
Оптимизация плана с учетом параметров в SQL Server 2022, когда PSP может помочь вашим запросам выполняться быстрее
Пересказ статьи Erik Darling. SQL Server 2022 Parameter Sensitive Plan Optimization: When PSP Can Help Your Queries Go Faster
Раньше я использовал эту процедуру в качестве примера. Это отличная демонстрация прослушивания параметра.
Почему отличная? Потому что имеется только одно значение в таблице Posts, которое вызывает проблемы. Эта проблема возникает, потому что кто-то ненавидит нормализацию.
Лучшее, что тут можно было сделать, это иметь отдельные таблицы для вопросов ответов. Поскольку у нас этого нет, мы получаем странный сценарий.
Таблица Posts, поскольку вопросы и ответы находятся вместе, имеет определенные характеристики, которые не могут быть общими для разных типов постов:
Есть и другие примеры, но эти два являются наиболее очевидными. В любом случае, по этой причине каждый вопрос имеет нулевой ParentId, а каждый ответ имеет ParentId вопроса, для которого он дан.
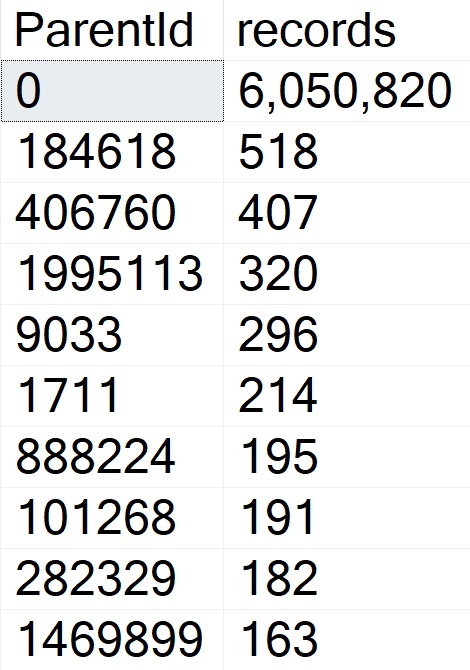
Т.е. при приблизительно 6 миллионах вопросов в таблице Posts имеется около 6 миллионов строк с ParentId, равным нулю, и около 11 миллионов строк с другим значениями.
При уровне совместимости 150 я выполню эту процедуру таким образом:
План выполнения будет общим, и второе выполнение его использует:
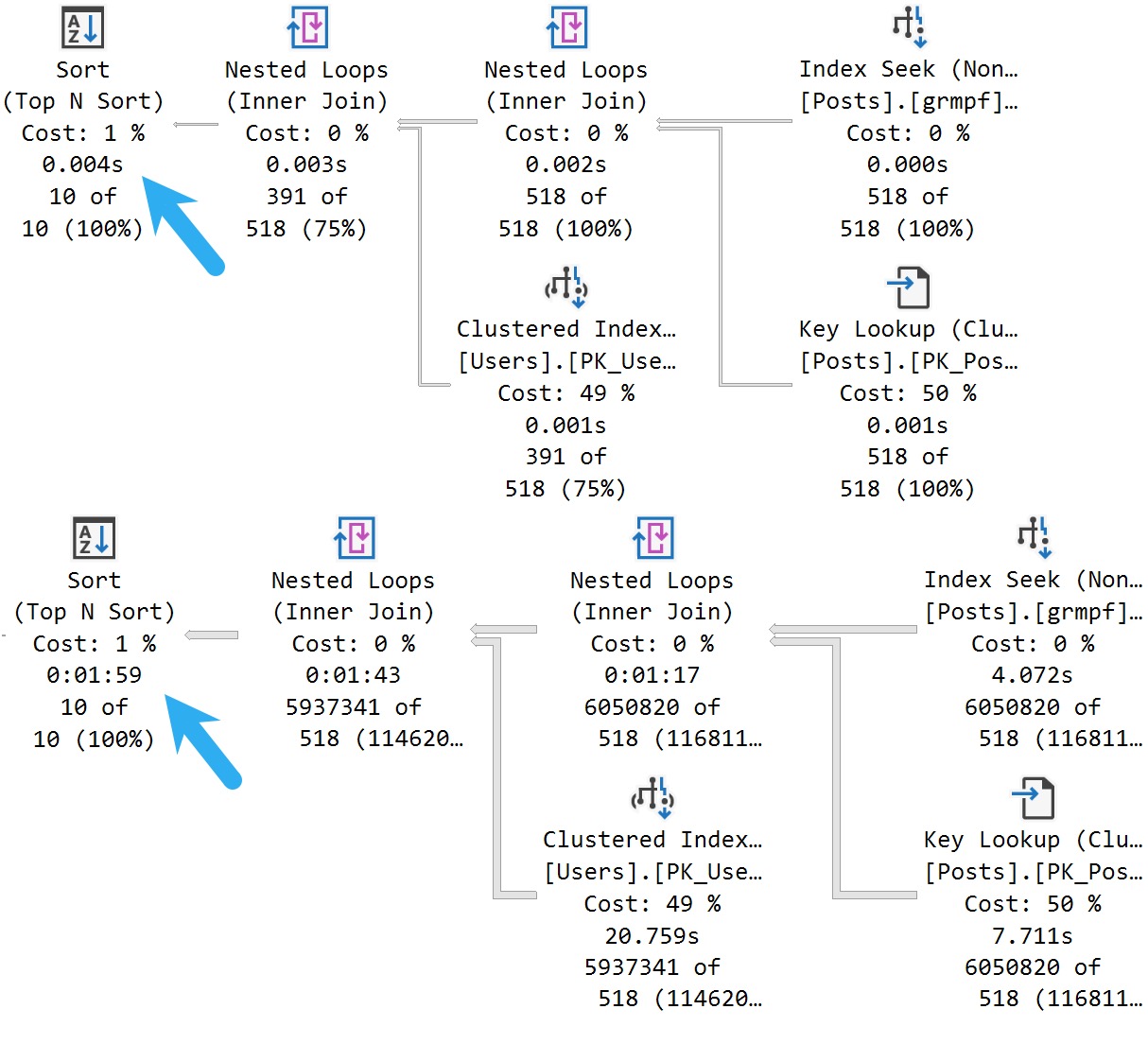
От 4 мс к 2 минутам - это довольно плохо.
При уровне совместимости 160, если я выполню то же самое, планы станут отличаться для каждого выполнения:
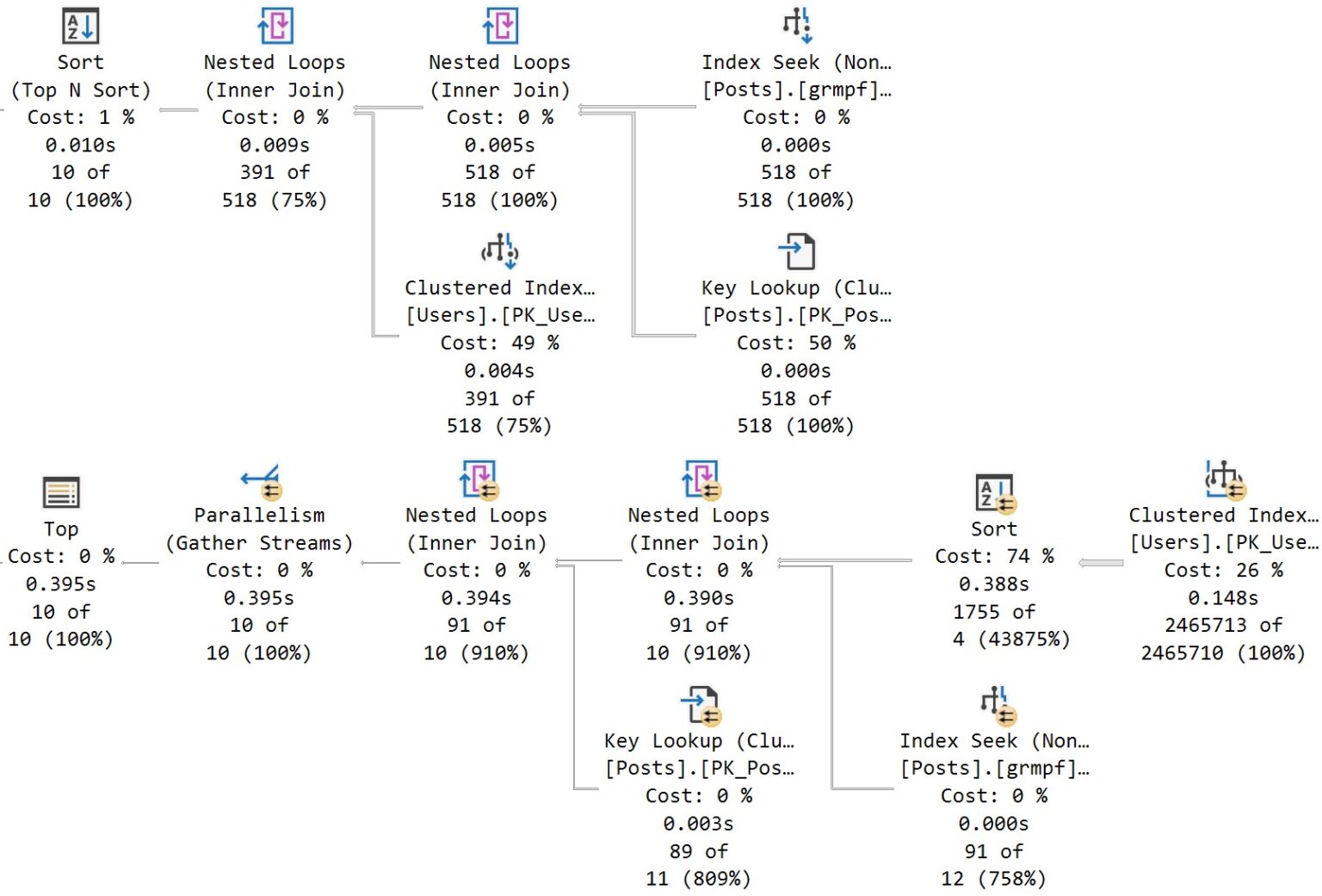
Эта ситуация много лучше. Каждый отдельный план вполне годится для повторного использования. Это в точности тот вид махинаций с планом запроса, которого следует избегать.
Единственным отличием в тексте запроса является QueryVariantID:
А в Query Store у нас есть вот такие милашки:
Хорошая работа, SQL Server 2022.
Таблица Posts, поскольку вопросы и ответы находятся вместе, имеет определенные характеристики, которые не могут быть общими для разных типов постов:
- Ответы не могут иметь ответов
- Вопросы могут не иметь родительских вопросов
Есть и другие примеры, но эти два являются наиболее очевидными. В любом случае, по этой причине каждый вопрос имеет нулевой ParentId, а каждый ответ имеет ParentId вопроса, для которого он дан.
Т.е. при приблизительно 6 миллионах вопросов в таблице Posts имеется около 6 миллионов строк с ParentId, равным нулю, и около 11 миллионов строк с другим значениями.
Текущие дела
При уровне совместимости 150 я выполню эту процедуру таким образом:
EXEC dbo.OptionalRecompile
@ParentId = 184618;
EXEC dbo.OptionalRecompile
@ParentId = 0;План выполнения будет общим, и второе выполнение его использует:
От 4 мс к 2 минутам - это довольно плохо.
2OH22
При уровне совместимости 160, если я выполню то же самое, планы станут отличаться для каждого выполнения:
Эта ситуация много лучше. Каждый отдельный план вполне годится для повторного использования. Это в точности тот вид махинаций с планом запроса, которого следует избегать.
Единственным отличием в тексте запроса является QueryVariantID:
option (PLAN PER VALUE(QueryVariantID = 2, predicate_range([StackOverflow2013].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
option (PLAN PER VALUE(QueryVariantID = 3, predicate_range([StackOverflow2013].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))А в Query Store у нас есть вот такие милашки:
SELECT qspf.* FROM sys.query_store_plan_feedback AS qspf;+------------------+---------+------------+--------------+-----------------------+-------+-------------------+
| plan_feedback_id | plan_id | feature_id | feature_desc | feedback_data | state | state_desc |
+------------------+---------+------------+--------------+-----------------------+-------+-------------------+
| 6 | 3 | 1 | CE Feedback | {"Feedback hints":""} | 1 | NO_RECOMMENDATION |
| 7 | 2 | 1 | CE Feedback | {"Feedback hints":""} | 1 | NO_RECOMMENDATION |
+------------------+---------+------------+--------------+-----------------------+-------+-------------------+
Хорошая работа, SQL Server 2022.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой