
Правильный способ проверки на NULL в запросах SQL Server
Пересказ статьи Erik Darling. The Right Way To Check For NULLs In SQL Server Queries
Это все еще одна из наиболее общих проблем, которую я вижу в запросах.
Люди боятся NULL. Люди боятся сливаться на автострадах в Лос-Анджелесе.
В результате имеем бесконечный поток запросов с плохой производительностью, и некоторые неожиданные ошибки, обнаруживаемые по пути.
Я не могу ничего больше добавить в этом введении. Короче говоря, вы должны использовать естественные выражения типа IS NULL или IS NOT NULL, а не какие-либо встроенные функции, доступные вам в SQL Server, например, ISNULL, COALESCE и т.п., которые являются функциями слоя представления и не имеют реляционного смысла.
Отсюда и далее мы будем называть их неестественными выражениями. Возможно, так вам будет понятней.
Сначала о том, что я уже говорил ранее, но при использовании неестественных выражений оптимизатор не предоставит вам обратной связи о полезных индексах.

Первый запрос создает предложение по отсутствующему индексу, а второй - нет. Оптимизатор отказался от всякой надежды при использовании неестественного выражения.
Вторая проблема неестественных выражений связана с неявным преобразованием.
Возьмем, например.
Будет возвращена 1, поскольку 0 и '' могут быть неявно конвертированы.
Вот менее очевидный и более редкий пример:
Который тоже вернет 1.
Не много баз данных содержат данные, восходящие к 1900, но я вижу людей, довольно часто использующих это в качестве точки отсчета.
Если этого вам недостаточно, чтобы избавиться от такой идеи, давайте посмотрим, как все это происходит в реальном мире.
Давайте сначала создадим индекс. Без этого не будет фундаментальной разницы в производительности.
Нашим золотым стандартом будут эти два запроса:
Первый запрос, который проверяет на значения NULL возвращает число 182,348,084.
Второй, который проверяет значения NOT NULL возвращает число 344,070.
Запомните это.
Планы обоих запросов выглядят так:
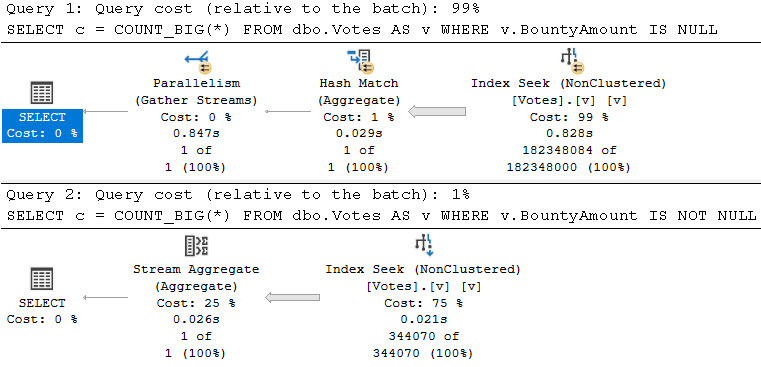
Запросы выполняются соответственно за 846мс и 26мс. Очевидно, что запрос с более селективным предикатом будет здесь иметь преимущество по времени.
Здесь начинаются ошибки.
Этот запрос возвращает неправильные результаты, но вы, вероятно, привыкли к этому из-за всех этих хинтов NOLOCK в ваших запросах.
Возвращаемое количество 182349088, а не 182348084, поскольку для 1004 строк bounty равно 0.
Хотя мы использовали пустую строку в наших запросах, она неявно конвертировалась в 0.

И ты думал, что такой умный.
В бесполезных упражнениях, которые выполняют люди, я часто наблюдаю использование выражений ISNULL, COALESCE и CASE.
Здесь стоит заметить, что COALESCE - это всего лишь стоящее за кадром выражение CASE.
Для нахождения NULL люди извернутся и сделают это:
Мы можем использовать здесь значение -1, поскольку оно не встречается в естественных данных. Результаты корректны в обоих случаях, но сравнительная производительность ужасна.
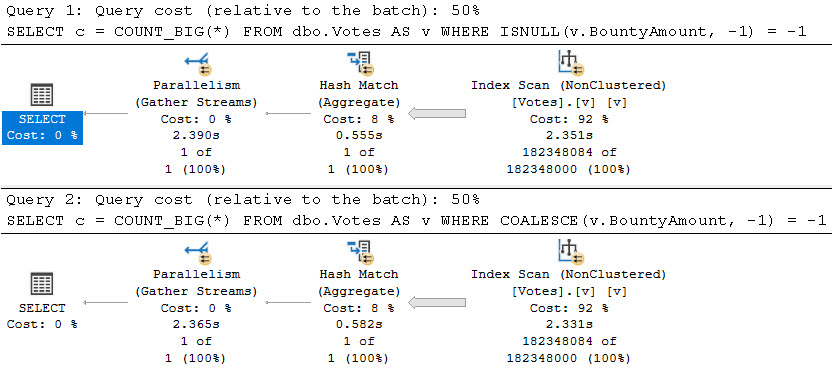
Мы видим 2,5 секунды против 900мс. Ситуация также становится хуже при более селективных предикатах.
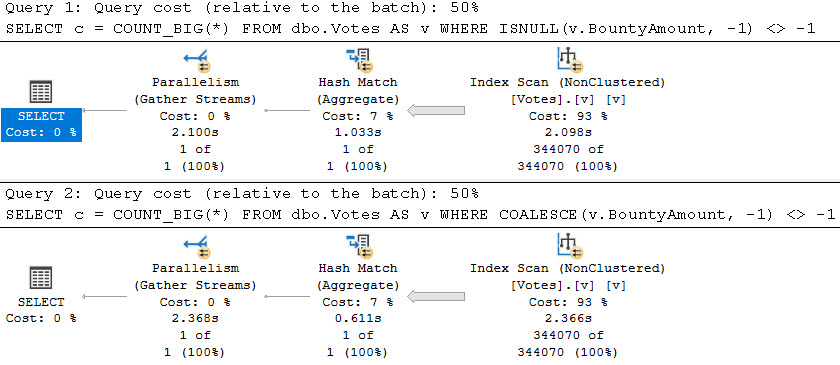
Они оба занимают примерно одинаковое время, что и другие неестественные формы этого запроса, но вызов естественной версии этого запроса завершится менее чем за 30мс.
Я надеюсь, что мне не придется об этом больше писать, но сейчас я вижу, как люди делают это, и уже начинаю в этом сомневаться.
Я не знаю, почему некоторые думают, что это хорошая идея. Ходят слухи, что это исходит от разработчиков приложений, которые привыкли к значениям NULL, вызывающим ошибки при написании SQL-запросов, в которых они не представляют такой же угрозы.
Кто знает. Может быть, людям просто нравится праздничный розовый цвет текста, которым окрашиваются функции в SSMS.
Отсюда и далее мы будем называть их неестественными выражениями. Возможно, так вам будет понятней.
Мастер настройки
Сначала о том, что я уже говорил ранее, но при использовании неестественных выражений оптимизатор не предоставит вам обратной связи о полезных индексах.
Первый запрос создает предложение по отсутствующему индексу, а второй - нет. Оптимизатор отказался от всякой надежды при использовании неестественного выражения.
Вторая проблема неестественных выражений связана с неявным преобразованием.
Возьмем, например.
DECLARE
@i int = 0;
SELECT
c =
CASE ISNULL(@i, '')
WHEN ''
THEN 1
ELSE 0
END;Будет возвращена 1, поскольку 0 и '' могут быть неявно конвертированы.
Вот менее очевидный и более редкий пример:
DECLARE
@d datetime = '19000101';
SELECT
c =
CASE ISNULL(@d, '')
WHEN ''
THEN 1
ELSE 0
END;Который тоже вернет 1.
Не много баз данных содержат данные, восходящие к 1900, но я вижу людей, довольно часто использующих это в качестве точки отсчета.
Если этого вам недостаточно, чтобы избавиться от такой идеи, давайте посмотрим, как все это происходит в реальном мире.
Давайте сначала создадим индекс. Без этого не будет фундаментальной разницы в производительности.
CREATE INDEX v ON dbo.Votes
(BountyAmount);Нашим золотым стандартом будут эти два запроса:
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.BountyAmount IS NULL;
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.BountyAmount IS NOT NULL;Первый запрос, который проверяет на значения NULL возвращает число 182,348,084.
Второй, который проверяет значения NOT NULL возвращает число 344,070.
Запомните это.
Планы обоих запросов выглядят так:
Запросы выполняются соответственно за 846мс и 26мс. Очевидно, что запрос с более селективным предикатом будет здесь иметь преимущество по времени.
Неправильно
Здесь начинаются ошибки.
Этот запрос возвращает неправильные результаты, но вы, вероятно, привыкли к этому из-за всех этих хинтов NOLOCK в ваших запросах.
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE ISNULL(v.BountyAmount, '') = '';Возвращаемое количество 182349088, а не 182348084, поскольку для 1004 строк bounty равно 0.
Хотя мы использовали пустую строку в наших запросах, она неявно конвертировалась в 0.
И ты думал, что такой умный.
Плохо
В бесполезных упражнениях, которые выполняют люди, я часто наблюдаю использование выражений ISNULL, COALESCE и CASE.
Здесь стоит заметить, что COALESCE - это всего лишь стоящее за кадром выражение CASE.
Для нахождения NULL люди извернутся и сделают это:
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE ISNULL(v.BountyAmount, -1) = -1;
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE COALESCE(v.BountyAmount, -1) = -1;Мы можем использовать здесь значение -1, поскольку оно не встречается в естественных данных. Результаты корректны в обоих случаях, но сравнительная производительность ужасна.
Мы видим 2,5 секунды против 900мс. Ситуация также становится хуже при более селективных предикатах.
Они оба занимают примерно одинаковое время, что и другие неестественные формы этого запроса, но вызов естественной версии этого запроса завершится менее чем за 30мс.
Я надеюсь, что мне не придется об этом больше писать, но сейчас я вижу, как люди делают это, и уже начинаю в этом сомневаться.
Я не знаю, почему некоторые думают, что это хорошая идея. Ходят слухи, что это исходит от разработчиков приложений, которые привыкли к значениям NULL, вызывающим ошибки при написании SQL-запросов, в которых они не представляют такой же угрозы.
Кто знает. Может быть, людям просто нравится праздничный розовый цвет текста, которым окрашиваются функции в SSMS.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой