
Статистика в SQL Server
Пересказ статьи Grant Fritchey. Statistics in SQL Server
Оптимизатор запросов SQL Server опирается на статистику для построения адекватного плана запроса. Если статистика неверна, устарела или отсутствует, вы имеете весьма слабую надежду на хорошую производительность ваших запросов. Поэтому важно понимать, как SQL Server поддерживает статистику распределения.
Что такое статистика?
Оптимизатор запросов SQL Server использует статистику распределения, чтобы определиться с тем, как выполнять ваш запрос. Эта статистика представляет собой распределение данных в столбце или столбцах. Оптимизатор запросов использует его для оценки количества строк, которые будут возвращены планом запроса. При отсутствии статистики по распределению данных оптимизатор не будет иметь возможности сравнить эффективность различных планов и, следовательно, зачастую будет вынужден просто выполнять сканирование таблицы или индекса. Без статистики он не сможет узнать, содержит ли столбец искомые данные без его просмотра. При наличии статистики о содержимом столбца у оптимизатора будет значительно больше шансов сделать лучший выбор механизма доступа к данным и использования ваших индексов.
Статистика распределения создается автоматически при создании индекса. Если у вас настроено автоматическое создание статистики (установка по умолчанию параметра базы данных AUTO_CREATE_STATISTICS), вы будете получать созданную статистику при всяком обращении к столбцу в предложениях запроса, выполняющих фильтрацию или задающих критерии соединения JOIN.
Данные измеряются двумя различными способами в пределах единого набора статистики: по плотности и по распределению.
Плотность
Плотность проще понять; она представляет собой отношение, которое просто показывает, сколько уникальных значений содержится в данном столбце или наборе столбцов. Формула проще простого:
Плотность = 1/Число различных значений столбца (столбцов)
Она позволяет вам написать запрос к вашей таблице, чтобы точно увидеть, какой должна быть плотность:
SELECT 1.0 / COUNT(DISTINCT MyColumn)
FROM dbo.MyTable;
Вы также можете увидеть плотность для комбинации столбцов. Для этого в запросе достаточно сначала получить уникальную комбинацию списка столбцов:
SELECT 1.0 / COUNT(*)
FROM (SELECT DISTINCT FirstColumn,
SecondColumn
FROM dbo.MyTable) AS DistinctRows;
И, конечно, вы можете добавить столбцы, по которым построен индекс, чтобы увидеть плотность индекса.
Плотность важна, поскольку она является мерой селективности данного индекса, а также одним из лучших способов оценки эффективности его использования для выполнения запроса. Высокая плотность (низкая селективность, незначительная доля уникальных значений) делает маловероятным использование индекса оптимизатором ввиду его неэффективности для получения ваших данных. Например, если ваш столбец содержит данные типа бит, скажем, подписан клиент на почтовую рассылку или нет, то для миллиона строк вы будете видеть только одно из двух значений. Это означает, что использование индекса или статистики для получения данных из таблицы на основе двух значений сведется к сканированию, в то время как более селективные данные, например, адрес электронной почты, приводит к более эффективному доступу к данным.
Следующая мера - распределение данных - несколько сложнее.
Распределение данных
Распределение данных представляет статистический анализ вида данных, которые находятся в первом столбце, доступном для статистики. Это справедливо также и для составного индекса, т.е. вы получите только единственный столбец данных для их распределения. Это одна из причин рекомендации размещать наиболее селективный столбец первым в индексе. Однако помните, что это только предложение, и существует множество исключений, например, если первый столбец сортирует данные более эффективно при том, что он не самый селективный. Вернемся, однако, к распределению данных. Механизм хранения информации о распределении называется гистограммой. По статистическому определению гистограммой является визуальное представление распределения данных; однако статистика распределения использует более общий математический смысл этого термина.
Гистограмма - это функция, которая подсчитывает число вхождений данных в каждое множество категорий (известных как bins), и в статистике распределения эти категории выбираются так, чтобы представлять распределение данных. Именно эта информация может использоваться оптимизатором для оценки числа строк, возвращаемых заданным значением.
В SQL Server гистограмма содержит до 200 различных шагов, или bin'ов. Почему 200? 1) Это статистически существенно или, как мне говорят, 2) это мало, 3) это работает для большинства распределений данных в объеме до нескольких сотен миллионов строк. При больших объемах вам придется обратиться к материалам, относящимся к фильтрованной статистике, фрагментированным (секционированным) таблицам и другим архитектурным решениям. Эти 200 шагов представлены строками таблицы. Строки представляют способ распределения данных в столбце, показывая части данных, описывающих это распределение:
| RANGE_HI_KEY | Это верхняя граница шага, представленного данной строкой на гистограмме. |
| RANGE_ROWS | Предполагаемое количество строк, значение столбцов которых находится в пределах шага гистограммы, исключая верхнюю границу. |
| EQ_ROWS | Предполагаемое количество строк, значение столбцов которых равно верхней границе шага гистограммы. |
| DISTINCT_RANGE_ROWS | Предполагаемое количество строк с различающимся значением столбца в пределах шага гистограммы, исключая верхнюю границу. Если все строки уникальны, то RANGE_ROWS и DISTINCT_RANGE_ROWS будут равны. |
| AVG_RANGE_ROWS | Среднее количество строк с повторяющимися значениями столбцов в пределах шага гистограммы, исключая верхнюю границу (RANGE_ROWS/DISTINCT_RANGE_ROWS для DISTINCT_RANGE_ROWS > 0). |
Эти значения определяются одним из двух способов, выборкой или полным сканированием. Когда индексы создаются или перестраиваются, вы получаете статистику, созданную полным сканированием по умолчанию. Когда статистика обновляется автоматически, SQL Server использует механизм выборки для построения гистограммы. Подход на базе выборки делает генерацию и обновление статистики очень быстрой, но она может оказаться не вполне точной. Это обусловлено механизмом выборки, который случайным образом читает данные из таблицы, а затем производит вычисления для получения данных статистики. Такой алгоритм оказывается достаточно точным для большинства наборов данных, в противном случае, если вам требуется максимально точная статистика, используйте ручное обновление или создание статистики при помощи полного сканирования.
Статистика обновляется автоматически по умолчанию, и существует 3 пороговых значения, которые вызывают автоматическое обновление:
- Если в таблице нет строк, то, когда вы добавляете строку (или строки), происходит автоматическое обновление статистики.
- Если в таблице менее 500 строк, и вы добавляете более 500. Т.е. если у вас 499 строк, то вы должны добавить строки до 999, чтобы произошло автоматическое обновление.
- Когда в таблице более 500 строк, вы должны добавить дополнительно 500 строк + 20% от размера таблицы, чтобы увидеть автоматическое обновление статистики.
Таково поведение по умолчанию. Имеются вариации с фильтрованными индексами и фильтрованной статистикой. Кроме того, для SQL Server 2008R2 SP1 и SQL Server 2012 вы можете установить флаг трассировки 2371, чтобы получить динамическое значение вместо фиксированных 20%. Это поможет на более крупных базах данных получить более частое обновление статистики.
Вы также можете обновлять статистику вручную. Для этого SQL Server предлагает два механизма. Во-первых, sp_updatestats. Эта процедура использует курсор для прохода по всей статистике в указанной базе данных. Она учитывает число модификаций строк, и если были выполнены какие-либо изменения, rowmodctr > 0, то обновляет статистику. Вы можете также обновить отдельную статистику с помощью UPDATE STATISTICS, указав имя. При этом вы можете задать использование FULL SCAN, чтобы гарантировать актуальную статистику, однако потребуется написание кода обслуживания, чтобы сделать это изменение постоянным.
Хватит говорить о том, что такое статистика. Давайте посмотрим на её представление и разберемся с данными, которые в ней содержатся.
DBCC SHOW_STATISTICS
Чтобы увидеть текущее состояние вашей статистики, используйте оператор DBCC SHOW_STATISTICS. Вывод состоит из трех частей:
- Заголовок (Header): содержит метаданные о наборе статистики.
- Плотность (Density): показывает значения плотности для столбца или столбцов, которые определяют набор статистики.
- Гистограмма (Histogram): Таблица, которая определяет описанную выше гистограмму.
Вы можете вытащить отдельные фрагменты данных, модифицируя оператор DBCC.
Информация заголовка может оказаться весьма полезной:
Наибольший интерес представляет информация в следующих столбцах:
- Updated: когда последний раз обновлялся этот набор статистики. Отсюда вы можете узнать о возрасте набора статистики. Если вы знаете, что в один из дней в таблицу были добавлены тысячи строк, но статистика относится к прошлой неделе, вы можете вручную обновить статистику.
- Rows и Rows Sampled: Если эти значения совпадают, вы видите набор статистики, который является результатом полного сканирования. Если они различаются, то, вероятно, статистика получена на основе выборки.
Остальные данные полезны для быстрой оценки статистики.
Второй набор данных представляет собой меры плотности. Вот набор, который показывает плотность составного индекса:
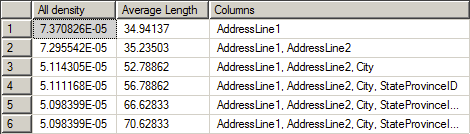
Столбец All density содержит значение плотности, полученное по упомянутой выше формуле. Видно, что это значение уменьшается с каждым следующим столбцом. Ясно, что наиболее селективным является первый столбец. Можно также увидеть среднюю длину (Average Length) значений, которые содержатся в столбце, и, наконец, список столбцов, составляющих каждый уровень плотности.
Наконец, следующий график показывает раздел гистограммы:
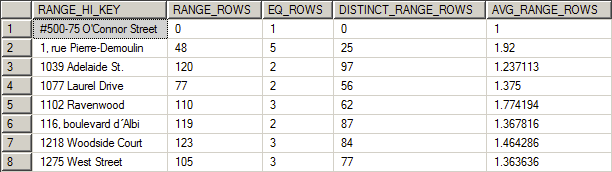
Видно как данные распределены между шагами. При этом вы можете наблюдать, насколько хорошо SQL Server распределяет вашу информацию. Поскольку все количества строк, за исключением среднего, есть целые числа, это еще один фактор, что данный набор статистики представляет собой результат полного сканирования. Если диапазоны строк представляют собой оценку, они будут представлены десятичными числами.
Вы смотрите гистограмму, когда пытаетесь понять, почему план запроса SQL Server содержит scan или seek, в то время когда вы ожидаете увидеть что-то другое. Способ, которым распределяются данные, показывает, например, среднее число строк для заданного значения в пределах некоторого диапазона, что позволяет вам понять, насколько хорошо эти данные могут использоваться оптимизатором. Если вы наблюдаете большое расхождение между строками диапазона или уникальными строками диапазона, то, вероятно, ваша статистика устарела или построена на выборке. Кроме того, если диапазон и уникальные строки сильно расходятся при том, что у вас актуальная и точная статистика, это может говорить о серьезном перекосе данных, которые требуют других подходов к индексированию и построению статистики, например, фильтрованная статистика.
Заключение
Вы можете увидеть множество статистики, поддерживаемой SQL Server. Это жизненно важная часть достижения лучшей производительности системы. Понимание того, как она работает, создается, поддерживается и как её анализировать, поможет вам в работе с собственной статистикой.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой