
Продвинутые возможности PostgreSQL: Руководство
Пересказ статьи Igor Bobriakov, Everett Berry. Advanced PostgreSQL Features: A Guide
Несмотря на растущую популярность баз данных NoSQL, реляционные базы данных все еще остаются предпочтительным выбором для многих приложений. Это связано с их развитыми запросами и надежностью.
Реляционные базы данных прекрасно себя ведут при выполнении сложных запросов и отчетов на базе данных, структура которых не изменяется часто. Реляционные базы данных с открытыми кодами, подобные MySQL и PostgreSQL, предоставляют альтернативу по цене-эффективности в качестве стабильных производственных баз данных лицензионным конкурентам типа Oracle, MSSQL и другим.
Если ваша организация активно работает с такой реляционной базой данных, вам следует ознакомиться с Arctype - совместимым с SQL редактором, который помогает визуализировать базу данных в виде электронной таблицы. Настоящая статья посвящена развитым возможностям PostgreSQL, свободно-распространяемой системой управления базами данных, которая ориентирована на расширяемость и соответствие стандарту SQL.
Уникальный набор возможностей PostgreSQL позволяет ее использовать как транзакционную базу данных или как хранилище данных. Блестящая поддержка транзакций и высокая производительность при записи делает ее идеальным кандидатом для выполнения рабочей OLTP-нагрузки. В то же время богатые встроенные функции, которые включают аналитические и оконные функции, позволяют использовать ее в качестве хранилища данных, которое может использоваться аналитиками для извлечения знаний.
Типы данных JSON и функции JSON в PostgreSQL позволяют выдерживать рабочие нагрузки NoSQL, используя PostgreSQL. Другой уникальной возможностью PostgreSQL является способность хранить геопространственные данные и выполнять к ним запросы. Эта возможность предоставляется плагином GIS. Полнотекстовый поиск в PostgreSQL помогает находить документы без использования сложных регулярных выражений. Помимо этого PostgreSQL также поддерживает много продвинутых особенностей, например, наследование схемы, неатомарные столбцы, представления и т.д. Ниже мы подробно рассмотрим эти возможности.
PostgreSQL поддерживает наследование, что позволяет пользователям создавать пустые таблицы, которые моделируют требуемые структуры. Представим, например, что в вашем варианте использования имеется таблица заказчиков и специфический тип заказчика с дополнительным полем с именем office_address. В базе данных, которая не поддерживает наследования, такая ситуация должна обрабатываться двумя отдельными таблицами в соответствии со следующими операторами DDL:
При наличии возможности наследования такая ситуация обрабатывается с помощью следующих операторов DDL:
Эти запросы создадут две таблицы, при этом таблица office_customers наследуется из главной таблицы customer.

Это помогает поддерживать чистоту схем, а также повышает производительность базы данных.
Давайте вставим теперь несколько записей, чтобы посмотреть как это работает.
Если вам нужно обратиться только к первой таблице, вы можете использовать ключевое слово ONLY. Вот так:
Будут получены такие результаты:

Если нужно вернуть записи из обеих таблиц, используйте запрос без ключевого слова ONLY.
Будет получен следующий результат:
Одно из основных ограничений реляционной модели состоит в том, что столбцы должны быть атомарными. PostgreSQL не имеет этого ограничения и позволяет столбцам иметь субзначения, к которым можно обратиться с помощью запросов.
Можно создать таблицы с полями типа массивов любого типа данных. Попробуйте создать таблицу с помощью следующего оператора:

В представленной выше таблице поле payment_schedule является массивом целых чисел. Каждое целое можно получить независимо, указав его индекс.
Вставьте несколько строк с помощью команд ниже:
Будет получен такой результат:

Результат:
Важная роль, которую играют оконные функции в PostgreSQL, делает их фаворитом в аналитических приложениях. Оконные функции помогают пользователям выполнять действия, охватывающие несколько строк и возвращающие такое же количество строк. Оконные функции отличны от агрегатных функций в том смысле, что последние могут вернуть только единственную строку после группировки.
Представьте, что у вас имеется таблица с именем сотрудника, его id, зарплатой и названием подразделения.
Давайте вставим туда некоторые данные.
Предположим, что вы хотите получить среднюю зарплату по подразделению, наряду с детализированными данными. Достичь этого вы можете с помощью следующего запроса:
Вывод:
Возможность хранить и запрашивать JSON позволяет PostgreSQL также выполнять рабочую нагрузку NoSQL. Предположим, что вы разрабатываете базу данных для хранения данных от различных датчиков и не заботитесь о конкретных столбцах, которые вам бы потребовались для поддержки всех типов датчиков. В этом случае вы можете спроектировать таблицу, чтобы один из столбцов был JSON для хранения неструктурированных или часто изменяющихся данных.
Вы можете затем вставить данные, используя следующий оператор:
PostgreSQL позволяет вам писать запросы к определенным полям в данных JSON с помощью следующей конструкции.
Функция полнотекстового поиска в PostgreSQL позволяет искать документы на базе слов, присутствующих в поле. Вы можете сказать, что любая база данных, которая поддерживает конструкцию LIKE способна делать это. Однако полнотекстовый поиск в PostgreSQL делает один шаг выше по сравнению с LIKE. Чтобы выполнить полный поиск слова с использованием LIKE, вам нужно будет использовать сложные регулярные выражения. С другой стороны, возможность полнотекстового поиска в PostgreSQL позволит выполнять поиск даже на основе корневых слов или лексемы. Ликсему лучше всего объяснить на примере.
Скажем, вы хотите найти документ со словом 'work'. Слово work может присутствовать в документе в нескольких формах, например, 'Working, works, worked' и т.д. Полнотекстовый поиск в PostgreSQL достаточно интеллектуален, чтобы учесть все подобные формы при поиске. Представьте себе затраты, если вы попытаетесь сделать это с использованием регулярных выражений и запросов LIKE. Давайте рассмотрим полнотекстовый поиск в действии.
Создадим таблицу LOG для хранения журналов ошибок.
Вставим теперь несколько значений ошибок с помощью следующих операторов:
Давайте теперь попробуем извлечь строки, которые содержат слово 'miss' с помощью полнотекстового поиска. Для этого потребуются две функции. Функция to_tsvector преобразует значения в их ликсемы, а функция to_tsquery будет сопоставлять слова.
Будет получен такой результат:

Обратите внимание, что запрос справился с возвращением строки, несмотря на то, что в описании фактически фигурировало слово 'missing', а не 'miss', для которого выполнялся поиск.
Полнотекстовый поиск доступен для различных локализаций. Следовательно, он может использоваться так же с множеством языков.
Представления можно рассматривать как виртуальные таблицы, которые отвечают заданным критериям. Например, предположим, что у вас есть таблица staff (штат) и таблица salary (зарплата). Общим ключом является id. Если ваш рабочий процесс требует часто соединять эти таблицы и анализировать их, вы можете определить представление с желаемым критерием. Это представление будет отражать все изменения в используемых таблицах и действовать как комбинированная таблица. Давайте рассмотрим примеры.
Создадим таблицы с помощью операторов DDL Ниже.
Вставим несколько записей с помощью следующих операторов:
Создадим представление с помощью следующего оператора:
Вы можете теперь выполнять запрос к представлению как к обычной таблице.
Вывод:

PostgreSQL с расширением GIS позволяет сохранять геометрические координаты и информацию о форме в таблицах. Особенным здесь является возможность выполнять запросы по этим координатам с помощью встроенных функций для вычисления расстояний, площади и т.п. Это делает PostgreSQL де факто выбором в тех случаях использования, когда на выходе или входе используются географические координаты и предъявляются высокие требования к обработке пространственных данных. Например, у нас есть геометрическая информация обо всех городах, и мы хотим узнать, какой город там находится. Это легко выполнить с помощью следующего запроса:
В результате мы получим название города, соответствующего переданным координатам.
PostgreSQL - общие варианты использования
Уникальный набор возможностей PostgreSQL позволяет ее использовать как транзакционную базу данных или как хранилище данных. Блестящая поддержка транзакций и высокая производительность при записи делает ее идеальным кандидатом для выполнения рабочей OLTP-нагрузки. В то же время богатые встроенные функции, которые включают аналитические и оконные функции, позволяют использовать ее в качестве хранилища данных, которое может использоваться аналитиками для извлечения знаний.
Типы данных JSON и функции JSON в PostgreSQL позволяют выдерживать рабочие нагрузки NoSQL, используя PostgreSQL. Другой уникальной возможностью PostgreSQL является способность хранить геопространственные данные и выполнять к ним запросы. Эта возможность предоставляется плагином GIS. Полнотекстовый поиск в PostgreSQL помогает находить документы без использования сложных регулярных выражений. Помимо этого PostgreSQL также поддерживает много продвинутых особенностей, например, наследование схемы, неатомарные столбцы, представления и т.д. Ниже мы подробно рассмотрим эти возможности.
PostgreSQL - продвинутые возможности
Наследование
PostgreSQL поддерживает наследование, что позволяет пользователям создавать пустые таблицы, которые моделируют требуемые структуры. Представим, например, что в вашем варианте использования имеется таблица заказчиков и специфический тип заказчика с дополнительным полем с именем office_address. В базе данных, которая не поддерживает наследования, такая ситуация должна обрабатываться двумя отдельными таблицами в соответствии со следующими операторами DDL:
CREATE TABLE CUSTOMERS (
name text,
age int,
address text
);
CREATE TABLE OFFICE_CUSTOMERS(
name text,
age int,
address text,
office_address text
);При наличии возможности наследования такая ситуация обрабатывается с помощью следующих операторов DDL:
CREATE TABLE CUSTOMERS (
name text,
age int,
address text
);
CREATE TABLE OFFICE_CUSTOMERS(
office_address text
) INHERITS (customer)Эти запросы создадут две таблицы, при этом таблица office_customers наследуется из главной таблицы customer.
Это помогает поддерживать чистоту схем, а также повышает производительность базы данных.
Давайте вставим теперь несколько записей, чтобы посмотреть как это работает.
INSERT INTO CUSTOMERS VALUES('ravi','32','32, head street');
INSERT INTO CUSTOMERS VALUES('michael','35','56, gotham street');
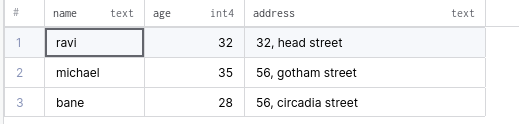
INSERT INTO OFFICE_CUSTOMERS VALUES('bane','28','56, circadia street','92 homebush');Если вам нужно обратиться только к первой таблице, вы можете использовать ключевое слово ONLY. Вот так:
SELECT * from ONLY CUSTOMER WHERE age > 20 ;Будут получены такие результаты:
Если нужно вернуть записи из обеих таблиц, используйте запрос без ключевого слова ONLY.
SELECT * from CUSTOMER WHERE age > 20 ;Будет получен следующий результат:
Неатомарные столбцы
Одно из основных ограничений реляционной модели состоит в том, что столбцы должны быть атомарными. PostgreSQL не имеет этого ограничения и позволяет столбцам иметь субзначения, к которым можно обратиться с помощью запросов.
Можно создать таблицы с полями типа массивов любого типа данных. Попробуйте создать таблицу с помощью следующего оператора:
CREATE TABLE customer (
name text,
Address text,
payment_schedule integer[],
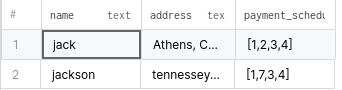
);В представленной выше таблице поле payment_schedule является массивом целых чисел. Каждое целое можно получить независимо, указав его индекс.
Вставьте несколько строк с помощью команд ниже:
INSERT INTO CUSTOMER_SCHEDULE VALUES( 'jack',
'Athens, Colarado',
'{1,2,3,4}'
)
INSERT INTO CUSTOMER_SCHEDULE VALUES( 'jackson',
'Tennessey, greece',
'{1,7,3,4}'
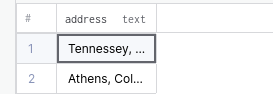
)Будет получен такой результат:
SELECT * FROM CUSTOMER_SCHEDULE WHERE
CUSTOMER_SCHEDULE.payment_schedule[1] <> CUSTOMER_SCHEDULE.payment_schedule[2];Результат:
Оконные функции
Важная роль, которую играют оконные функции в PostgreSQL, делает их фаворитом в аналитических приложениях. Оконные функции помогают пользователям выполнять действия, охватывающие несколько строк и возвращающие такое же количество строк. Оконные функции отличны от агрегатных функций в том смысле, что последние могут вернуть только единственную строку после группировки.
Представьте, что у вас имеется таблица с именем сотрудника, его id, зарплатой и названием подразделения.
CREATE TABLE employees (
empno int,
salary float,
division text
);Давайте вставим туда некоторые данные.
INSERT INTO employees VALUES(1,2456.7,'A')
INSERT INTO employees VALUES(2,10000.0,'A');
INSERT INTO employees VALUES(3,12000.0,'A');
INSERT INTO employees VALUES(4,2456.7,'B');
INSERT INTO employees VALUES(5,10000.0,'B');
INSERT INTO employees VALUES(6,10000.0,'C');
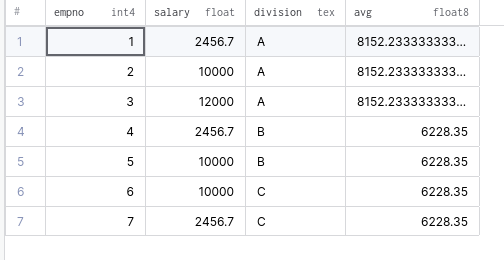
INSERT INTO employees VALUES(7,2456.7,'C');Предположим, что вы хотите получить среднюю зарплату по подразделению, наряду с детализированными данными. Достичь этого вы можете с помощью следующего запроса:
SELECT empno, salary, division,
avg(salary) OVER (PARTITION BY division) FROM EMPLOYEES;Вывод:
Поддержка данных JSON
Возможность хранить и запрашивать JSON позволяет PostgreSQL также выполнять рабочую нагрузку NoSQL. Предположим, что вы разрабатываете базу данных для хранения данных от различных датчиков и не заботитесь о конкретных столбцах, которые вам бы потребовались для поддержки всех типов датчиков. В этом случае вы можете спроектировать таблицу, чтобы один из столбцов был JSON для хранения неструктурированных или часто изменяющихся данных.
CREATE TABLE sensor_data (
id serial NOT NULL PRIMARY KEY,
data JSON NOT NULL
);Вы можете затем вставить данные, используя следующий оператор:
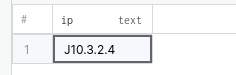
INSERT INTO sensor_data (data)
VALUES('{ "ip": "J10.3.2.4", "payload": {"temp": "33.5","brightness": "73"}}');PostgreSQL позволяет вам писать запросы к определенным полям в данных JSON с помощью следующей конструкции.
SELECT data->> 'ip' as ip from sensor_data; Полнотекстовый поиск
Функция полнотекстового поиска в PostgreSQL позволяет искать документы на базе слов, присутствующих в поле. Вы можете сказать, что любая база данных, которая поддерживает конструкцию LIKE способна делать это. Однако полнотекстовый поиск в PostgreSQL делает один шаг выше по сравнению с LIKE. Чтобы выполнить полный поиск слова с использованием LIKE, вам нужно будет использовать сложные регулярные выражения. С другой стороны, возможность полнотекстового поиска в PostgreSQL позволит выполнять поиск даже на основе корневых слов или лексемы. Ликсему лучше всего объяснить на примере.
Скажем, вы хотите найти документ со словом 'work'. Слово work может присутствовать в документе в нескольких формах, например, 'Working, works, worked' и т.д. Полнотекстовый поиск в PostgreSQL достаточно интеллектуален, чтобы учесть все подобные формы при поиске. Представьте себе затраты, если вы попытаетесь сделать это с использованием регулярных выражений и запросов LIKE. Давайте рассмотрим полнотекстовый поиск в действии.
Создадим таблицу LOG для хранения журналов ошибок.
CREATE TABLE log(
name text,
description text
);Вставим теперь несколько значений ошибок с помощью следующих операторов:
INSERT INTO LOG VALUES('ERROR1','Failed to retreive credentials');
INSERT INTO LOG VALUES('ERROR2','Fatal error. No records present. Please try again with a different value');
INSERT INTO LOG VALUES('ERROR3','Unable to connect. Credentials missing');Давайте теперь попробуем извлечь строки, которые содержат слово 'miss' с помощью полнотекстового поиска. Для этого потребуются две функции. Функция to_tsvector преобразует значения в их ликсемы, а функция to_tsquery будет сопоставлять слова.
SELECT * FROM LOG WHERE to_tsvector(description) @@ to_tsquery('miss'); Будет получен такой результат:
Обратите внимание, что запрос справился с возвращением строки, несмотря на то, что в описании фактически фигурировало слово 'missing', а не 'miss', для которого выполнялся поиск.
Полнотекстовый поиск доступен для различных локализаций. Следовательно, он может использоваться так же с множеством языков.
Представления в PostgreSQL
Представления можно рассматривать как виртуальные таблицы, которые отвечают заданным критериям. Например, предположим, что у вас есть таблица staff (штат) и таблица salary (зарплата). Общим ключом является id. Если ваш рабочий процесс требует часто соединять эти таблицы и анализировать их, вы можете определить представление с желаемым критерием. Это представление будет отражать все изменения в используемых таблицах и действовать как комбинированная таблица. Давайте рассмотрим примеры.
Создадим таблицы с помощью операторов DDL Ниже.
CREATE TABLE staff(
id int,
age int,
address text
);
CREATE TABLE salary(
sal_id int,
salary int,
division text
);Вставим несколько записей с помощью следующих операторов:
INSERT INTO STAFF VALUES(1,32,'michael');
INSERT INTO STAFF VALUES(2,32,'sarah');
INSERT INTO SALARY VALUES(1,18000,'A');
INSERT INTO SALARY VALUES(2,32000,'B');Создадим представление с помощью следующего оператора:
CREATE VIEW STAFF_SALARY_COMBINED AS (
SELECT *
FROM staff,salary
WHERE id=sal_id
);Вы можете теперь выполнять запрос к представлению как к обычной таблице.
SELECT * FROM STAFF_SALARY_COMBINED;Вывод:
Геопространственные данные в PostgreSQL
PostgreSQL с расширением GIS позволяет сохранять геометрические координаты и информацию о форме в таблицах. Особенным здесь является возможность выполнять запросы по этим координатам с помощью встроенных функций для вычисления расстояний, площади и т.п. Это делает PostgreSQL де факто выбором в тех случаях использования, когда на выходе или входе используются географические координаты и предъявляются высокие требования к обработке пространственных данных. Например, у нас есть геометрическая информация обо всех городах, и мы хотим узнать, какой город там находится. Это легко выполнить с помощью следующего запроса:
SELECT city.name
FROM burn_area, city
WHERE ST_Contains(burn_area.geom, city.geom)В результате мы получим название города, соответствующего переданным координатам.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой