
Порядок столбцов в индексах
Пересказ статьи Mike Byrd. Index Column Order – Be Happy!
Мне всегда было интересно, как SQL Server выбирает порядок столбцов в предлагаемых индексах. И недавно я просто не смог сопротивляться искушению проверить это. Рассмотрим запрос:
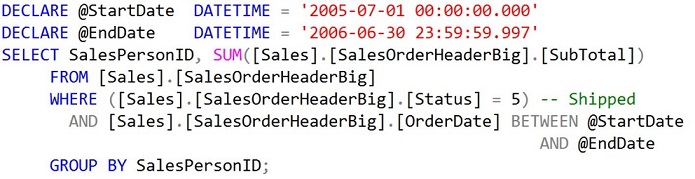 Базовый запрос
Базовый запрос
Здесь используется база данных AdventureWorks2012Big, которая была получена из базы AdventureWorks2012 с помощью скрипта Jonathan Kehayias, доступного по адресу. Этот скрипт добавляет две новые таблицы (Sales.SalesOrderHeaderBig и Sales.SalesOrderDetailBig) и увеличивает число строк в SalesOrderHeader с 31465 до 1290065. Фактически после исследования (когда я закончил черновой вариант) я обнаружил, что в обеих таблицы, Sales.SalesOrderHeader и Sales.SalesOrderHeaderBig, столбец Status содержит только одно значение 5 во всех строках. Используя генератор случайных чисел, я модифицировал столбец Status таблицы Sales.SalesOrderHeaderBig таким образом, чтобы он содержал примерно равное число значений в диапазоне от 0 до 9. Это, вероятно, более соответствует реальным данным. Вы можете найти соответствующий код в приложенном файле.
Этот запрос представляет собой типичный итоговый отчет, в котором в предложении WHERE используются столбцы Status и OrderDate. Если я выполню этот запрос с индексами, изначально имеющимися в adventureWorks2012Big, то, как видно из приведенного ниже плана запроса, получу сканирование кластеризованного индекса на adventureWorks2012Big, где кластеризованный индекс создан на первичном ключе SalesOrderID (столбец identity):

План запроса с оригинальными индексами
В результате имеем:
- стоимость запроса = 22.9441
- логические чтения = 30311
- cpu = 173мс
Отметим, что предложенный некластеризованный индекс определяется на Status, OrderDate со столбцами SalesPersonID, Subtotal, включенными в предложение INCLUDE. Это заставило меня задуматься о том, почему OrderDate не является первым. Все мы знаем (из общеприняных рекомендаций), что первым должен следовать наиболее селестивный столбец.
Итак, если я определю новый покрывающий индекс (как предлагается):
 Microsoft предложил покрывающий индекс
Microsoft предложил покрывающий индекс
Оптимизатор запросов не рекомендовал опцию Data_Compression, но из одного моего предыдущего блога я знаю, что это лучший вариант почти для всех индексов - кластеризованных и некластеризованных.
И снова выполняя тот же запрос, мы получим следующие результаты:
 План запроса с поиском в некластеризованном индексе на основе Status, OrderDate
План запроса с поиском в некластеризованном индексе на основе Status, OrderDate
Этот запрос дает:
- стоимость запроса = 0.563195
- логические чтения = 12
- cpu = 0мс
Ух ты; улучшение производительности в 40 раз (по стоимости)! Покрывающий индекс дает нам теперь поиск в индексе. Но я все еще интересуюсь порядком столбцов в определении индекса. Поэтому давайте удалим новый индекс и определим другой на основе OrderDate, Status, как показано ниже:
 Перестроенный некластеризованный индекс на основе OrderDate, Status
Перестроенный некластеризованный индекс на основе OrderDate, Status
Опять выполним тот же запрос. Теперь имеем
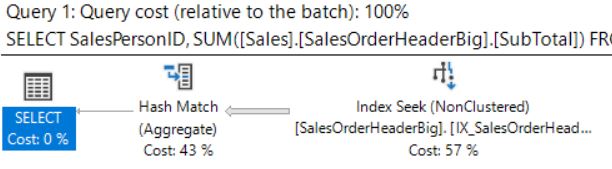 План запроса с некластеризованным индексом на основе OrderDate, Status
План запроса с некластеризованным индексом на основе OrderDate, Status
Этот запрос дает:
- стоимость запроса = 1.14707
- логические чтения = 72
- cpu = 15мс
Мы по-прежнему получаем поиск по индексу, но статистика по вводу/выводу и времени несколько ухудшилась, а стоимость плана запроса немного повысилась. Стоимость Index Seek подскочила с 31 до 57% от полной стоимости запроса. Почему так?
Если мы вернемся к плану запроса и переместим курсор мыши на оператор Index Seek в соответствующих планах первого, второго и третьего запросов, получим:
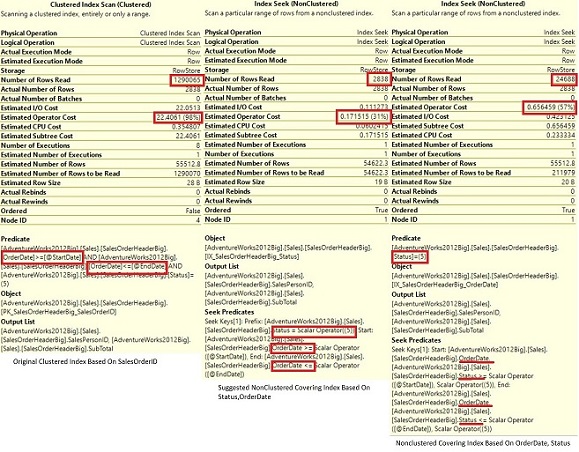 Свойства Index Seek в плане запроса для Index Scan и поисками в некластеризованном индексе (по порядку)
Свойства Index Seek в плане запроса для Index Scan и поисками в некластеризованном индексе (по порядку)
Можно получить интересные результаты из этих трех запросов. Главное отличие обнаруживается в первом запросе со сканированием кластерного индекса, в котором каждая строка таблицы проверяется на попадание в диапазон OrderDate и status = 5, что приводит к 30311 логических чтений (Predicate). Во втором запросе (рекомендуемый Майкрософт покрывающий некластеризованный индекс) вы имеете только предикат поиска (Seek Predicate), а во втором запросе со сканированием индекса у вас есть и Seek Predicate, и Predicate.
Так в чем же разница между Seek Predicate и Predicate в окне оператора? Seek Predicate сопровождается восстановлением данных, фильтрующим строки в пределах соответствующего индекса (действует почти как предложение WHERE). Predicate затем убирает строки в соответствии с заданным критерием. Поэтому, хотя тут имеется всего один оператор, Seek Predicate фильтрует строку во время чтения данных, после чего Predicate фильтрует результирующий набор по промежутку времени. Итак, в оригинальном сканировании кластеризованного индекса отсутствует Seek Predicate, поскольку требуется доступ к каждой строке. После чего Predicate фильтрует результирующий набор по промежутку времени на основании OrderDate и Status.
Во втором запросе, использующем предложенный покрывающий индекс, имеется только Seek Predicate. Оптимизатор принимает во внимание тот факт, что при заданном значении Status =5 OrderDate упорядочены по возрастанию в пределах индекса. Это не так в случае некластеризованного покрывающего индекса на основе OrderDate и Status соответственно. В этом случае имеем накрученное предложение "WHERE" на OrderDate и Status с последующей фильтрацией только по Status = 5. Вот почему результаты во втором запросе имеют только 12 логических чтений, в то время как третий запрос имеет 72 логических чтения из-за двойной фильтрации.
Итак, что случится, если я вернусь назад и перенесу OrderDate в предложение INCLUDE в IX_SalesOrderHeaderBig_Status, как это показано ниже (с очисткой некоторых индексов):
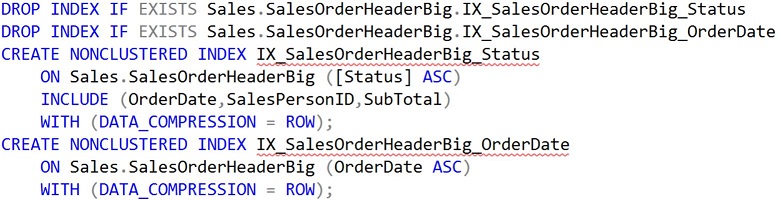 Перенос OrderDate в предложение INCLUDE
Перенос OrderDate в предложение INCLUDE
Этот новый индекс содержит те же столбцы, что и оригинальный предложенный индекс, но не позволяет оптимизатору воспользоваться упорядоченностью OrderDate. Выполнив тот же запрос, получим
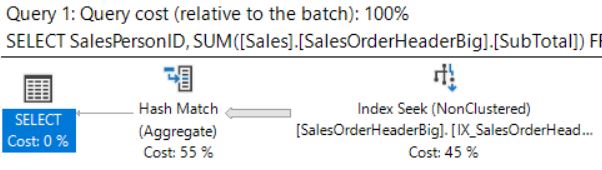 План запроса для некластеризованного индекса на базе Status
План запроса для некластеризованного индекса на базе Status
Этот запрос теперь имеет
- стоимость запроса = 0.919195
- логические чтения = 367
- cpu = 31мс
Если поместить курсор над оператором Index seek, увидим
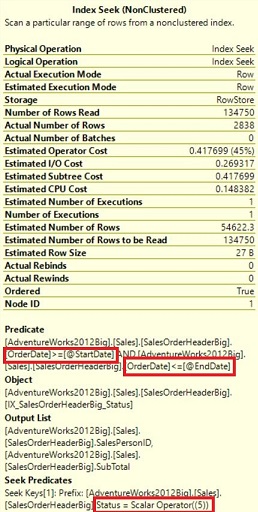 Свойства Index seek в плане выполнения для определения третьего индекса
Свойства Index seek в плане выполнения для определения третьего индекса
Мы снова имеем разбиение на Predicate и Seek Predicate, но теперь Seek Predicate основывается только на столбце Status, а Predicate - на столбце OrderDate. В этом случае производительность лучше, чем оригинальное сканирование кластеризованного индекса, но не предложенного покрывающего индекса.
Часто меня спрашивают, какие столбцы включать в определение индекса. Я обычно отвечаю в духе Майкрософт: "Это зависит!", но в данных случаях это действительно зависит от данных, сценария и того, сможет ли оптимизатор воспользоваться упорядоченностью второго (и, возможно, третьего, если он есть) столбца.
Изначально общие результаты показались мне противоречащими интуиции, т.к. я думал, что OrderDate являлся более селективным столбцом. Но очевидно упорядочение OrderDate в индексе, предложенном оптимизатором привело к меньшему числу логических чтений, как было показано. В любом случае все три некластеризованных покрывающих индекса приводили к улучшению производительности (меньше логических чтений) по сравнению с оригинальным сканированием кластеризованного индекса. Но только то, что вы построили покрывающий индекс, не обязательно означает лучший вариант. Тестирование всегда должно предшествовать реализации.
Следует прокомментировать мой параметр DATA_COMPRESSION = ROW в определении трех индексов. Мой опыт в сжатии данных показал много преимуществ и почти никаких недостатков использования сжатия данных строк, поскольку данные сжимаются полностью с жесткого диска в буферный кэш, в кэш процессора L3 и, наконец, сжимаются/распаковываются в кэше процессора L2. Сжатие данных появилось в редакции SS2008 Enterprise Edition, а теперь в SS2016 SP2 Standard Edition и выше.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой