
Получение результатов, используя меньше кода T-SQL
Пересказ статьи Edward Pollack. Getting results using less T-SQL
Пытаясь решить проблемы с данными, которые организация нам перекидывает, зачастую легко запутаться в больших сложных запросах. Несмотря на окупаемость усилий по написанию лаконичного, легко читаемого и поддерживаемого кода T-SQL, иногда необходимость просто быстро получить набор данных приводит к созданию пугающего кода, которого лучше избегать, чем использовать.
В этой статье рассматривается несколько шаблонов запросов, которые могут оказаться полезными при попытке упростить беспорядочный код, а также и улучшить производительность запроса одновременно с улучшением его обслуживания!
Проблемы
Не существует единственной проблемы, которую можно было бы тут решить. Вместо этого будет представлено несколько вызывающих раздражение фрагментов T-SQL, а также несколько менее пугающих альтернатив. Надеюсь, что эта дискуссия не только даст несколько полезных решений общих проблем баз данных, но и предоставит некоторое общее руководство для написания более чистого и более эффективного кода, которое можно распространить на другие приложения.
Замечу, что все демонстрационные примеры используют учебную базу данных WideWorldImporters от Microsoft.
Множество предложений WHERE
Часто необходимо, особенно в отчетах, извлечь множество метрик из единственной таблицы. Это может использоваться в ежедневном отчете о состоянии дел, на информационной панели или в каком-либо другом сценарии, где необходимо собрать сведения о каком-либо объекте. Вот пример кода, который собирает различные метрики, связанные с заказами:
SELECT
COUNT(*) AS TotalOrderCount
FROM Sales.Orders
WHERE OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';
SELECT
COUNT(*) AS PickingNotCompleteCount
FROM Sales.Orders
WHERE PickingCompletedWhen IS NULL
AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';
SELECT
COUNT(*) PickedPersonUndefined
FROM Sales.Orders
WHERE PickedByPersonID IS NULL
AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';
SELECT
COUNT(DISTINCT CustomerID) AS CustomerCount
FROM Sales.Orders
WHERE PickedByPersonID IS NULL
AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';
SELECT
COUNT(*) AS ArrivingInThreeDaysOrMore
FROM Sales.Orders
WHERE DATEDIFF(DAY, OrderDate, ExpectedDeliveryDate) >= 3
AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';Каждый из этих запросов выполняет единственное вычисление над данным заказов за указанный интервал времени. Таковы общие требования к отчетности. Получаются следующие результаты:
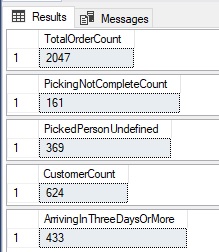
Это длинный фрагмент кода, в котором много строк повторяется в каждом запросе. Если потребуется изменить логику запроса, это приведет к необходимости вносить изменения в каждый из пяти представленных здесь запросов. Что касается производительности, то каждому запросу требуется отдельный индекс для эффективного выполнения вычислений. Некоторые используют поиск по индексу, другие - сканирование индекса. В общем операции ввода/вывода для этих запросов выглядят так:
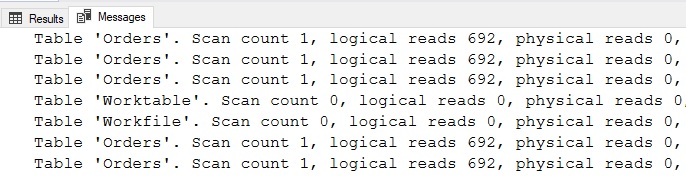
Всего требуется 3460 чтений, чтобы извлечь результаты с помощью двух сканирований кластеризованного индекса и трех поисков. Несмотря на то, что предложение WHERE меняется от запроса к запросу, все же возможно соединить эти отдельные запросы в единственный запрос, который один раз получает доступ к соответствующей таблице, а не пять раз. Это может быть выполнено при использовании агрегатных функций, например, так:
SELECT
COUNT(*) AS TotalOrderCount,
SUM(CASE WHEN PickingCompletedWhen IS NULL THEN 1 ELSE 0 END)
AS PickingNotCompleteCount,
SUM(CASE WHEN PickedByPersonID IS NULL THEN 1 ELSE 0 END)
AS PickedPersonUndefined,
COUNT(DISTINCT CustomerID) AS CustomerCount,
SUM(CASE WHEN DATEDIFF(DAY, OrderDate, ExpectedDeliveryDate) >= 3
THEN 1 ELSE 0 END) AS ArrivingInThreeDaysOrMore
FROM Sales.Orders
WHERE OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';Представленный код возвращает те же результаты в одном операторе, в не в пяти, путем замены большего количества строк кода на более сложный код в предложении SELECT:

В этом конкретном сценарии запрос имеет лучшую производительность, требуя одно сканирование вместо двух сканирований и трех поисков. Теперь ввод/вывод выглядит так:

Производительность набора запросов, которые объединены с помощью этого метода, будет обычно отражать производительность худшего из запросов в пакете. Это не всегда является оптимизацией, но, соединяя многие вычисления в единый оператор, можно добиться эффективности (иногда). Всегда тестируйте производительность изменения кода, чтобы гарантировать, что новые версии будут приемлемо эффективными как с точки зрения продолжительности выполнения запроса, так и с точки зрения потребления ресурсов.
Главным преимуществом этого рефакторинга является то, что получение результатов требует меньше кода T-SQL. Другое преимущество заключается в том, что добавление и удаление вычислений может быть выполнено простым добавлением или удалением той или иной строки в предложении запроса SELECT. Обслуживание единого запроса может быть проще, чем обслуживание по одному запросу на вычисление. Улучшится при этом производительность или нет зависит от соответствующих запросов и структуры таблиц. Тщательно тестируйте изменения, чтобы гарантировать, что они на самом деле помогают (а не вредят) производительности.
Дополнительное замечание относительно использования DISTINCT. Возможен COUNT DISTINCT для подмножества строк с помощью подобного синтаксиса:
SELECT
COUNT(DISTINCT CASE WHEN PickingCompletedWhen IS NOT NULL
THEN CustomerID ELSE NULL END) AS CustomerCountForPickedItems
FROM Sales.Orders
WHERE OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016';Это выглядит несколько неуклюже, но позволяет подсчитать уникальных заказчиков, но только когда удовлетворяется конкретное условие. В этом случае, когда PickingCompletedWhen IS NOT NULL.
Управление дубликатами
Нахождение (и обработка) нежелательных дубликатов является довольно общей задачей в области данных. Не все таблицы имеют ограничения, ключи или триггеры, и в связи с этим возникает вопрос - как наиболее просто обнаружить дубликаты.
Следующий пример показывает небольшой набор данных заказчиков и числе заказов за определенную дату:
CREATE TABLE #CustomerData
( OrderDate DATE NOT NULL,
CustomerID INT NOT NULL,
OrderCount INT NOT NULL);
INSERT INTO #CustomerData
(OrderDate, CustomerID, OrderCount)
VALUES
('4/14/2022', 1, 100), ('4/15/2022', 1, 50),
('4/16/2022', 1, 85), ('4/17/2022', 1, 15),
('4/18/2022', 1, 125), ('4/14/2022', 2, 2),
('4/15/2022', 2, 8), ('4/16/2022', 2, 7),
('4/17/2022', 2, 0), ('4/18/2022', 2, 12),
('4/14/2022', 3, 25), ('4/15/2022', 3, 18),
('4/16/2022', 3, 38), ('4/17/2022', 3, 44),
('4/18/2022', 3, 10), ('4/14/2022', 4, 0),
('4/15/2022', 4, 0), ('4/16/2022', 4, 1),
('4/17/2022', 4, 3), ('4/18/2022', 4, 0),
('4/14/2022', 5, 48), ('4/15/2022', 5, 33),
('4/16/2022', 5, 59), ('4/17/2022', 5, 24),
('4/18/2022', 4, 90);Эти данные были выбраны из систем заказов и требуют проверки на дубликаты на основе даты заказа и заказчика. Ограничение уникальности не является идеальным решением на этой таблице, т.к. это препятствовало бы дальнейшему анализу. Напротив, проверка происходит постфактум, чтобы можно было контролировать то, как выводить дубликаты и как ими управлять.
Например, предположим, что при обнаружении дубликатов один с наибольшим числом заказов остается, а остальные устраняются. Имеется множество способов нахождения строк-дубликатов. Например, данные могут агрегироваться по OrderDate и CustomerID:
SELECT
OrderDate,
CustomerID,
COUNT(*) AS Row_Count
FROM #CustomerData
GROUP BY OrderDate, CustomerID
HAVING COUNT(*) > 1;Это определяет единственную пару OrderDate/CustomerID с дубликатами:
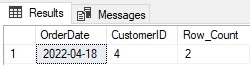
После обнаружения любые лишние строки требуется удалить, что требует отдельного запроса на удаление. В наиболее общих методах удаления дубликатов требуется два различных этапа:
- Обнаружение дубликатов
- Удаление дубликатов
Имеется альтернативный метод, который требует единственного этапа для выполнения работы:
WITH CTE_DUPES AS (
SELECT
OrderDate,
CustomerID,
ROW_NUMBER() OVER (PARTITION BY OrderDate, CustomerID
ORDER BY OrderCount DESC) AS RowNum
FROM #CustomerData)
DELETE
FROM CTE_DUPES
WHERE RowNum > 1;Использование общего табличного выражения в сочетании с оконной функцией ROW_NUMBER позволяет идентифицировать дубликаты в CTE, и тут же удалить их в том же операторе. Ключом в этом синтаксисе является использование столбцов, по которым определяются дубликаты, в предложении PARTITION BY. Предложение ORDER BY определяет, какую строку следует оставить (номер строки = 1), а какие строки - удалить (номера строк > 1). Замена DELETE на SELECT * позволяет легко проверить результаты и убедиться, что отброшены будут правильные строки.
Помимо упрощения, которое в противном случае может иметь место для сложного T-SQL, этот синтаксис хорошо масштабируется при увеличении сложности логики дубликатов. Если для определения дубликатов требуется больше столбцов или если определение удаляемых строк требует множества столбцов, каждый из этих сценариев может быть реализован добавлением столбцов в каждую часть оконной функции ROW_NUMBER.
Генерация кода и списка с помощью динамического SQLв SQL Server
Инструмент, который часто называют сложным для документирования, чтения или обслуживания, динамический SQL, может позволить существенно упростить код при эффективном использовании. Хорошим примером может послужить генерация T-SQL. Посмотрите код, который выполняет задачу обслуживания на каждой пользовательской базе данных, такую как выполнение полной резервной копии перед развертыванием основного ПО. Наиболее общим решением для этого может стать один из этих фрагментов кода:
-- Решение 1:
BACKUP DATABASE [AdventureWorks2017]
TO DISK = 'D:\ReleaseBackups\AdventureWorks2017.bak';
BACKUP DATABASE [AdventureWorksDW2017]
TO DISK = 'D:\ReleaseBackups\AdventureWorksDW2017.bak';
BACKUP DATABASE [WideWorldImporters]
TO DISK = 'D:\ReleaseBackups\WideWorldImporters.bak';
BACKUP DATABASE [WideWorldImportersDW]
TO DISK = 'D:\ReleaseBackups\WideWorldImportersDW.bak';
BACKUP DATABASE [BaseballStats]
TO DISK = 'D:\ReleaseBackups\BaseballStats.bak';
BACKUP DATABASE [ReportServer]
TO DISK = 'D:\ReleaseBackups\ReportServer.bak';
-- Решение 2
DECLARE DatabaseCursor CURSOR FOR
SELECT databases.name
FROM sys.databases
WHERE name NOT IN ('master', 'model', 'MSDB', 'TempDB');
OPEN DatabaseCursor;
DECLARE @DatabaseName NVARCHAR(MAX);
DECLARE @SqlCommand NVARCHAR(MAX);
FETCH NEXT FROM DatabaseCursor INTO @DatabaseName;
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @SqlCommand = N'
BACKUP DATABASE [' + @DatabaseName + ']
TO DISK = ''D:\ReleaseBackups\' + @DatabaseName + '.bak'';';
EXEC sp_executesql @SqlCommand;
FETCH NEXT FROM DatabaseCursor INTO @DatabaseName;
END
CLOSE DatabaseCursor;
DEALLOCATE DatabaseCursor;Первое решение использует имена баз данных непосредственно в операторах backup. Несмотря на простоту, такой подход требует ручного обслуживания при каждом добавлении или удален базы данных; этот код требует обновления, чтобы быть уверенным в правильном резервировании всех баз. Для серверов с большим числом баз данных это приведет к очень большому объему кода, который нужно обслуживать.
Второе решение использует курсор для обхода баз данных, резервируя их по одной. Это решение динамическое, оно гарантрует полный список баз данных для резервирования, но использует курсор и итерации для выполнения множества резервных копий. Хотя это более масштабируемое решение, оно все же несколько громоздко и опирается на курсор или цикл WHILE для учета каждой базы данных.
Рассмотрим альтернативное решение:
DECLARE @SqlCommand NVARCHAR(MAX) = '';
SELECT @SqlCommand = @SqlCommand + N'
BACKUP DATABASE [' + name + ']
TO DISK = ''D:\ReleaseBackups\' + name + '.bak'';'
FROM sys.databases
WHERE name NOT IN ('master', 'model', 'MSDB', 'TempDB');
EXEC sp_executesql @SqlCommand; В этом примере динамический SQL строится непосредственно из sys.databases, позволяя в одном операторе T-SQL сгенерировать полный список команд резервирования, которые затем немедленно выполняются в одном пакете. Это быстро, эффективно и T-SQL меньшего размера является менее сложным, чем предыдущий пример динамического SQL, и более простым для обслуживания, чем жестко закодированный список бэкапов. Этот код сам по себе не ускоряет процессы создания резервных копий, но уменьшает накладные расходы на их обслуживание.
Аналогичным образом могут генерироваться списки. Например, если разделенный запятыми список имен потребовался в интерфейсе пользователя, он мог бы генерироваться с помощью подобного метода:
DECLARE @MyList VARCHAR(MAX) = '';
SELECT
@MyList = @MyList + FullName + ','
FROM Application.People
WHERE IsSystemUser = 1
AND IsSalesperson = 1;
IF LEN(@MyList) > 0
SELECT @MyList = LEFT(@MyList, LEN(@MyList) - 1);
SELECT @MyList;Результаты в переменной @MyList выглядят следующим образом:

Ничего исключительного, но удобна возможность генерировать список без итерактивного цикла и без громоздкого кода T-SQL. Обратим внимание, что последние две строк кода служат для удаления концевой запятой, если список не пуст.
Как альтернатива, для построения списка может использоваться STRING_AGG, например:
SELECT
STRING_AGG(FullName,',')
FROM Application.People
WHERE IsSystemUser = 1
AND IsSalesperson = 1; Еще меньше кода! Снтаксис динамического SQL будет иметь преимущество в гибкости, если необходимо выполнять некоторые манипуляции со строками, но STRING_AGG дает самое минималистское решение из возможных.
Генерация списка с помощью динамического SQL зачастую будет эффективным и простым способом либо для отображения данных в компактном формате, либо для выполнения операторов T-SQL массово посредством метаданных, хранящихся в пользовательской таблице или системном представлении. Это тот сценарий, когда динамический SQL может упростить обслуживане, а также уменьшить количество кода, который требуется поддерживать, в хранимых процедурах, PowerShell или файлах скриптов.
Одновременное чтение и запись данных с помощью OUTPUT
Приложения обычно требуют, чтобы записанные транзакционные данные тут же возвращались и использовались. Классическая тактика в этом случае выглядит так:
- Модификация данных.
- Определение данных, которые был изменены, с использованием временных таблиц, SCOPE_IDENTITY(), операторов SELECT с целевыми фильтрами, или какой-нибудь другой процесс.
- Использование информации шага 2 для возврата любых измененных данных, которые требуются приложению.
Хотя и функционально корректный, этот процесс требует множественного доступа к транзакционным данным, чтобы записать их, а затем извлечь только что записанные строки. Предложение OUTPUT позволяет захватить измененные данные в том же самом операторе T-SQL, который модифицировал их. Следующий пример представляет собой оператор UPDATE, который использует OUTPUT для извлечения некоторых метаданных о строках, которые были обновлены в инвентарной таблице:
CREATE TABLE #StockItemIDList
(StockItemID INT NOT NULL PRIMARY KEY CLUSTERED);
UPDATE StockItemHoldings
SET BinLocation = 'Q-1'
OUTPUT INSERTED.StockItemID
INTO #StockItemIDList
FROM warehouse.StockItemHoldings
WHERE BinLocation = 'L-3';
SELECT * FROM #StockItemIDList;
DROP TABLE #StockItemIDList;Оператор UPDATE достаточно простой, он обновляет местоположение элемента на новое. Добавленное предложение OUTPUT берет ID всех обновленных строк и вставляет их во временную таблицу. Это позволяет выполнять дальнейшие действия с информацией обновленных строк без необходимости снова выяснять, какие данные были изменены.
INSERTED и DELETED ведут себя подобным образом для этих таблиц, как он используются в триггерах; и к ним обеим можно свободно обращаться в OUTPUT. Этот пример иллюстрирует, как столбец каждой из них может возвращаться вместе как часть UPDATE:
CREATE TABLE #StockItemIDList
(StockItemID INT NOT NULL PRIMARY KEY CLUSTERED,
LastEditedWhen DATETIME2(7) NOT NULL);
UPDATE StockItemHoldings
SET BinLocation = 'L-3'
OUTPUT INSERTED.StockItemID,
DELETED.LastEditedWhen
INTO #StockItemIDList
FROM warehouse.StockItemHoldings
WHERE BinLocation = 'Q-1';
SELECT * FROM #StockItemIDList;
DROP TABLE #StockItemIDList;Результаты, переносимые во временную таблицу, выглядят следующим образом:
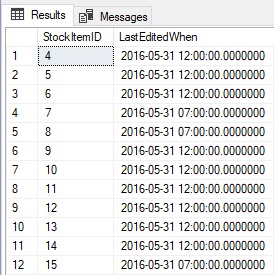
Вышк представлены ID для каждой обновленной строки, а также время последнего обновления ДО ТОГО, как был выполнен оператор. Возможность доступа одновременно к обеим таблицам INSERTED и DELETED при обновлении данных может сэкономить время и обем кода T-SQL. Как и в случае триггеров, оператор DELETE может осмысленно обращаться только к таблице DELETED, в то время как оператор INSERT - только к таблице INSERTED.
Давайте на минутку рассмотрим альтернативное решение:
CREATE TABLE #StockItemIDList
(StockItemID INT NOT NULL PRIMARY KEY CLUSTERED);
DECLARE @LastEditedWhen DATETIME2(7) = GETUTCDATE();
UPDATE StockItemHoldings
SET BinLocation = 'Q-1',
LastEditedWhen = @LastEditedWhen
FROM warehouse.StockItemHoldings
WHERE BinLocation = 'L-3';
INSERT INTO #StockItemIDList
(StockItemID)
SELECT
StockItemID
FROM warehouse.StockItemHoldings
WHERE BinLocation = 'Q-1';
-- Или альтернативно WHERE LastEditedWhen = @LastEditedWhenЭто немного длиннее и требует двойного обращения к таблице StockItemHoldings, сначала для обновления данных, а затем для получения информации об этих данных.
OUTPUT удобен и позволяет модифицировать данные одновременно с получением подробной информации об этих изменениях. Это позволит сократить время, ресурсы и даст более простой код, который легче читать и обслуживать. Это может быть не всегда лучшим решением, но может обеспечить дополнительное средство и упростить код, если не существует других альтернатив таких же ясных, как это.
Некоторые полезные динамическе административные представления
Можно было бы легко написать целые книги о том, как использовать динамические административные представления управления, поэтому я остановлюсь на нескольких простых, удобных в использовании и содержащих информацию, которую в противном случае было бы сложно получить в SQL Server:
SELECT * FROM sys.dm_os_windows_info
SELECT * FROM sys.dm_os_host_info
SELECT * FROM sys.dm_os_sys_info Они предоставляют некоторые базовые данные о Windows и хосте, на котором работает SQL Server:
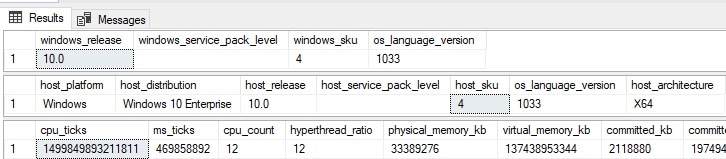
Если вам нужно быстро получить ответ о хосте Windows или его использовании, имеются замечательные представления для получения ответов. Это представление дает подробности о службах SQL Server:
SELECT * FROM sys.dm_server_servicesСюда включены SQL Server, SQL Server Agent, а также любые другие службы, которые управляются непосредственно SQL Server (например, полнотекстовое индексирование):

Более удобно собирать информацию с помощью запроса, а не посредством пользовательского интерфейса. Это особенно ценные данные, т.к. любой из этих столбцов содержит информацию, которую в противном случае пришлось бы собирать по многим серверам. Учетная запись службы может использоваться для ответа на вопросы аудита или проверки, что эти службы сконфигурированы правильно. Так же полезно знать время последнего запуска для понимания периода безотказной работы, обслуживания или неожиданных перезапусков.
Это DMV перечисляет параметры реестра для данного экземпляра SQL Server:
SELECT * FROM sys.dm_server_registryРезультаты могут быть длинными, но возможность быстро собирать и анализировать эти данные может дать огромную экономию времени при исследовании конфигурационных установок сервера:
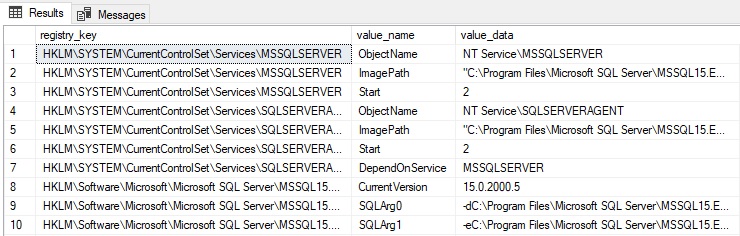
Альтернативы в использовании UI или некоторых дополнительных скриптов для чтения этих значений довольно хлопотны, а это динамическое представление дает большое дополнительное удобство! Заметьте, что здесь документируются только записи реестра, связанные с экземпляром SQL Server. Они включают номера портов, параметры выполнения и детали конфигурации сети.
Наконец, представление, которое также дает некоторые подробности уровня ОС, которые в противном случае получить затруднительно:
SELECT
master_files.name,
master_files.type_desc,
master_files.physical_name,
master_files.size,
master_files.max_size,
master_files.growth,
dm_os_volume_stats.volume_mount_point,
dm_os_volume_stats.total_bytes,
dm_os_volume_stats.available_bytes
FROM sys.master_files
CROSS APPLY sys.dm_os_volume_stats(master_files.database_id,
master_files.file_id);Dm_os_volume_stats возвращает информацию о точках монтирования тома, их общее/доступное пространство и многое другое:

Эти результаты являются прекрасным способом проверить установки размера и приращения для каждого файла базы данных на этом SQL Server, а также общие детали точки монтирования тома. В этом представлении много больше столбцов, которые могут оказаться полезными в зависимости от требуемой информации. Чтобы получить представление об их содержимом, выполните SELECT *.
Получение результатов с меньшим колчеством кода T-SQL
Лучшй итог этой дискуссии состоит в том, что существует много способов решить задачу в SQL Server. Некоторые из этих методов будут быстрее, более надежными и/или требовать меньше вычислительных ресурсов. Погружаясь в код, не торопитесь и посмотрите вокруг в поисках лучшего способа выполнить сложную задачу. Вполне возможно, что новая версия, service pack или даже CU SQL Server содержит фукнцию, которая сделает вашу жизнь существенно легче (какая-нибудь DATEFROMPARTS? А что насчет STRING_SPLIT?). Надеюсь, что советы этой статьи сделают вашу жизнь немного легче.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой