
Сканирование индекса - не всегда плохо, поиск по индексу - не всегда хорошо
Пересказ статьи Brent Ozar. Index scans aren’t always bad, and index seeks aren’t always great
Когда-нибудь вам говорили, что:
- Поиск по индексу (Index seeks) является быстрой малозатратной операцией.
- Сканирование таблиц (table scan) - убогие, медленные операции.
И с тех пор вы при анализе плана выполнения выискивали эти существенно влияющие на производительность сканирования кластерного индекса. А когда вы находите их, то верите, что имеете проблемы с производительностью.
Дело в том..., что вам врали. И поиск - это не всегда хорошо, и сканирование - необязательно плохо. Чтобы убедить вас в этом, мы проведем серию демонстраций.
Сначала, "плохой" index scan
Начнем с этого запроса, который использует базу данных Stack Overflow 2013 (50GB):
SET STATISTICS IO ON;
GO
SELECT COUNT(*)
FROM dbo.Users;
GO
Получаемый в результате план выполнения содержит сканирование кластерного индекса - чтение всей таблицы, 2.5M строк:
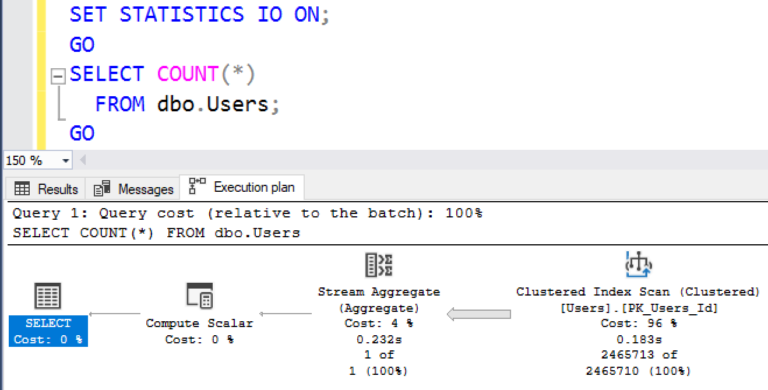
Эта первая строка, SET STATISTICS IO ON, включает серию сообщений, которые покажут вам число логических чтений, которое выполняет SQL Server при исполнении вашего запроса. Это число измеряется в 8-килобайтных страницах. Вывод показан на вкладке Сообщения (Messages):
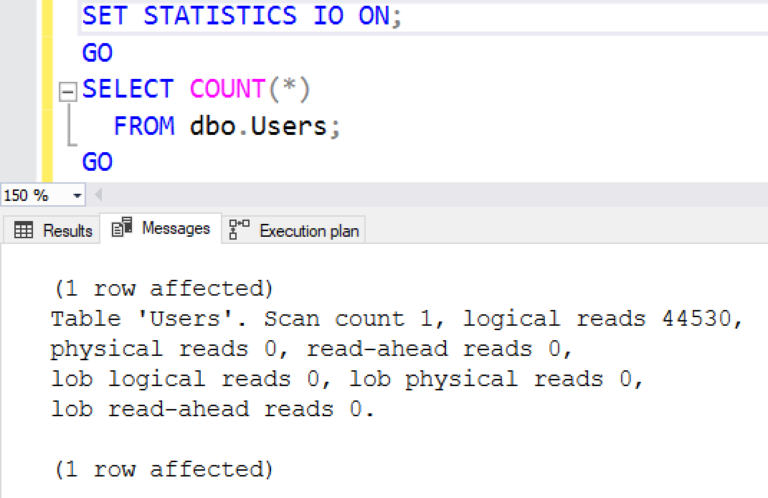
SQL Server прочитал 44530 8-килобайтных страниц (т.е. всю таблицу), подсчитывая количество строк.
Итак, это "плохой" скан - поскольку он читает все страницы - хотя я мог бы аргументировать, что, на самом деле, это плохой запрос. (Вам действительно нужно точное, с точностью до секунды число строк? Вероятно, нет, тогда вы могли бы закешировать этот результат в слое приложения, и использовать его часами. Но я отвлекся.)
А теперь "хороший" index scan
Возьмем запрос:
SELECT TOP 10 FROM dbo.Users;
Мы говорим SQL Server: "Просто дай мне первые 10 строк". Мне все равно, первые ли эти 10 строк, последние ли, или просто 10 случайных строк, которые вы вытаскиваете из вашего бэкэнда. План выполнения для этого запроса также содержит сканирование таблицы:
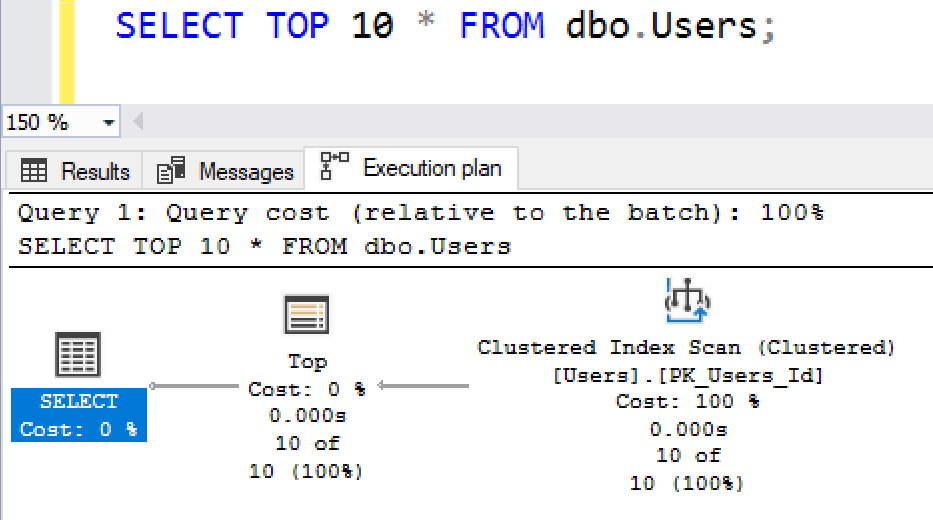
Видите эти тоненькие стрелки? Они означают, что только ограниченное число строк выходит - это хороший знак, но есть реальный индикатор того, что это было хорошо:
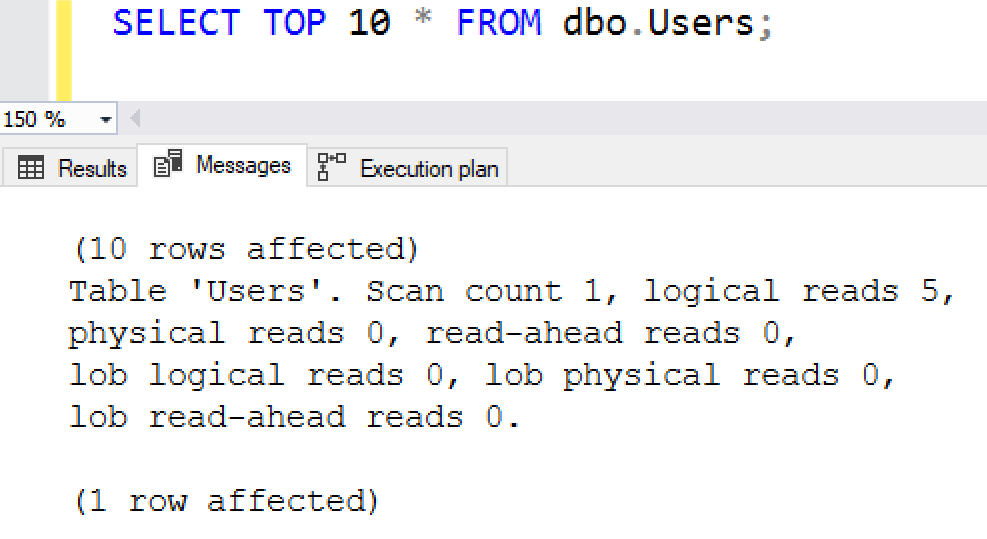
SQL Server должен был прочитать только 5 8-килобайтных страниц, т.е. 40 Кб - что вообще пустяк! Следующий пример в том же ключе.
Вот "хороший" index seek
SELECT FROM dbo.Users WHERE Id = 26837;
План показывает поиск одного конкретного пользователя, и чтение только одной строки:
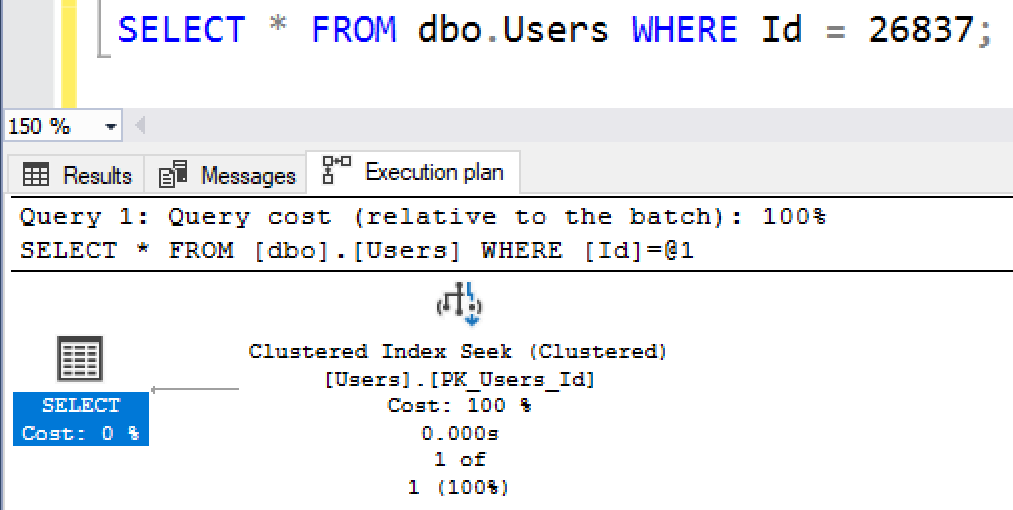
Это суперэффективная операция, требующая чтения только 3-х 8-килобайтных страниц - почти так же, как и для "хорошего" сканирования индекса, которое мы наблюдали секунду назад!
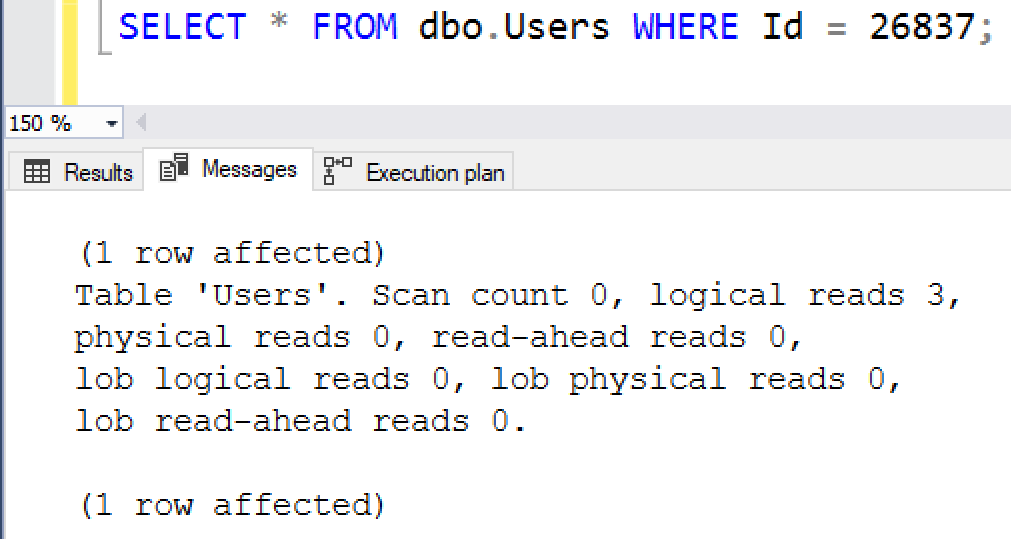
Это тот тип операции, который вы имеете в виду, когда видите слово "seek" в плане, но это только один пример.
А вот "плохой" index seek
Когда вы мысленно строите план выполнения этого запроса, следует иметь в виду, что наименьшее значение id в StackOverflow.Users равно -1. Все остальные значения положительные.
SELECT FROM dbo.Users WHERE Id > -1000;
Этот запрос считывает каждого пользователь в таблице.
Вы, вероятно, предполагаете тут сканирование таблицы, однако это не то, что показывает план:
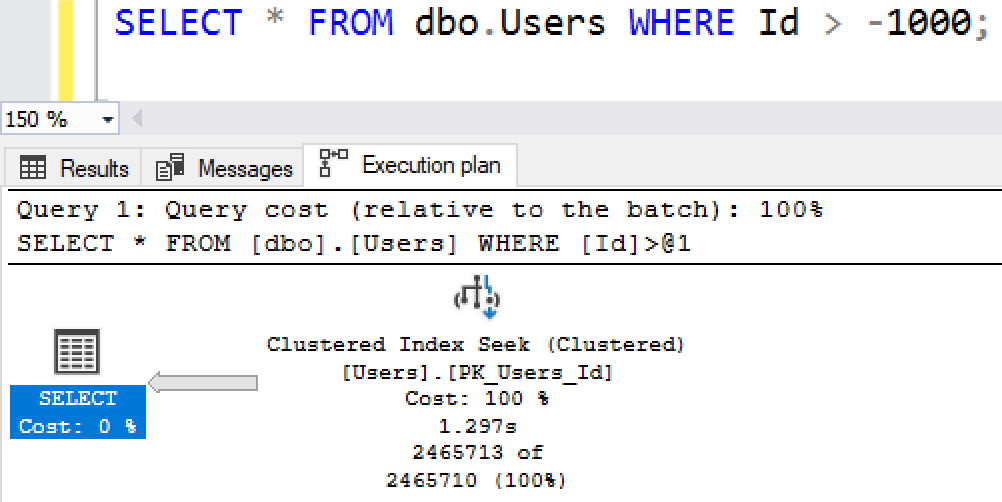
Технически это "поиск", поскольку SQL Server ищет конкретное значение, а затем считывает строки от этого значения. Логические чтения дают больше доказательств, что это чтение всей таблицы:
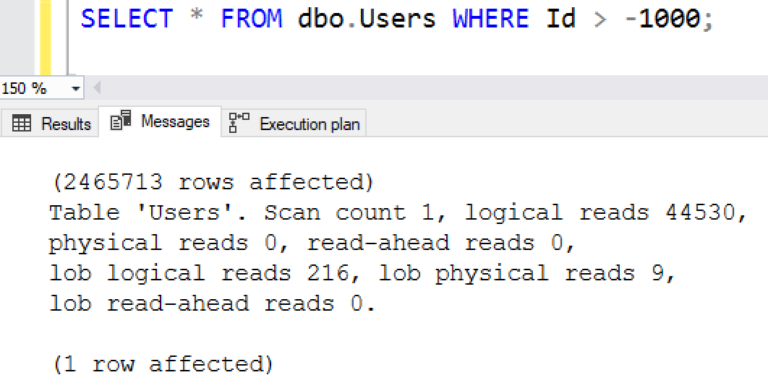
Это множество страниц. Это не то, что вы думаете, когда я говорю "поиск".
А вот что "поиск" и "скан" действительно означают
Поиск (seek) означает, что SQL Server знает конкретную строку, с которой он собирается начать. Вот что это.
- Это может быть первой строкой в таблице.
- Это может быть последней строкой в таблице.
- Это может быть считывание только одной строки.
- Это может быть считывание всех строк.
- Это может выполняться много раз (наведите курсор мыши на оператор в плане и взгляните на "number of executions" (число выполнений), чтобы это выяснить.
Сканирование (scan) означает, что SQL Server собирается начать чтение либо от начала, либо от конца индекса (min или max). Вот что это.
- Это может быть чтением всех строк (то, что вы обычно ожидаете, но...).
- Это может быть считыванием только одной строки.
Операция index seek не обязательно является хорошей, а index scan - не всегда плоха.
Чтобы судить, копай глубже
Давайте возьмем такой запрос:
SELECT FROM dbo.Users
WHERE Id > -1000
AND Reputation < 0;
Его план выполняет поиск по кластеризованному индексу - это чтобы перепрыгнуть к той строке, которая должна быть первой в таблице (id=-1), и считывать все строки в таблице, выбирая те, для которых reputation < 0:
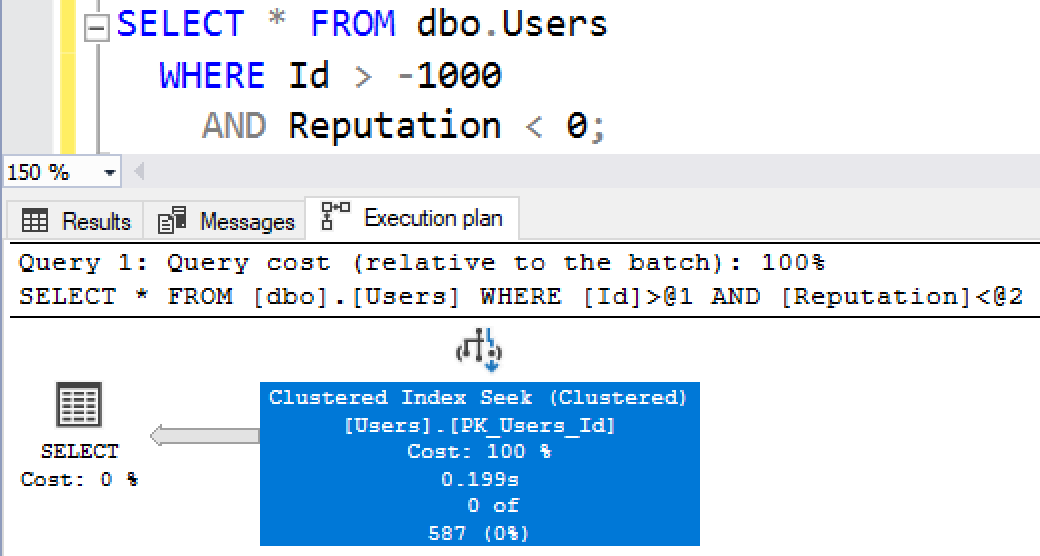
Поэтому это поиск - но заслуживает ли это внимания? Нужно ли что-то делать с этим оператором. Чтобы выяснить это, наведем курсор на оператор seek, и проверим подсказки:
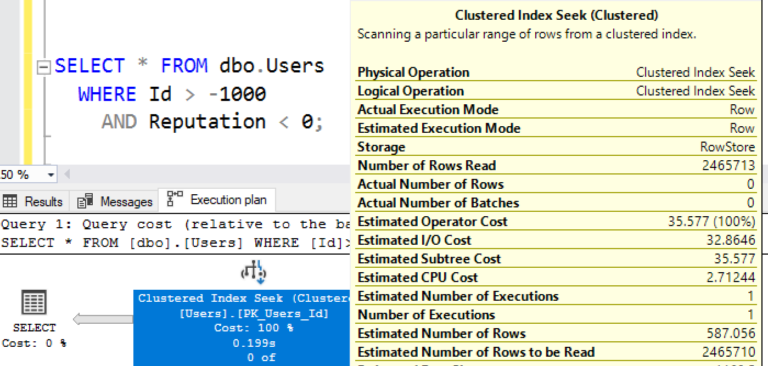
Посмотрим на:
- Number of Rows Read (число чтения строк): 2,465,713 - означает, сколько должен SQL Server проверить строк для того, чтобы найти требуемые.
- Actual Number of Rows (фактическое число строк): 0 - означает, что поиск оказался бесполезным.
Когда SQL Server должен проверить множество данных, чтобы найти немного, это медленный способ доступа к данным. Все может быть в порядке - этот запрос может никогда не запускаться - но если вы хотите, чтобы он запускался быстрей, то здесь вы можете сосредоточить усилия на улучшении индексации. И не имеет значения, что это - seek или scan - если вам приходится читать множество шума, чтобы получить небольшой полезный сигнал, это проблема.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой