
Под капотом SQL Server. Основы кэширования данных
Пересказ статьи Eduardo Pivaral. SQL Engine basics: Caching data
Ядро SQL Server выполняет замечательную работу по оптимизации производительности запросов, используя при этом различные методы, одним из которых является кэширование данных.
Кэширование данных заключается в перемещении затребованных 8-килобайтных страниц из устройств хранения в память, в результате чего ядро базы данных может получить повторный доступ к требуемым данным значительно быстрее.
В общих чертах способ, который использует ядро SQL, можно представить следующим образом:

1 - данные запрашиваются скомпилированным запросом;
2 - движок проверяет, находятся ли нужные данные уже в памяти;
3 - если данных нет в памяти, они берутся из устройств хранения;
4 - данные помещаются в память.
По запросу ядро проверяет, находятся ли требуемые данные уже в памяти (или буферном пуле). Если данные там, они возвращаются. Если данных нет, то они запрашиваются с диска и помещаются в память, если буферный пул не заполнен.
Насколько долго данные сохраняются в буферном пуле зависит от различных аспектов: памяти, выделенной SQL Server, размера вашей базы данных, рабочей нагрузки, типа выполняемых запросов, OLTP в памяти и т.д.
Когда в буфере недостаточно места для выделения требуемой памяти, то происходит сброс данных, который состоит в том, что избыточные данные сохраняются в базе данных tempdb. Это обычно вызвано неточным выделением памяти. К счастью, в SQL Server 2019 реализована обратная связь по выделению памяти (Memory Grant feedback), которая помогает облегчить проблему.
Начиная с версии SQL Server 2014, вы также можете сконфигурировать расширения буферного пула, т.е. расширить память за счет более быстрых устройств хранения (обычно SDD или флеш-памяти). Об этом вы можете прочитать в документации Майкрософт.
Теперь, когда вы имеете представление о том, как работает кэширование данных, давайте посмотрим на него в действии.
Для примеров мы будем использовать тестовую базу данных WideWorldImporters. Сначала мы выполним несколько запросов. Для нас не принципиально, что они делают; это может быть любой оператор SELECT:
Затем мы используем динамическое представление sys.dm_os_buffer_descriptors, чтобы проверить, какие данные находятся в памяти, сделав запрос более читабельным, например:
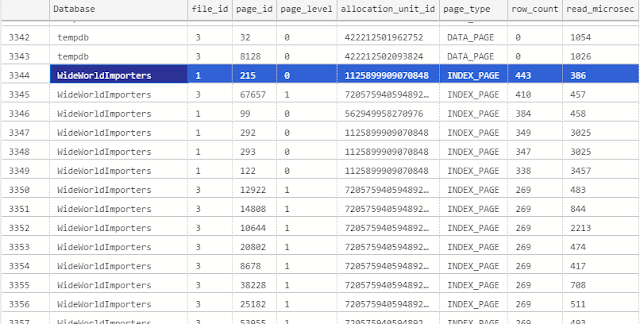
В зависимости от рабочей нагрузки мы получим что-то типа
Если вы предпочитаете что-то более компактное, можете выполнить запрос, группируя его по базе данных:
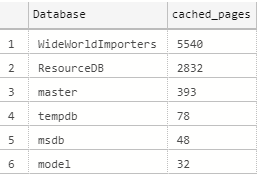
Вот результаты, сгруппированные по базе данных:
Чтобы очистить кэш от данных, выполните команду
Замечание.Избегайте выполнения этой команды на рабочем сервере, поскольку при этом все данные будут сброшены из памяти снова на диск, вызывая дополнительную нагрузку ввода/вывода.
Если у вас включено расширение буферного пула, и вы хотите проверить эту опцию; или вы хотите определить, имеет ли её экземпляр, используйте динамическое представление sys.dm_os_buffer_pool_extension_configuration:
Результат будет примерно таким (у меня не включено расширение буферного пула):

В общих чертах способ, который использует ядро SQL, можно представить следующим образом:
1 - данные запрашиваются скомпилированным запросом;
2 - движок проверяет, находятся ли нужные данные уже в памяти;
3 - если данных нет в памяти, они берутся из устройств хранения;
4 - данные помещаются в память.
По запросу ядро проверяет, находятся ли требуемые данные уже в памяти (или буферном пуле). Если данные там, они возвращаются. Если данных нет, то они запрашиваются с диска и помещаются в память, если буферный пул не заполнен.
Насколько долго данные сохраняются в буферном пуле зависит от различных аспектов: памяти, выделенной SQL Server, размера вашей базы данных, рабочей нагрузки, типа выполняемых запросов, OLTP в памяти и т.д.
Когда в буфере недостаточно места для выделения требуемой памяти, то происходит сброс данных, который состоит в том, что избыточные данные сохраняются в базе данных tempdb. Это обычно вызвано неточным выделением памяти. К счастью, в SQL Server 2019 реализована обратная связь по выделению памяти (Memory Grant feedback), которая помогает облегчить проблему.
Начиная с версии SQL Server 2014, вы также можете сконфигурировать расширения буферного пула, т.е. расширить память за счет более быстрых устройств хранения (обычно SDD или флеш-памяти). Об этом вы можете прочитать в документации Майкрософт.
Команды T-SQL
Теперь, когда вы имеете представление о том, как работает кэширование данных, давайте посмотрим на него в действии.
Для примеров мы будем использовать тестовую базу данных WideWorldImporters. Сначала мы выполним несколько запросов. Для нас не принципиально, что они делают; это может быть любой оператор SELECT:
DECLARE @RawValue decimal(10,2) = 25000
SELECT SUM(UnitPrice * Quantity) as RawValue
FROM Sales.InvoiceLines
GROUP BY InvoiceID
HAVING SUM(UnitPrice * Quantity) > @RawValue;
SET @RawValue = RAND()*1500
SELECT InvoiceID, InvoiceLineID, UnitPrice,Quantity
FROM Sales.InvoiceLines
WHERE TaxAmount > @RawValue
OPTION(FAST 100); Затем мы используем динамическое представление sys.dm_os_buffer_descriptors, чтобы проверить, какие данные находятся в памяти, сделав запрос более читабельным, например:
--ДЕТАЛИ ПО БАЗЕ ДАННЫХ:
SELECT
IIF(database_id = 32767,'ResourceDB',DB_NAME(database_id)) AS [Database],
file_id, --Этот файл находится на уровне базы данных,
-- он зависит от базы данных, на которой выполняется запрос
page_id,
page_level,
allocation_unit_id, -- можно соединить с sys.allocation_units (DMO уровня базы данных)
page_type,
row_count,
read_microsec
FROM sys.dm_os_buffer_descriptors BD
ORDER BY [Database], row_count DESC;В зависимости от рабочей нагрузки мы получим что-то типа
Если вы предпочитаете что-то более компактное, можете выполнить запрос, группируя его по базе данных:
-- ЧТОБЫ ПОЛУЧИТЬ ИТОГИ ПО БАЗЕ ДАННЫХ:
SELECT
IIF(database_id = 32767,'ResourceDB',DB_NAME(database_id)) AS [Database],
COUNT(row_count) AS cached_pages
FROM sys.dm_os_buffer_descriptors
GROUP BY database_id
ORDER BY cached_pages DESC;
Вот результаты, сгруппированные по базе данных:
Чтобы очистить кэш от данных, выполните команду
DBCC DROPCLEANBUFFERS;Замечание.Избегайте выполнения этой команды на рабочем сервере, поскольку при этом все данные будут сброшены из памяти снова на диск, вызывая дополнительную нагрузку ввода/вывода.
Если у вас включено расширение буферного пула, и вы хотите проверить эту опцию; или вы хотите определить, имеет ли её экземпляр, используйте динамическое представление sys.dm_os_buffer_pool_extension_configuration:
-- Проверяем, включено ли расширение буферного пула:
SELECT * FROM sys.dm_os_buffer_pool_extension_configuration; Результат будет примерно таким (у меня не включено расширение буферного пула):
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой