
Откуда появились зазоры в столбце identity?
Пересказ статьи Joe Billingham. Why Are There Gaps in the Identity Column in My SQL Database
Все чаще задают вопросы о пропущенных записях, который идентифицируются зазорами в столбце identity в таблице.
Если в таблице, упорядоченной по столбцу identity, мы видим “1, 2, 3, 5”, то запись 4 должна была быть удалена, верно? Ну, хотя это возможно, оно не является единственной причиной, так как есть и другие причины такого "отсутствия" ID.
Давайте начнем с простой таблицы, имеющей всего 3 столбца, первым из которых является столбец Identity (1,1) с именем ID. Это означает, что он начинается с 1 и увеличивается на 1 с каждой следующей записью. Другие 2 столбца - Forename и Surname - определены как VARCHAR(20) NOT NULL.
Поместим в таблицу несколько записей, чтобы посмотреть, как заполняется столбец ID:
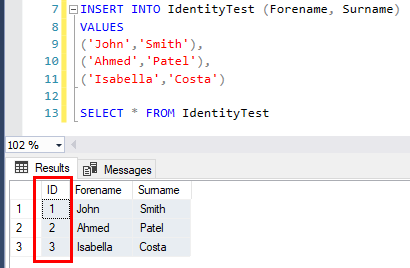
Обычно данные вставляются в таблицу в рамках транзакции. SQL Server присвоит всем вставленным записям идентификатор (ID), однако если транзакция откатывается, то так как записи не были зафиксированы, идентификаторы не возвращаются.
Вот демонстрация этого действия. Сначала мы видим добавленные в таблицу данные и выполняется откат (обратите внимание, что оператор SELECT находится внутри ROLLBACK):

ID появились, как ожидалось, поэтому давайте продолжим, но теперь зафиксируем (COMMIT) эти записи:
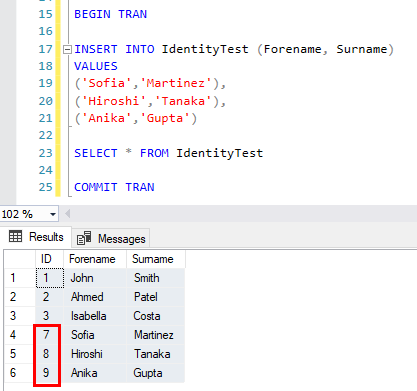
Как можно видеть, ID 4, 5 и 6 не вернулись и не будут записываться в таблицу, наши новые записи начинаются с ID=7.
Другим примером, когда это может произойти, является вставка записей, которые содержат ошибки. Напомню, что наша простая таблица имеет условие NOT NULL для обоих полей имен. Давайте попробуем вставить запись с NULL:

Мы ожидаемо получаем ошибку, поэтому, чтобы исправить ее, напишем корректный запрос:

Видно, что ID 10 был назначен ошибочному INSERT, и этот ID не был возвращен, когда произошла ошибка. Наша новая запись снова пропустила идентификатор и началась с 11.
Иногда вы увидите зазоры в 10000 и более номеров в столбце ID. Это может произойти, когда SQL Server выполняет пакеты вставок. С целью повышения производительности «куски» идентификаторов предварительно резервируются для транзакции, а затем после завершения остатки освобождаются. Например, если вы записываете 8000 строк в таблицу за один проход, SQL Server может выделить 10000 ID, а затем освободить 8001 - 10000 как только INSERT завершится. Однако, если запись в таблицу одновременно выполняет другая транзакция, то в силу уровня изоляции этой записи будет предоставлен ID 10001. Кроме того, если во время массовой вставки происходит сбой сервера, идентификаторы не сбрасываются.
Такой "пропуск" ID является намеренным поведением в SQL (столбцы идентификаторов в выделенном пуле SQL по своей природе не могут быть последовательными). Столбец identity в SQL Server предназначен для присвоения уникального ID каждой записи в каждой транзакции и автоматического инкрементирования значения в таблице, и не более того. Столбец ID никогда не следует явно использовать для отслеживания числа записей в таблице.
Имеется функция DBCC CHECKIDENT, которую можно использовать для отчета о состоянии столбца ID. Ниже показан вызов этой функции, вставка и откат нескольких записей (для использования идентификаторов, как упомянуто выше), и последующей проверки:

Текущим значение столбца ID (COLUMN VALUE) является 11, пока записи не были зафиксированы, но текущее присвоенное значение для таблицы теперь является 15, т.к. 12, 13, 14 и 15 все были использованы. Мы можем протестировать это, зафиксировав эти записи в таблице:

Как ожидалось, записи вставляются, начиная с 16.
Эта функция имеет больше аргументов, которые позволяют сбрасывать значение для таблицы и манипулировать столбцом ID, однако я не хочу углубляться в это, т.к. существует множество рисков, и следует провести некоторое исследование перед выполнением подобных действий.
Более подробную информацию о DBCC CHECKIDENT можно найти здесь.
Поместим в таблицу несколько записей, чтобы посмотреть, как заполняется столбец ID:
Обычно данные вставляются в таблицу в рамках транзакции. SQL Server присвоит всем вставленным записям идентификатор (ID), однако если транзакция откатывается, то так как записи не были зафиксированы, идентификаторы не возвращаются.
Вот демонстрация этого действия. Сначала мы видим добавленные в таблицу данные и выполняется откат (обратите внимание, что оператор SELECT находится внутри ROLLBACK):
ID появились, как ожидалось, поэтому давайте продолжим, но теперь зафиксируем (COMMIT) эти записи:
Как можно видеть, ID 4, 5 и 6 не вернулись и не будут записываться в таблицу, наши новые записи начинаются с ID=7.
Другим примером, когда это может произойти, является вставка записей, которые содержат ошибки. Напомню, что наша простая таблица имеет условие NOT NULL для обоих полей имен. Давайте попробуем вставить запись с NULL:
Мы ожидаемо получаем ошибку, поэтому, чтобы исправить ее, напишем корректный запрос:
Видно, что ID 10 был назначен ошибочному INSERT, и этот ID не был возвращен, когда произошла ошибка. Наша новая запись снова пропустила идентификатор и началась с 11.
Иногда вы увидите зазоры в 10000 и более номеров в столбце ID. Это может произойти, когда SQL Server выполняет пакеты вставок. С целью повышения производительности «куски» идентификаторов предварительно резервируются для транзакции, а затем после завершения остатки освобождаются. Например, если вы записываете 8000 строк в таблицу за один проход, SQL Server может выделить 10000 ID, а затем освободить 8001 - 10000 как только INSERT завершится. Однако, если запись в таблицу одновременно выполняет другая транзакция, то в силу уровня изоляции этой записи будет предоставлен ID 10001. Кроме того, если во время массовой вставки происходит сбой сервера, идентификаторы не сбрасываются.
Такой "пропуск" ID является намеренным поведением в SQL (столбцы идентификаторов в выделенном пуле SQL по своей природе не могут быть последовательными). Столбец identity в SQL Server предназначен для присвоения уникального ID каждой записи в каждой транзакции и автоматического инкрементирования значения в таблице, и не более того. Столбец ID никогда не следует явно использовать для отслеживания числа записей в таблице.
Имеется функция DBCC CHECKIDENT, которую можно использовать для отчета о состоянии столбца ID. Ниже показан вызов этой функции, вставка и откат нескольких записей (для использования идентификаторов, как упомянуто выше), и последующей проверки:
Текущим значение столбца ID (COLUMN VALUE) является 11, пока записи не были зафиксированы, но текущее присвоенное значение для таблицы теперь является 15, т.к. 12, 13, 14 и 15 все были использованы. Мы можем протестировать это, зафиксировав эти записи в таблице:
Как ожидалось, записи вставляются, начиная с 16.
Эта функция имеет больше аргументов, которые позволяют сбрасывать значение для таблицы и манипулировать столбцом ID, однако я не хочу углубляться в это, т.к. существует множество рисков, и следует провести некоторое исследование перед выполнением подобных действий.
Более подробную информацию о DBCC CHECKIDENT можно найти здесь.
Ссылки по теме
- Работа со столбцами identity в SQL Server
- Пропуски в столбце SQL Identity и пересчет в SQL Server, Oracle и PostgreSQL
- Как заменить столбец identity порядковым номером
- Как найти недостающие строки в таблице
- Разница между суррогатным и естественным ключом, и их использование в SQL Server
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой