList, N',', 1);
SELECT TOP 1000 u.*
FROM dbo.Users u
WHERE u.Location IN (SELECT value FROM #LocationList)
ORDER BY u.Reputation DESC;
END
GO
EXEC usp_GetUsersByLocation_TempTable N'India,China';Фактический план выполнения ведет себя лучше, чем в предыдущих примерах. Вы можете увидеть полный план, щелкнув по ссылке, но я тут хочу остановиться на секции, относящейся к STRING_SPLIT, и поиске в индексе:
Этот план лучше, потому что:
- SQL Server знает, сколько строк находится в #LocationList.
- Еще лучше, он знает, что это за строки, и это влияет на его оценку числа пользователей, проживающих соответствующих местах.
- SQL Server принимает лучшие решения относительно параллелизма и грантов памяти в остальной части плана.
Ууууу! Просто помните, что временные таблицы похожи на OPTION (RANDOM RECOMPILE), о чем я говорил в лекции об основах TempDB.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой