
Получение максимального значения на группу в SQL Server: Row Number против Cross Apply
Пересказ статьи Erik Darling. Getting The Top Value Per Group In SQL Server Row Number vs. Cross Apply
Введение
Существует много способов написания запросов в SQL Server. То, как будут выполняться различные варианты записи запроса, будет в значительной степени зависеть от:
- Вы не делаете ничего странного.
- Правильные индексы для запроса имеются.
- Оптимизатор не замечает ваших трюков и дает вам один и тот же план запроса.
Первое правило перезаписанных запросов заключается в том, что они, конечно, должны давать одинаковые результаты. Различие в логике.
Я собираюсь сравнить пару различных сценариев получения топового значения.
Конечно, имеются и другие способы написания такого рода запросов, но я хочу показать вам наиболее распространенные анти-шаблоны, которые я наблюдаю, и наиболее общее решение, которое заставит их работать лучше.
Здесь мы собираемся использовать такой индекс:
Который собирается оказать этому запросу надлежащую поддержку. Конечно, мы могли бы также добавить индекс в таблицу Users, но одно сканирование тривиально быстро, и, вероятно, тут ничего не выиграешь.
Основная идея состоит в нахождении всех пользователей с репутацией свыше 50000, а также их публикации с наивысшим баллом.
Я знаю, вы смотрите на это и думаете: "Господи, Эрик, почему ты выбираешь здесь *? Не знаешь, как это глупо?"
Ну, SQL Server достаточно умен, чтобы игнорировать это, и он будет иметь дело только со столбцами во внешнем select.
Если вы создали индекс и выполнили запрос, план запроса будет выглядеть примерно так:
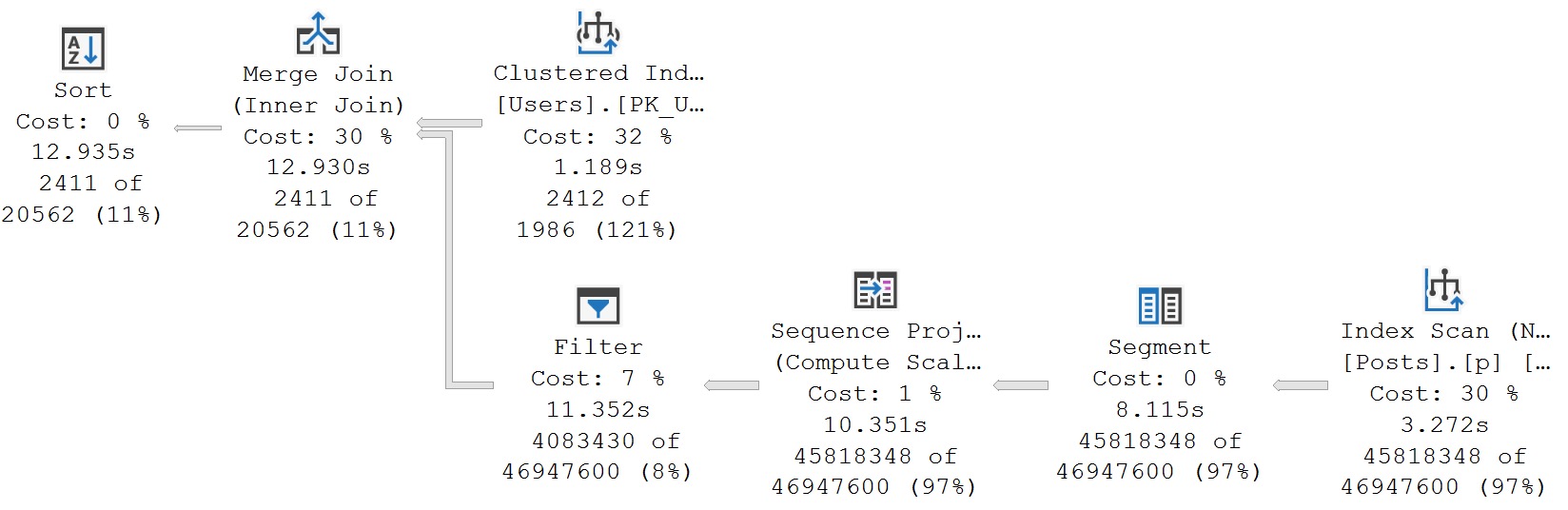
Главные затраты времени в этом плане - это ~11 секунд между сканированием таблицы Posts и оператором Filter.
Фильтр нужен здесь, чтобы удалить строки, для которых результат функции ROW_NUMBER больше 1.
Могу предположить, что вы скажете также и меньше 1, но ROW_NUMBER, естественно, не может произвести строки с 0 или отрицательными числами. Вам следует делать это при помощи вычитания.
Поскольку только ~2400 строк выходят из таблицы Users, и мы имеем хороший индекс на таблице Posts, то хотим получить тут преимущество.
Вместо сканирования всей таблицы Posts, генерации ROW_NUMBER, применения фильтра с последующим соединением, мы можем использовать CROSS APPLY, чтобы перенести все туда, где мы касаемся таблицы Posts.
Это логически эквивалентно, но отличается в производительности.
Вот план для запроса с cross apply:
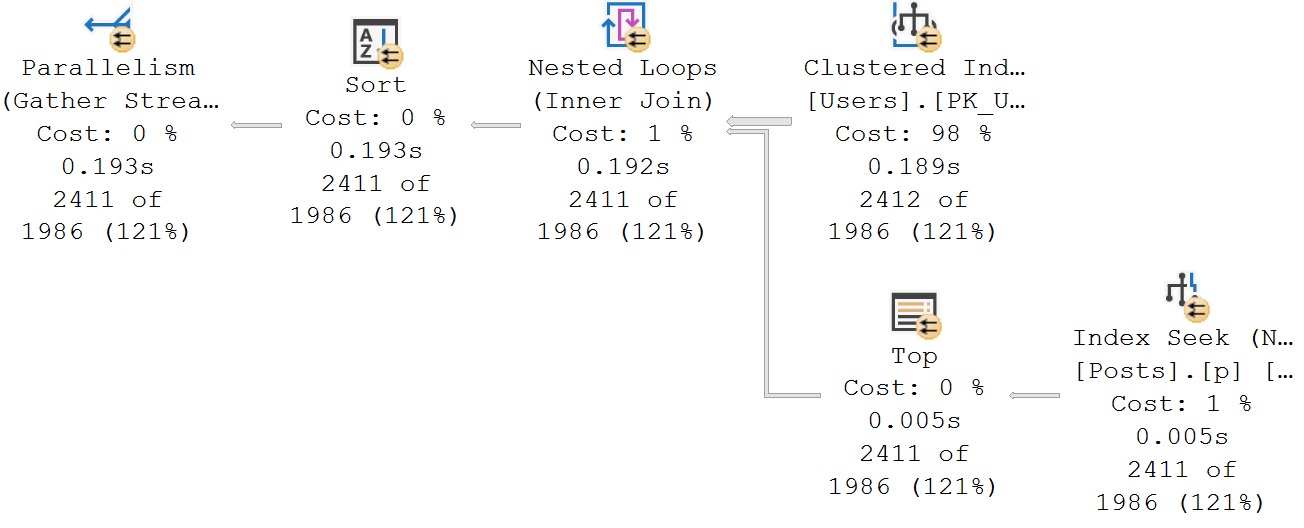
В этом случае, при наличии хорошего используемого индекса и небольшого внешнего результата из таблицы Users, запрос с cross apply оказывается лучшим вариантом.
Это также обусловлено тем, что столбец id в таблице Users является первичным ключом таблицы. Для такого типа соединения один-ко-многим, это работает замечательно. Если будет иметь место сценарий "многие-ко-многим", то, возможно, победит ROW_NUMBER.
Принцип работы этого типа соединения вложенными циклами (Apply Nested Loops) состоит в том, чтобы брать каждую строку из внешнего входа (таблица Users) и искать ее в таблице Posts.
Без такого хорошего индекса тут возможна беда с Eager Index Spool в плане. Нам определенно это не понравится.
Как вы знаете, существует много разных типов публикаций. Мы можем захотеть узнать тех, кто имеет максимальный ранг в вопросах, ответах и т.д. Оставим рассмотрение этого для следующей статьи и то, как настроить производительность такого запроса.
Я собираюсь сравнить пару различных сценариев получения топового значения.
Конечно, имеются и другие способы написания такого рода запросов, но я хочу показать вам наиболее распространенные анти-шаблоны, которые я наблюдаю, и наиболее общее решение, которое заставит их работать лучше.
Правильная индексация
Здесь мы собираемся использовать такой индекс:
CREATE INDEX p ON dbo.Posts(OwnerUserId, Score DESC) INCLUDE(PostTypeId)
WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);Который собирается оказать этому запросу надлежащую поддержку. Конечно, мы могли бы также добавить индекс в таблицу Users, но одно сканирование тривиально быстро, и, вероятно, тут ничего не выиграешь.
SELECT
u.DisplayName,
u.Reputation,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
JOIN
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
) AS p
ON p.OwnerUserId = u.Id
AND p.n = 1
WHERE u.Reputation > 50000
ORDER BY
u.Reputation DESC,
p.Score DESC;Основная идея состоит в нахождении всех пользователей с репутацией свыше 50000, а также их публикации с наивысшим баллом.
Я знаю, вы смотрите на это и думаете: "Господи, Эрик, почему ты выбираешь здесь *? Не знаешь, как это глупо?"
Ну, SQL Server достаточно умен, чтобы игнорировать это, и он будет иметь дело только со столбцами во внешнем select.
План запроса
Если вы создали индекс и выполнили запрос, план запроса будет выглядеть примерно так:
Главные затраты времени в этом плане - это ~11 секунд между сканированием таблицы Posts и оператором Filter.
Фильтр нужен здесь, чтобы удалить строки, для которых результат функции ROW_NUMBER больше 1.
Могу предположить, что вы скажете также и меньше 1, но ROW_NUMBER, естественно, не может произвести строки с 0 или отрицательными числами. Вам следует делать это при помощи вычитания.
Лучший шаблон запроса?
Поскольку только ~2400 строк выходят из таблицы Users, и мы имеем хороший индекс на таблице Posts, то хотим получить тут преимущество.
Вместо сканирования всей таблицы Posts, генерации ROW_NUMBER, применения фильтра с последующим соединением, мы можем использовать CROSS APPLY, чтобы перенести все туда, где мы касаемся таблицы Posts.
SELECT
u.DisplayName,
u.Reputation,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
ORDER BY p.Score DESC
) AS p
WHERE u.Reputation > 50000
ORDER BY
u.Reputation DESC,
p.Score DESC;Это логически эквивалентно, но отличается в производительности.
Лучший план запроса?
Вот план для запроса с cross apply:
Почему это лучше?
В этом случае, при наличии хорошего используемого индекса и небольшого внешнего результата из таблицы Users, запрос с cross apply оказывается лучшим вариантом.
Это также обусловлено тем, что столбец id в таблице Users является первичным ключом таблицы. Для такого типа соединения один-ко-многим, это работает замечательно. Если будет иметь место сценарий "многие-ко-многим", то, возможно, победит ROW_NUMBER.
Принцип работы этого типа соединения вложенными циклами (Apply Nested Loops) состоит в том, чтобы брать каждую строку из внешнего входа (таблица Users) и искать ее в таблице Posts.
Без такого хорошего индекса тут возможна беда с Eager Index Spool в плане. Нам определенно это не понравится.
Как вы знаете, существует много разных типов публикаций. Мы можем захотеть узнать тех, кто имеет максимальный ранг в вопросах, ответах и т.д. Оставим рассмотрение этого для следующей статьи и то, как настроить производительность такого запроса.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой