
Почему порядок не гарантируется без ORDER BY
Пересказ статьи Brent Ozar. Why Ordering Isn’t Guaranteed Without an ORDER BY
Если ваш запрос не имеет предложения ORDER BY, вы не можете надежно предсказать неизменность порядка результатов с течением времени.
Конечно, сначала это будет выглядеть предсказуемо, но в будущем, когда что-то будет меняться - индексы, таблица, конфигурация сервера, размер ваших данных - вы можете столкнуться с неприятными сюрпризами.
Давайте начнем с чего-нибудь простого: мы выполним SELECT из таблицы пользователей Stack Overflow. Кластеризованным ключом на этой таблице является id, идентификационный номер, который начинается с единицы и далее. Когда мы выполняем SELECT, данные возвращаются в порядке кластеризованного индекса:
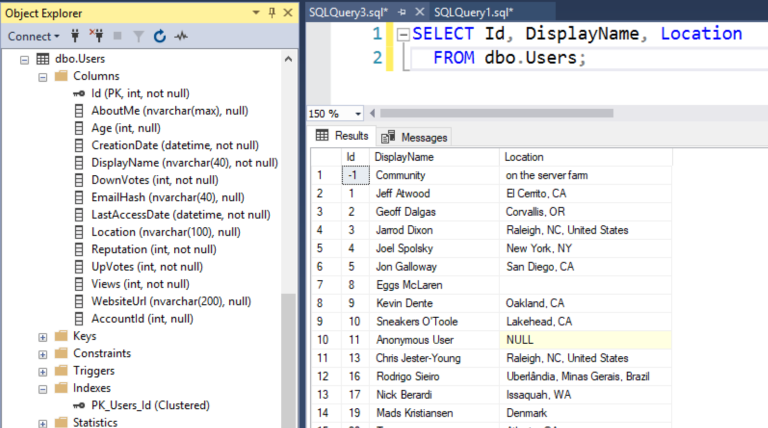
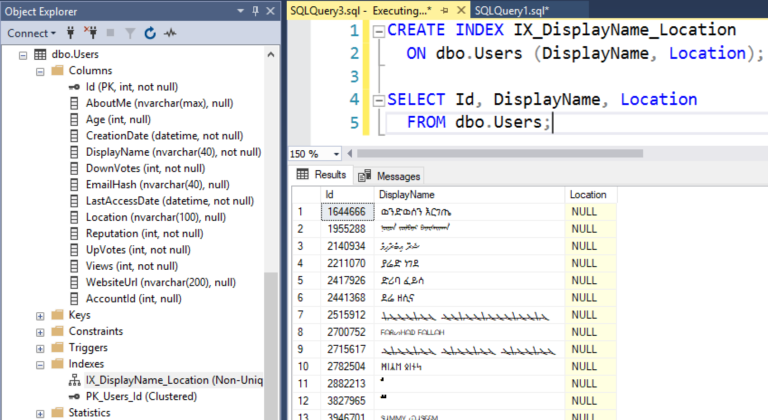
Но если кто-нибудь создаст индекс на DisplayName и Location, то внезапно SQL Server начнет использовать этот индекс, а не кластеризованный:
Вот план выполнения в качестве доказательства:
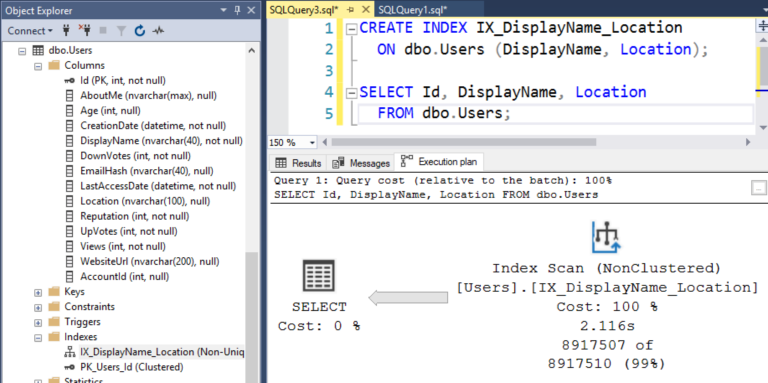
Почему SQL Server выбрал этот индекс, несмотря на то, что не требовалось выполнять сортировку по DisplayName и Location? Потому что этот индекс является более узкой/наименьшей копией данных, которые требуется получить серверу. Давайте оценим размеры индексов с помощью sp_BlitzIndex:
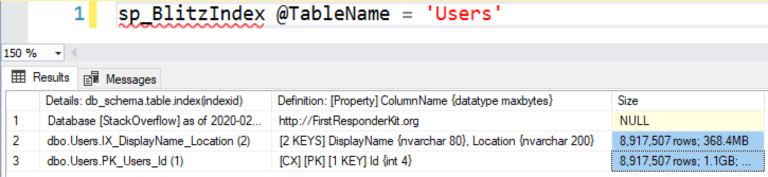
Кластеризованный индекс таблицы (CX/PK) содержит 8,9М строк и имеет размер 1,1Гб.
Некластеризованный индекс на DisplayName/Location также содержит 8.9M строк, но его размер только 368Мб. Если вы собираетесь выполнить полное сканирование, чтобы получить результаты запроса, почему бы не сканировать наименьший объект, что будет выполнено быстрей? Именно так поступает SQL Server.
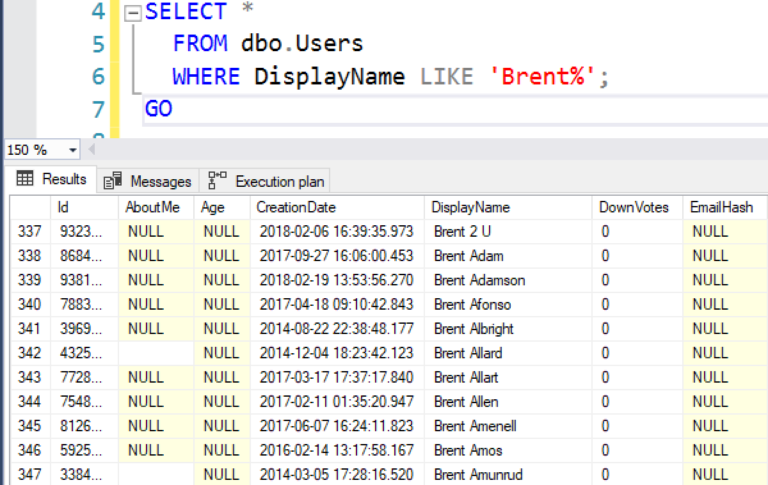
ОК, теперь, когда мы имеем индекс на DisplayName/Location, попробуем выполнить запрос, который ищет конкретное значение DisplayName. Результаты вернутся упорядоченными по DisplayName:
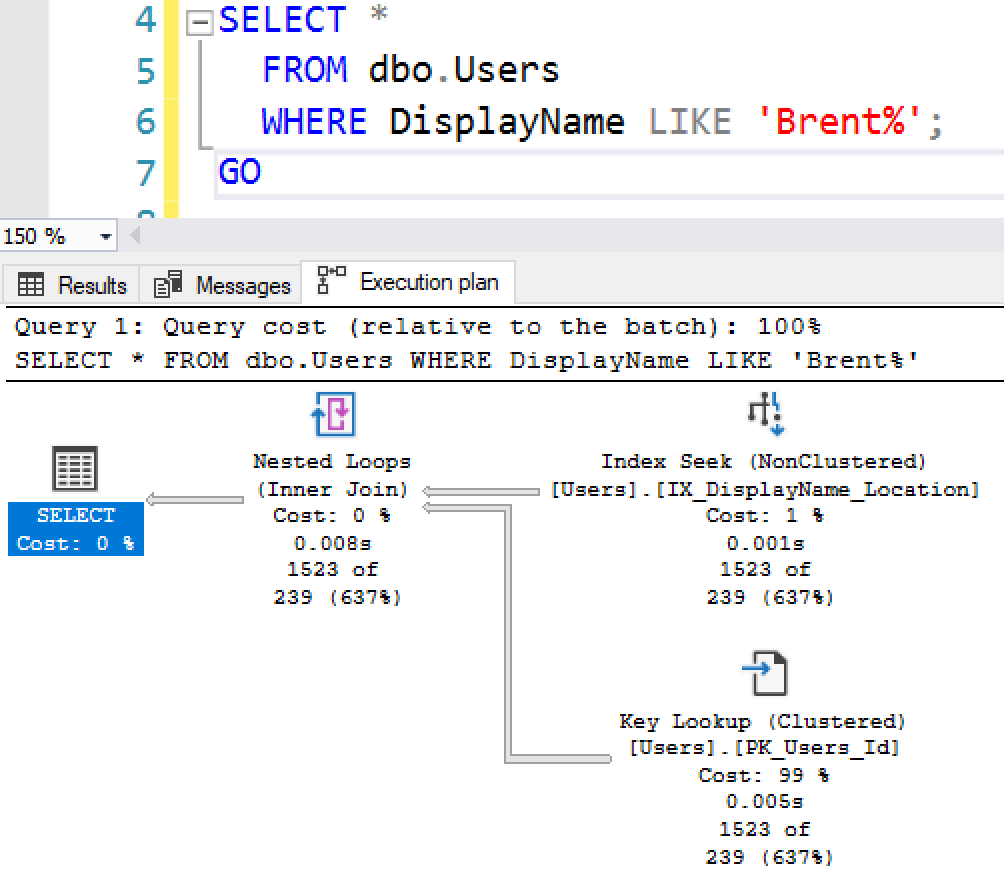
А план выполнения использует этот индекс:
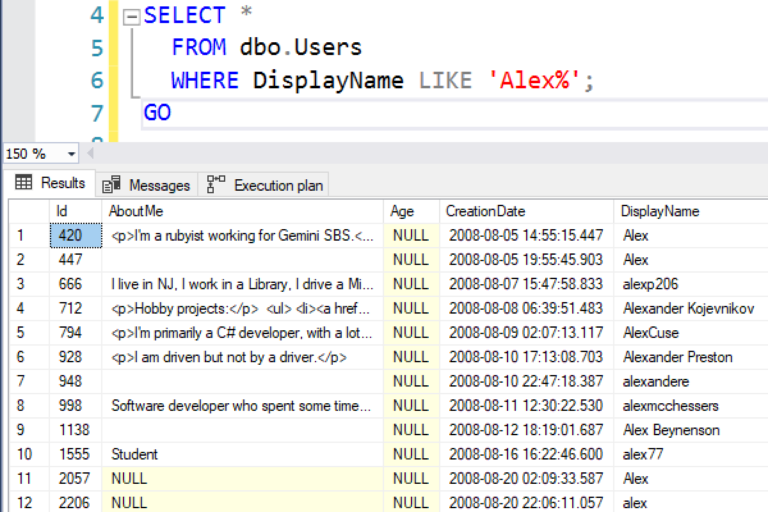
Но если теперь вы проверите другое имя пользователя, то результаты вообще не будут отсортированы по имени:
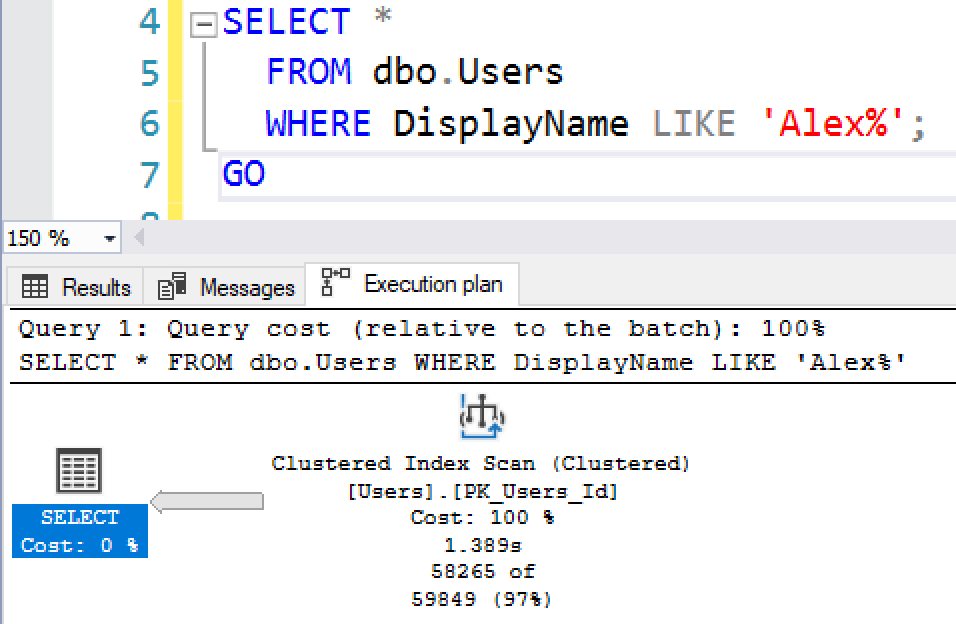
Поскольку SQL Server решил, что имеется больше Alex`ов, поэтому имеет смысл выполнить сканирование кластеризованного индекса, а не поиск + поиск ключа:
Даже в этих на самом деле простых примерах вам не гарантируется, что SQL Server будет всегда использовать ту копию данных, которую вы ожидаете. За последние несколько недель я столкнулся с много более сложными случаями:
Если потребуются данные для завтрашнего заказа, когда вас не будет рядом, просто добавьте ORDER BY. Ваши внуки скажут вам спасибо, когда будут разбираться с вашим запросом.
Но если кто-нибудь создаст индекс на DisplayName и Location, то внезапно SQL Server начнет использовать этот индекс, а не кластеризованный:
Вот план выполнения в качестве доказательства:
Почему SQL Server выбрал этот индекс, несмотря на то, что не требовалось выполнять сортировку по DisplayName и Location? Потому что этот индекс является более узкой/наименьшей копией данных, которые требуется получить серверу. Давайте оценим размеры индексов с помощью sp_BlitzIndex:
Кластеризованный индекс таблицы (CX/PK) содержит 8,9М строк и имеет размер 1,1Гб.
Некластеризованный индекс на DisplayName/Location также содержит 8.9M строк, но его размер только 368Мб. Если вы собираетесь выполнить полное сканирование, чтобы получить результаты запроса, почему бы не сканировать наименьший объект, что будет выполнено быстрей? Именно так поступает SQL Server.
Да, но мой запрос имеет предложение WHERE.
ОК, теперь, когда мы имеем индекс на DisplayName/Location, попробуем выполнить запрос, который ищет конкретное значение DisplayName. Результаты вернутся упорядоченными по DisplayName:
А план выполнения использует этот индекс:
Но если теперь вы проверите другое имя пользователя, то результаты вообще не будут отсортированы по имени:
Поскольку SQL Server решил, что имеется больше Alex`ов, поэтому имеет смысл выполнить сканирование кластеризованного индекса, а не поиск + поиск ключа:
Это простые примеры, и я могу продолжать.
Даже в этих на самом деле простых примерах вам не гарантируется, что SQL Server будет всегда использовать ту копию данных, которую вы ожидаете. За последние несколько недель я столкнулся с много более сложными случаями:
- Кто-то удаляет индекс, который использовался запросом.
- Кто-то включил Forced Parameterization, которая изменила оценку числа строк для плана запроса SQL Server, что привело к смене выбора индекса.
- Кто-то изменил уровень совместимости базы данных, вводя в действие более новый оценщик кардинального числа, что привело к построению другого плана.
Если потребуются данные для завтрашнего заказа, когда вас не будет рядом, просто добавьте ORDER BY. Ваши внуки скажут вам спасибо, когда будут разбираться с вашим запросом.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой