
Перераспределение данных по файлам
Пересказ статьи Steve Jones. Redistributing Data Across Files
Много людей, которые поневоле занимаются администрированием баз данных, могут не знать, как таблицы распределяются по файлам в файловых группах. Часто оказывается, что менее опытные люди путаются с файлами и файловыми группами, а также с тем, как SQL Server распределяет данные по файлам, и почему данные не перемещаются при добавлении файлов.
В этой статье показывается, как SQL Server обрабатывает данные, когда новые файлы добавляются в файловую группу. Мы также покажем, как распределить данные более равномерно, чтобы сбалансировать нагрузку чтения/записи.
Рассмотрим небольшой пример, который проиллюстрирует нашу цель. Когда у вас будет больше данных, проблема усугубится, но эффект остается тем же. Мы предполагаем, что у вас есть база данных с некоторым количеством данных. Вы можете видеть, что у меня имеется несколько таблиц с небольшим числом строк.
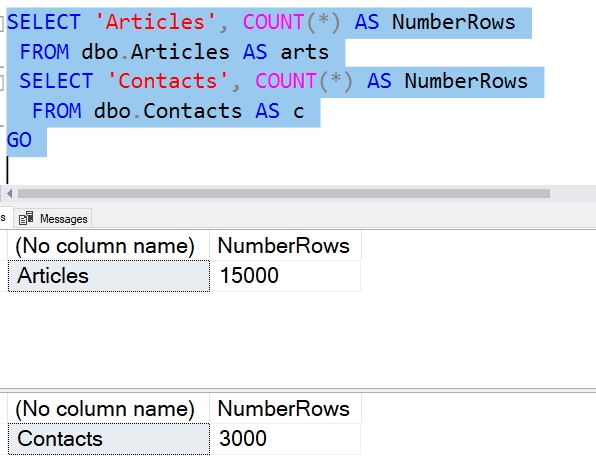
Однако моей базе данных не хватает места. По моим оценкам, если я добавляю несколько МБ данных в день, то скоро у меня закончится место.
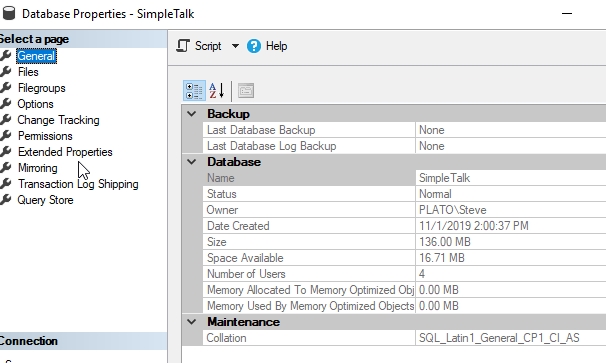
По умолчанию у меня есть одна файловая группа с единственным файлом. Как можно видеть, я имею файл на 128Мб и журнал размером 8Мб:
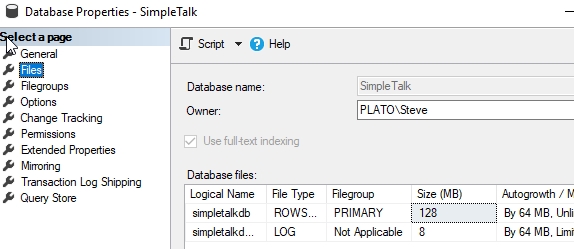
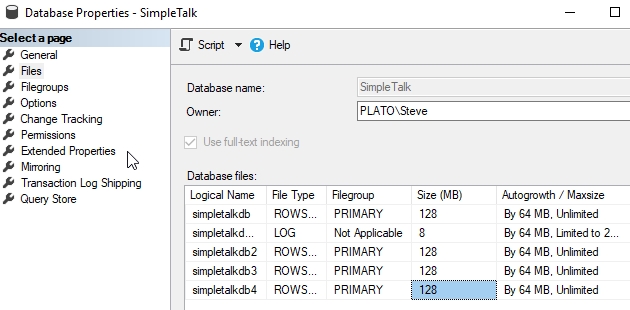
Обычно в таких ситуациях следует проявить активность и добавить несколько файлов данных для распределения нагрузки. Тут вы можете увидеть, что мы добавили 3 дополнительных файла данных в нашу базу. Когда я это делаю, то добавляю файлы того же размера, что и оригинальный файл. Это лучший способ гарантировать сбалансированность файловой группы.
Замечание. Я показываю это в графическом интерфейсе, но вы должны взять скрипт и выполнить его в команде ALTER DATABASE, а не визуальными действиями в Management Studio.
Теперь я могу сделать запрос к моим файлам. Для этого я выполню следующий код:
Вот результаты, которые я получаю. Мой первый файл (simpletalkdb) почти заполнен. Он имеет 15Мб, которые могут быть использованы, а остальные файлы используются незначительно (0.06Мб). В крайнем справа столбце показан процент свободного пространства, 13% для первого файла и 99% - для остальных.

Здесь пользователи часто испытывают недоумение. Почему мои данные не переместились для балансировки файлов? Если я добавлю новые данные, вот что я увижу. Я добавлю около 30 мегабайт данных и повторю запрос. Теперь результаты выглядят так:

В каждый файл были добавлены некоторые данные, но распределение не равномерное. Я имею почти 12% свободного пространства в одном файле при 90% свободного пространства в других. Почему?
SQL Server использует алгоритм пропорционального заполнения, который записывает существенно больше данных в пустые файлы, чем в заполненные. Он пытается (в конечном итоге) сбалансировать данные по всем файлам. Вы можете больше прочитать об этом на SQLServerCentral и SQLskills. Это алгоритм циклической записи, который решает, в какой файл писать, и, чем больше каждый файл имеет свободного пространства, тем больше данных в него записывается.
На практике лучше иметь файлы одинаковых размеров и приблизительно одинаковое количество данных в каждом из них. Это сбалансирует запись и улучшит производительность.
Если в этом состоит наша цель, то как получить равномерное распределение данных по файлам? Если мы продолжим добавлять данные, то в конечном итоге добьемся этого, но мы будем иметь все больше и больше записей, приходящихся на пустые файлы, пока не достигнем желаемого.
Если у вас есть кластеризованный индекс, самый простой способ попытаться сделать это с помощью перестройки индекса. Я могу использовать следующий код на самых больших таблицах:
По завершению перестройки, я могу снова выполнить запрос, показывающий распределение данных. Теперь оно выглядит так:

Это небольшое перемещение, т.к. мои новые файлы заполнены на 90% (грубо), а старый на 12%. Однако это не очень хорошо. Но если я проверю размер этих таблиц, то в них находится всего 13Мб. Это означает, что я ожидал получить примерно 2Мб в каждом файле. Так было бы при пропорциональной заливке, что хорошо.
Если у вас куча, это не сработает без перестройки всех индексов. Как только это будет сделано, вы можете использовать команду ALTER TABLE ... REBUILD, чтобы перераспределить данные.
К сожалению, лучшим способом является полная очистка. Она рекомендуется, чтобы позволить данным постоянно равномерно распределяться по файлам при регулярной переиндексации в обычном режиме.
Если вы хотите выполнить очистку более быстро, можно сделать следующее. Сначала добавьте новую файловую группу и файл. Я сделаю это в базе данных, убедившись, что мой файл имеет достаточно места, чтобы содержать данные из моих больших таблиц.
Затем я хочу перестроить кластеризованный индекс, но перемещая его в новую файловую группу. Я буду использовать следующий код для перемещения обеих первичных ключей в новую файловую группу:
После перемещения данных нам нужно вернуть их назад. Повторим то же действие, но в другую файловую группу.
Если проверим файлы, то увидим следующее:

Теперь наш первый файл имеет 62% свободного пространства, а другие 3 файла - 75%. Довольно сбалансировано. Видно использование файла Temp, который не почистили, но мы можем удалить этот файл и файловую группу таким образом:
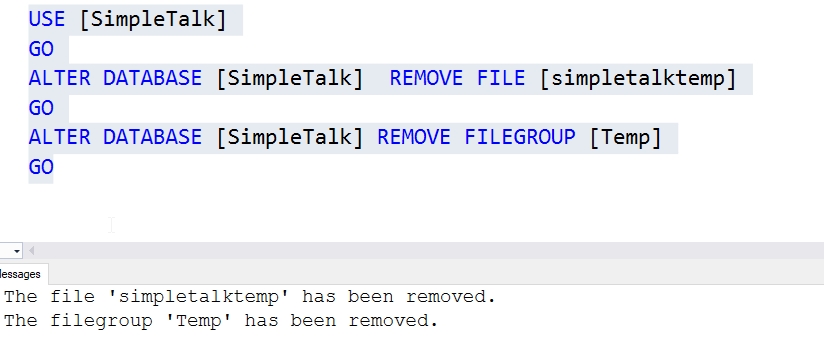
Не забудьте почистить. Если у вас есть пространство в существующей файловой группе, вы можете сделать то же самое, указывая эту файловую группу вместо Temp, когда перестраиваете кластеризованный индекс.
В этой статье демонстрируется, что SQL Server не распределяет автоматически данные по файлам, если вы добавляете их в файловую группу. Вам нужно вручную это делать, или просто позволить естественным образом прийти к этому со временем. Любой способ будет работать, но остерегайтесь большой активности в более пустом файле, пока это состояние не достигнуто.
Также убедитесь, что вы устанавливаете одинаковые размеры и автоувеличение с исходным файлом, чтобы обеспечить эффективное функционирование вашего экземпляра.
Сценарий
Рассмотрим небольшой пример, который проиллюстрирует нашу цель. Когда у вас будет больше данных, проблема усугубится, но эффект остается тем же. Мы предполагаем, что у вас есть база данных с некоторым количеством данных. Вы можете видеть, что у меня имеется несколько таблиц с небольшим числом строк.
Однако моей базе данных не хватает места. По моим оценкам, если я добавляю несколько МБ данных в день, то скоро у меня закончится место.
По умолчанию у меня есть одна файловая группа с единственным файлом. Как можно видеть, я имею файл на 128Мб и журнал размером 8Мб:
Обычно в таких ситуациях следует проявить активность и добавить несколько файлов данных для распределения нагрузки. Тут вы можете увидеть, что мы добавили 3 дополнительных файла данных в нашу базу. Когда я это делаю, то добавляю файлы того же размера, что и оригинальный файл. Это лучший способ гарантировать сбалансированность файловой группы.
Замечание. Я показываю это в графическом интерфейсе, но вы должны взять скрипт и выполнить его в команде ALTER DATABASE, а не визуальными действиями в Management Studio.
Теперь я могу сделать запрос к моим файлам. Для этого я выполню следующий код:
SELECT
FILE_Name = A.name,
FILEGROUP_NAME = fg.name,
FILESIZE_MB = CONVERT(DECIMAL(10, 2), A.size / 128.0),
USEDSPACE_MB = CONVERT(
DECIMAL(10, 2),
A.size / 128.0
- ((size / 128.0)
- CAST(FILEPROPERTY(A.name, 'SPACEUSED') AS INT) / 128.0
)
),
FREESPACE_MB = CONVERT(
DECIMAL(10, 2),
A.size / 128.0
- CAST(FILEPROPERTY(A.name, 'SPACEUSED') AS INT) / 128.0
),
[FREESPACE_%] = CONVERT(
DECIMAL(10, 2),
((A.size / 128.0
- CAST(FILEPROPERTY(A.name, 'SPACEUSED') AS INT) / 128.0
)
/ (A.size / 128.0)
) * 100
)
FROM
sys.database_files AS A
LEFT JOIN sys.filegroups AS fg
ON A.data_space_id = fg.data_space_id
WHERE A.type_desc <> 'LOG'
ORDER BY
A.type DESC,
A.name;Вот результаты, которые я получаю. Мой первый файл (simpletalkdb) почти заполнен. Он имеет 15Мб, которые могут быть использованы, а остальные файлы используются незначительно (0.06Мб). В крайнем справа столбце показан процент свободного пространства, 13% для первого файла и 99% - для остальных.
Здесь пользователи часто испытывают недоумение. Почему мои данные не переместились для балансировки файлов? Если я добавлю новые данные, вот что я увижу. Я добавлю около 30 мегабайт данных и повторю запрос. Теперь результаты выглядят так:
В каждый файл были добавлены некоторые данные, но распределение не равномерное. Я имею почти 12% свободного пространства в одном файле при 90% свободного пространства в других. Почему?
Пропорциональное заполнение
SQL Server использует алгоритм пропорционального заполнения, который записывает существенно больше данных в пустые файлы, чем в заполненные. Он пытается (в конечном итоге) сбалансировать данные по всем файлам. Вы можете больше прочитать об этом на SQLServerCentral и SQLskills. Это алгоритм циклической записи, который решает, в какой файл писать, и, чем больше каждый файл имеет свободного пространства, тем больше данных в него записывается.
На практике лучше иметь файлы одинаковых размеров и приблизительно одинаковое количество данных в каждом из них. Это сбалансирует запись и улучшит производительность.
Балансировка данных
Если в этом состоит наша цель, то как получить равномерное распределение данных по файлам? Если мы продолжим добавлять данные, то в конечном итоге добьемся этого, но мы будем иметь все больше и больше записей, приходящихся на пустые файлы, пока не достигнем желаемого.
Если у вас есть кластеризованный индекс, самый простой способ попытаться сделать это с помощью перестройки индекса. Я могу использовать следующий код на самых больших таблицах:
ALTER INDEX PK_Article ON dbo.Articles REBUILD
ALTER INDEX PK_Contacts ON dbo.Contacts REBUILDПо завершению перестройки, я могу снова выполнить запрос, показывающий распределение данных. Теперь оно выглядит так:
Это небольшое перемещение, т.к. мои новые файлы заполнены на 90% (грубо), а старый на 12%. Однако это не очень хорошо. Но если я проверю размер этих таблиц, то в них находится всего 13Мб. Это означает, что я ожидал получить примерно 2Мб в каждом файле. Так было бы при пропорциональной заливке, что хорошо.
Если у вас куча, это не сработает без перестройки всех индексов. Как только это будет сделано, вы можете использовать команду ALTER TABLE ... REBUILD, чтобы перераспределить данные.
К сожалению, лучшим способом является полная очистка. Она рекомендуется, чтобы позволить данным постоянно равномерно распределяться по файлам при регулярной переиндексации в обычном режиме.
Если вы хотите выполнить очистку более быстро, можно сделать следующее. Сначала добавьте новую файловую группу и файл. Я сделаю это в базе данных, убедившись, что мой файл имеет достаточно места, чтобы содержать данные из моих больших таблиц.
USE [master]
GO
ALTER DATABASE [SimpleTalk] ADD FILEGROUP [Temp]
GO
ALTER DATABASE [SimpleTalk] ADD FILE ( NAME = N'simpletalktemp', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\DATA\simpletalktemp.ndf' , SIZE = 20480KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Temp]
GOЗатем я хочу перестроить кластеризованный индекс, но перемещая его в новую файловую группу. Я буду использовать следующий код для перемещения обеих первичных ключей в новую файловую группу:
CREATE UNIQUE CLUSTERED INDEX PK_Article
ON dbo.Articles(ArticlesID)
WITH (DROP_EXISTING = ON )
ON Temp
GO
CREATE UNIQUE CLUSTERED INDEX PK_Contacts
ON dbo.Contacts(ContactsID)
WITH (DROP_EXISTING = ON )
ON TempПосле перемещения данных нам нужно вернуть их назад. Повторим то же действие, но в другую файловую группу.
CREATE UNIQUE CLUSTERED INDEX PK_Article
ON dbo.Articles(ArticlesID)
WITH (DROP_EXISTING = ON )
ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX PK_Contacts
ON dbo.Contacts(ContactsID)
WITH (DROP_EXISTING = ON )
ON [PRIMARY]Если проверим файлы, то увидим следующее:
Теперь наш первый файл имеет 62% свободного пространства, а другие 3 файла - 75%. Довольно сбалансировано. Видно использование файла Temp, который не почистили, но мы можем удалить этот файл и файловую группу таким образом:
Не забудьте почистить. Если у вас есть пространство в существующей файловой группе, вы можете сделать то же самое, указывая эту файловую группу вместо Temp, когда перестраиваете кластеризованный индекс.
Заключение
В этой статье демонстрируется, что SQL Server не распределяет автоматически данные по файлам, если вы добавляете их в файловую группу. Вам нужно вручную это делать, или просто позволить естественным образом прийти к этому со временем. Любой способ будет работать, но остерегайтесь большой активности в более пустом файле, пока это состояние не достигнуто.
Также убедитесь, что вы устанавливаете одинаковые размеры и автоувеличение с исходным файлом, чтобы обеспечить эффективное функционирование вашего экземпляра.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой