
Почему запросы к связанным серверам настолько плохи?
Пересказ статьи Brent Ozar. Why Are Linked Server Queries So Bad?
Помните, когда вы в школе были в кого-то были влюблены? Вы могли бы написать записку с просьбой сделать вас валентинкой и попросить общего друга передать эту записку.
Взрослый эквивалент этого - запросы к связанному серверу.
Когда вашему запросу требуется получить данные, которые фактически хранятся на совершенно другом SQL Server, возникает соблазн использовать запросы к связанному серверу. Их действительно легко написать: после установки связанного сервера просто укажите имя сервера и базы данных перед вашим запросом, все остальное, связанное с подключением к серверу, содержащим необходимые вам данные, SQL Server возьмет на себя.
Я продемонстрирую пример, используя доступную базу данных Stack Overflow. В этом примере таблица Users хранится локально, но мне требуется извлечь данные из много большей таблицы Posts, которая находится на другом сервере.
Я ищу самые свежие публикации, написанные пользователями с низким числом голосов. Производительность катастрофическая, занимающая минуты времени исполнения - и даже не возвращающая строк. Какие две проблемы являются причиной?
SQL Server верит, что этому запросу будет соответствовать МНОЖЕСТВО пользователей, поэтому он решает просто начать передавать строки таблицы Posts по сети. Почитайте план запроса справа налево и сверху вниз - первое, что решил сделать SQL Server, находится вверху справа:
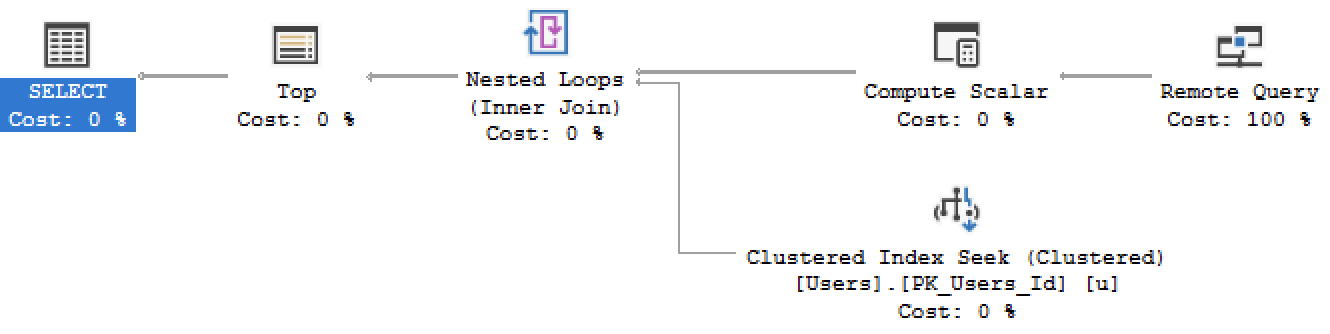
Первое, что решил сделать SQL Server, был удаленный запрос - сканирование таблицы Posts по сети, начиная с самых свежих публикаций. Удаленный SQL Server посылает строки, и для каждой строки локальный SQL Server проверяет, имеет ли соответствующий пользователь низкое число голосов.
Этот план работал бы замечательно, если бы предположение SQL Server о большом числе подходящих пользователей было верным. В некоторых случаях, когда предположения SQL Server согласуются с действительностью, запросы выполняются просто великолепно. (Это на самом деле хорошая часть настройки этого запроса, и, как я говорил в своем классе основ настройки запросов, большое расхождение в оценке и действительном числе строк является обычно тем местом, где требуется настройка.)
К сожалению, это предположение не верно.
В действительности нет пользователей, отвечающих критерию.
Поэтому локальный SQL Server продолжает перетаскивать строки по сети из удаленного сервера, проверяя по одной её владельца, и, в конце концов, исчерпает все содержимое таблицы Posts. В конце концов, план заканчивается, а вот действительный план:
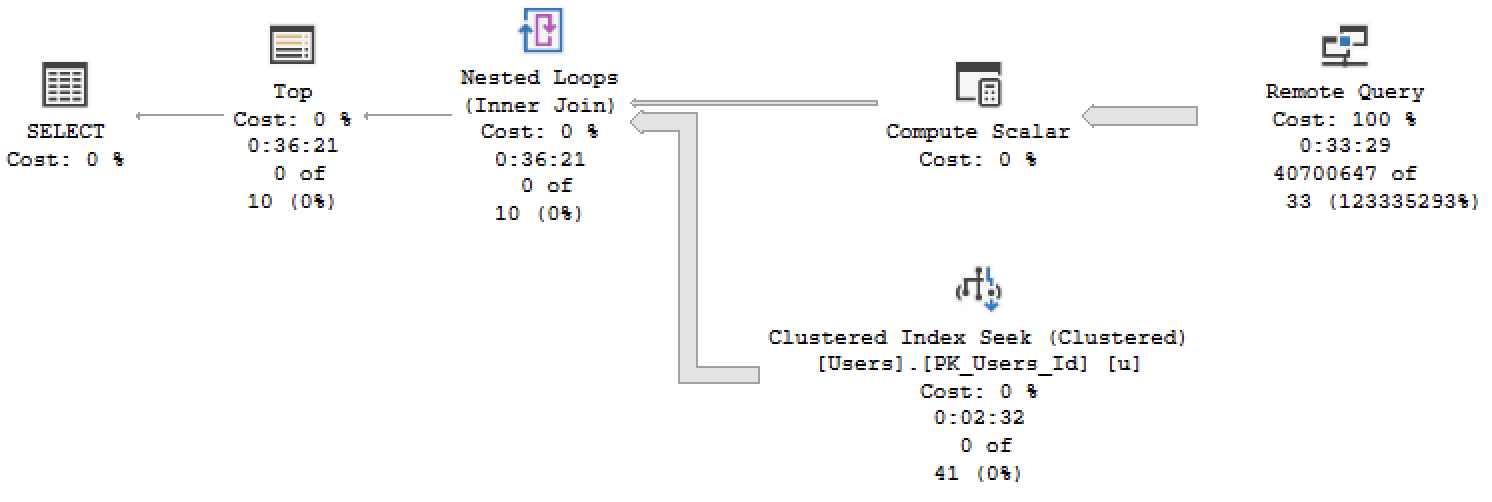
Запрос к связанному серверу копирует всю таблицу Posts по сети построчно.
Да, это 33 минуты и 29 секунд.
Если вы выполните тот же самый запрос к связанному серверу дюжину раз - даже если строки не меняются, даже если база данных только на чтение, даже если все двенадцать запросов выполняются одновременно, SQL Server сделает дюжину различных подключений к связанному серверу и извлечет данные с нуля для каждого в свое время.
Это еще один отличный пример шаблона разработки, который замечательно работает при разработке, особенно на базах данных небольших размеров - но затем резко падает при масштабировании, при больших базах данных и большом числе конкурирующих запросов.
Хуже того, наказываются оба сервера, участвующие в запросе к связанному серверу. Трудности возникают на локальном сервере, и трудности возникают на удаленном сервере, который содержит единственный источник истины для таблицы.
Существует много больше причин, по которым запросы к связанным серверам выполняются плохо - но только эти две являются шедеврами.
Они хороши для разовых запросов утилит, вещей, которые вы должны сделать пару раз. Например, кто-то реально повредил таблицу, и вам нужно восстановить её содержимое. Поскольку до сих пор SQL Server не может восстановить отдельную таблицу, общий подход таков:
Тем самым вы не будете рисковать случайно восстановить бэкап по всей рабочей базе данных, и вы можете сэкономить время, выбрав конкретные нужные вам строки.
В противном случае, если вам нужны данные с другого SQL Server, у меня есть четкий совет: подключитесь к серверу, который содержит нужные вам данные. Если вам нужны результаты быстро, это самая надежная игра в городе.
И для протокола, о той записке, которую ваш друг передал мне, ответ - нет, я не хочу быть вашей валентинкой. Но если бы вы спросили меня напрямую, ответ мог бы быть другим. В этом состоит данный урок.
Я продемонстрирую пример, используя доступную базу данных Stack Overflow. В этом примере таблица Users хранится локально, но мне требуется извлечь данные из много большей таблицы Posts, которая находится на другом сервере.
SELECT TOP 10 u.DisplayName, p.*
FROM dbo.Users u
INNER JOIN [RemoteServer].StackOverflow.dbo.Posts p ON u.Id = p.OwnerUserId
WHERE u.UpVotes + u.DownVotes < 0
ORDER BY p.CreationDate DESC;Я ищу самые свежие публикации, написанные пользователями с низким числом голосов. Производительность катастрофическая, занимающая минуты времени исполнения - и даже не возвращающая строк. Какие две проблемы являются причиной?
Проблема #1: запросы к связанному серверу могут копировать всю таблицу, перемещая её по сети.
SQL Server верит, что этому запросу будет соответствовать МНОЖЕСТВО пользователей, поэтому он решает просто начать передавать строки таблицы Posts по сети. Почитайте план запроса справа налево и сверху вниз - первое, что решил сделать SQL Server, находится вверху справа:
Первое, что решил сделать SQL Server, был удаленный запрос - сканирование таблицы Posts по сети, начиная с самых свежих публикаций. Удаленный SQL Server посылает строки, и для каждой строки локальный SQL Server проверяет, имеет ли соответствующий пользователь низкое число голосов.
Этот план работал бы замечательно, если бы предположение SQL Server о большом числе подходящих пользователей было верным. В некоторых случаях, когда предположения SQL Server согласуются с действительностью, запросы выполняются просто великолепно. (Это на самом деле хорошая часть настройки этого запроса, и, как я говорил в своем классе основ настройки запросов, большое расхождение в оценке и действительном числе строк является обычно тем местом, где требуется настройка.)
К сожалению, это предположение не верно.
В действительности нет пользователей, отвечающих критерию.
Поэтому локальный SQL Server продолжает перетаскивать строки по сети из удаленного сервера, проверяя по одной её владельца, и, в конце концов, исчерпает все содержимое таблицы Posts. В конце концов, план заканчивается, а вот действительный план:
Запрос к связанному серверу копирует всю таблицу Posts по сети построчно.
Да, это 33 минуты и 29 секунд.
Проблема #2: связанные серверы не кэшируют данные
Если вы выполните тот же самый запрос к связанному серверу дюжину раз - даже если строки не меняются, даже если база данных только на чтение, даже если все двенадцать запросов выполняются одновременно, SQL Server сделает дюжину различных подключений к связанному серверу и извлечет данные с нуля для каждого в свое время.
Это еще один отличный пример шаблона разработки, который замечательно работает при разработке, особенно на базах данных небольших размеров - но затем резко падает при масштабировании, при больших базах данных и большом числе конкурирующих запросов.
Хуже того, наказываются оба сервера, участвующие в запросе к связанному серверу. Трудности возникают на локальном сервере, и трудности возникают на удаленном сервере, который содержит единственный источник истины для таблицы.
Существует много больше причин, по которым запросы к связанным серверам выполняются плохо - но только эти две являются шедеврами.
Итак, когда все в порядке со связанными серверами?
Они хороши для разовых запросов утилит, вещей, которые вы должны сделать пару раз. Например, кто-то реально повредил таблицу, и вам нужно восстановить её содержимое. Поскольку до сих пор SQL Server не может восстановить отдельную таблицу, общий подход таков:
- Восстановить базу данных из бэкапа на другом сервере.
- Вытащить только те строки, которые вам нужны (или все), используя соединение со связанным сервером.
Тем самым вы не будете рисковать случайно восстановить бэкап по всей рабочей базе данных, и вы можете сэкономить время, выбрав конкретные нужные вам строки.
В противном случае, если вам нужны данные с другого SQL Server, у меня есть четкий совет: подключитесь к серверу, который содержит нужные вам данные. Если вам нужны результаты быстро, это самая надежная игра в городе.
И для протокола, о той записке, которую ваш друг передал мне, ответ - нет, я не хочу быть вашей валентинкой. Но если бы вы спросили меня напрямую, ответ мог бы быть другим. В этом состоит данный урок.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой