
Селективность предиката и структура индекса
Пересказ статьи Erik Darling. Predicate Selectivity and Index Design
Незаконченные дела
Какое-то время назад я обещал написать о том, что заставляет SQL Server выполнять два поиска вместо поиска с остаточным предикатом.
В недавнем посте я немного затронул вопрос селективности предиката в структуре индекса.
Сейчас я собираюсь связать эти две темы вместе. Возможно. Надеюсь. Посмотрим, что из этого выйдет.
Если вкратце, то соседние ключевые столбцы в индексе довольно просто поддерживают поиск, и что выбор первого столбца должен, вероятно, опираться на то, что фильтруется наиболее часто.
Управление индексами
Давайте возьмем реальный пример и создадим два индекса.
CREATE NONCLUSTERED INDEX ix_whatever
ON dbo.Posts ( PostTypeId, ClosedDate );
CREATE NONCLUSTERED INDEX ix_apathy
ON dbo.Posts ( ClosedDate, PostTypeId );
Теперь выполним два идентичных запроса, каждый из которых будет использовать один из этих индексов.
SELECT p.Id, p.PostTypeId, p.ClosedDate
FROM dbo.Posts AS p WITH (INDEX = ix_whatever)
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01';
SELECT p.Id, p.PostTypeId, p.ClosedDate
FROM dbo.Posts AS p WITH (INDEX = ix_apathy)
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01';
Если выполнить их несколько раз, то можно заметить, что первый запрос будет по кругу завершать выполнение на 50 миллисекунд быстрее, чем второй, хотя они оба имеют почти идентичные планы.
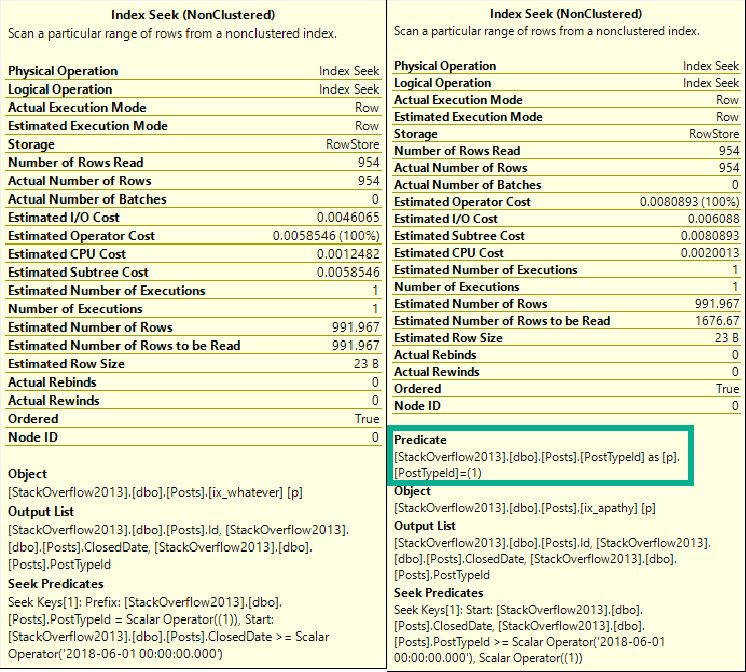
Поиск может выглядеть запутанным, поскольку PostTypeId проявляется и как поиск, и как остаточный предикат. Это связано с сортировкой обоих индексов.
Поиск говорит нам, откуда начинается чтение. Это означает, что мы будем искать строки, начиная с ClosedDate 2018-06-01 и с PostTypeId 1.
Начиная отсюда, мы можем найти более высокие значения PostTypeId, поэтому получаем остаточный предикат, чтобы отфильтровать их.
Вообще говоря, поиск может найти единственную строку или же диапазон строк пока они идут подряд. Когда первый столбец индекса используется для поиска диапазона, мы можем найти начальную точку, но нам потребуется остаточный предикат для последующей проверки других предикатов.
 Поисковый скан
Поисковый скан
Имеются также различия в статистике по времени и вводу/выводу.
Table 'Posts'. Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 156 ms.
Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 106 ms.
Помните, как это ломается для каждого предиката:
Но ни в каком случае нам не нужны все эти приблизительно 6 миллионов строк PostTypeId 1, чтобы выбрать нужный диапазон ClosedDates.
Снова путаница
Когда это меняется?
Когда мы спроектируем индексы несколько иначе.
CREATE NONCLUSTERED INDEX ix_ennui
ON dbo.Posts ( PostTypeId ) INCLUDE (ClosedDate);
CREATE NONCLUSTERED INDEX ix_morose
ON dbo.Posts ( ClosedDate ) INCLUDE (PostTypeId);
Выполняя те же самые запросы, замечаем существенные изменения в первом из них.
Table 'Posts'. Scan count 1, logical reads 16344, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 297 ms, elapsed time = 301 ms.
Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 187 ms.
Теперь остаточный предикат вредит нам, когда мы ищем диапазон значений.
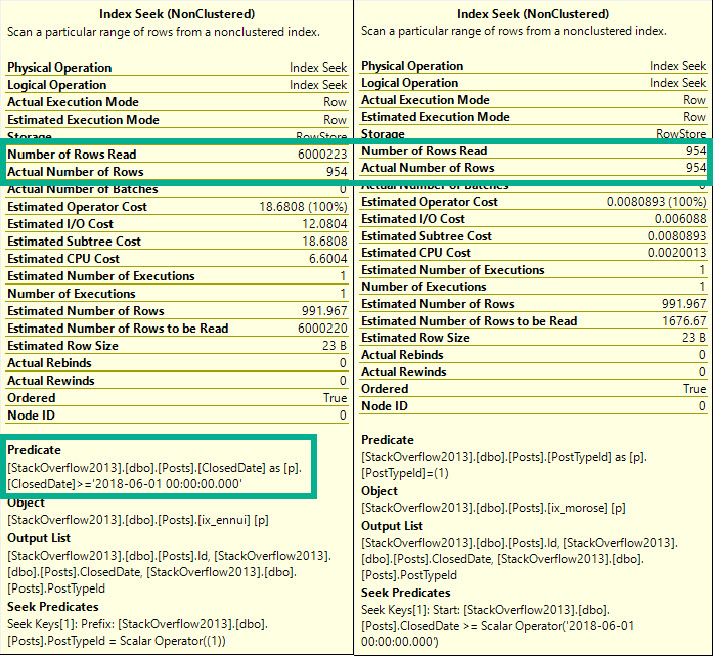
Мы получили множество лишних чтений - на сей раз нам действительно нужны все эти 6 миллионов строк с PostTypeId 1.
Ошибка на единицу
Иногда подобное также случается, если мы только переставим ключевые столбцы.
CREATE NONCLUSTERED INDEX ix_ennui
ON dbo.Posts ( PostTypeId, OwnerUserId, ClosedDate ) WITH ( DROP_EXISTING = ON );
CREATE NONCLUSTERED INDEX ix_morose
ON dbo.Posts ( ClosedDate, OwnerUserId, PostTypeId ) WITH ( DROP_EXISTING = ON );
Теперь у меня есть в ключе индекса оба столбца, которые требуются в запросе, но я вставил между ними столбец, который в запросе не нужен - OwnerUserId.
Это также отбрасывает предикат диапазона. Мы читаем здесь лишние 30К страниц, поскольку индекс стал больше.
Table 'Posts'. Scan count 1, logical reads 19375, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 312 ms, elapsed time = 314 ms.
Table 'Posts'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 178 ms.
Поиски выглядят здесь идентично тем, когда у меня были столбцы в разделе include индекса.
Что все это значит?
Расположение индексных столбцов, находятся ли они в ключе или в include, могут иметь немалое влияние на чтения, особенно при поиске диапазонов.
Даже если вы имеете неселективный первый столбец, подобный PostTypeId, с предикатом равенства на нем, вам не потребуется читать каждую отдельную строку, которая удовлетворяет фильтру, чтобы применить предикат диапазона, пока этот предикат является поисковым. Когда мы переносим столбец диапазона в Include, или когда добавляем столбец перед ним в ключе, нам приходится делать много лишней работы, чтобы найти нужные строки.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой