
Почему Not Exist более осмыслен, чем Left Join
Пересказ статьи Erik Darling. Why Not Exists Makes More Sense Than Left Joins
Задача
Требуется найти строки в одной таблице, которым нет соответствия в другой таблице. Это может быть процесс сверки данных или же часть работы ETL, или еще что-то.
Не важно. Но внимание!
Способ, которым большинство людей напишет этот запрос, сначала будет выглядеть примерно так:
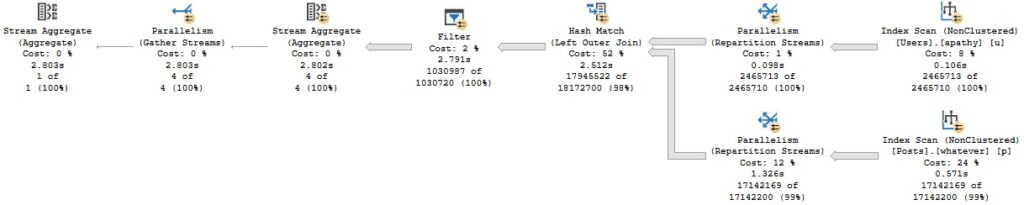
План запроса содержит одну из моих наименее любимых вещей: фильтр.
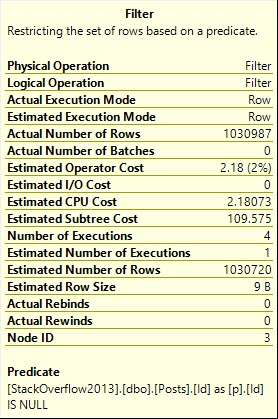
Что делает фильтр?
Поиск NULL-значений после соединения. Беда.
Выражаясь более эскуэльно, мы могли бы использовать NOT EXISTS.
Смотрите, что я имею в виду. Столбец id в таблице Posts является PK/CX. Это означает, что он не может быть NULL, пока не появятся в левом соединении строка, не имеющая соответствия.
Если этот столбец равен NULL, то все остальные строки будут иметь значение NULL. Вам не требуется выбирать какие-либо данные из таблицы Posts.
Теперь план запроса выглядит так:
Это работает лучше (в большинстве случаев) и получает некоторую дополнительную оптимизацию: Bitmap и предварительная агрегация по столбцу OwnerUserId в таблице Posts.
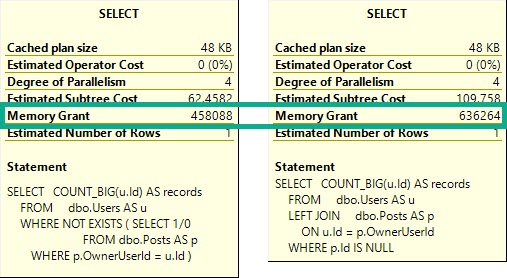
Запрос с Not Exists будет запрашивать около 200Мб памяти для выполнения.
Почему так? Почему возникает такая разница между двумя логически эквивалентными запросами?
Left Join заставляет полностью соединять обе таблицы, создавая как совпадающие, так и несовпадающие строки.
После соединения мы исключаем несовпадающие строки в Filter. Вот почему обычно я с подозрением отношусь к операциям Filter. Это часто означает, что мы имеем некоторое выражение или комбинацию выражений в нашей логике, которые мешают оптимизатору исключить строки раньше. Этого следует ожидать, когда мы выполняем что-то типа генерации и фильтрации по номеру строки - номер строки не существует до тех пор, пока не будет выполнен запрос, и должен быть отфильтрован уже после получения соответствующих данных.
Варианты
Способ, которым большинство людей напишет этот запрос, сначала будет выглядеть примерно так:
SELECT COUNT_BIG(u.Id) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
WHERE p.Id IS NULL;План запроса содержит одну из моих наименее любимых вещей: фильтр.
2,8 секунды!
Что делает фильтр?
IS NULLы
Поиск NULL-значений после соединения. Беда.
Лучший выбор
Выражаясь более эскуэльно, мы могли бы использовать NOT EXISTS.
SELECT COUNT_BIG(u.Id) AS records
FROM dbo.Users AS u
WHERE NOT EXISTS ( SELECT 1/0
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id );Смотрите, что я имею в виду. Столбец id в таблице Posts является PK/CX. Это означает, что он не может быть NULL, пока не появятся в левом соединении строка, не имеющая соответствия.
Если этот столбец равен NULL, то все остальные строки будут иметь значение NULL. Вам не требуется выбирать какие-либо данные из таблицы Posts.
Теперь план запроса выглядит так:

1,6 секунд
Это работает лучше (в большинстве случаев) и получает некоторую дополнительную оптимизацию: Bitmap и предварительная агрегация по столбцу OwnerUserId в таблице Posts.
Не только скорость?
Запрос с Not Exists будет запрашивать около 200Мб памяти для выполнения.
Каждый пенни
Почему так? Почему возникает такая разница между двумя логически эквивалентными запросами?
Left Join заставляет полностью соединять обе таблицы, создавая как совпадающие, так и несовпадающие строки.
После соединения мы исключаем несовпадающие строки в Filter. Вот почему обычно я с подозрением отношусь к операциям Filter. Это часто означает, что мы имеем некоторое выражение или комбинацию выражений в нашей логике, которые мешают оптимизатору исключить строки раньше. Этого следует ожидать, когда мы выполняем что-то типа генерации и фильтрации по номеру строки - номер строки не существует до тех пор, пока не будет выполнен запрос, и должен быть отфильтрован уже после получения соответствующих данных.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой