
Обзор функции медианы на SQL
Пересказ статьи Gauri Mahajan. Overview of the SQL Median function
Введение
Расчеты являются неотъемлемой частью анализа данных. Часто бизнес-логика, внедренная в объектах базы данных, включает огромное число вычислений с использованием разнообразных математических формул и операторов. Важную роль в этих вычислениях играет статистика. Когда при больших объемах данных точные вычисления для каждого элемента данных становятся невозможными, на помощь приходит статистика. Статистику можно разделить на две ветви - описательную и выведенную. По большей части базовые вычисления используют описательную статистику, а на продвинутом уровне, где внедряются такие вещи, как машинное обучение, выведенная статистика, подобная методам регрессии, классификации и т.д., выходит на первый план. Описательная статистика включает ту часть статистики, при которой мы выполняем профилирование или исследование данных для описания характеристик данных. Некоторыми простыми примерами статистических вычислений являются max, min, mean, median, mode и т.п., которые почти каждый из вас должен знать. Чтобы сделать для разработчиков баз данных удобным применять эту функциональность, базы данных часто делают обертку этой функциональность в виде статистических функций. Многим может показаться удивительным, что в то время как функции типа min, max и avg повсеместно присутствуют в базах данных, о функции медианы этого сказать нельзя. Будь-то SQL Server или PostgreSQL, во многих версиях этих промышленных баз данных мы не сможем найти готовой к использованию функции медианы, чтобы использовать ее функциональность, и мы должны прибегнуть к программированию на SQL для выполнения подобных вычислений. Хотя для этого может потребоваться сложный расчет, реализовать его не так уж сложно.
Установка экземпляра Azure SQL
Для создания для медианы функции SQL нам потребуется иметь базу данных с некоторыми тестовыми данными. Если у нас их нет, мы можем их создать. С точки зрения упрощения и ускорения установки вы можете использовать экземпляр SQL Server, если у вас он уже имеется. Если нет, альтернативой может послужить использование облачного аккаунта и установки экземпляра в облаке. Для тех, у кого не установлена база данных, мы вкратце рассмотрим установку экземпляра Azure SQL в облаке Azure.
Для создания нового экземпляра Azure SQL авторизуйтесь на портале Azure, перейдите на панель службы Azure SQL и щелкните кнопку создания нового экземпляра. Активируется мастер создания экземпляра, и мы перейдем на экран, показанный ниже.
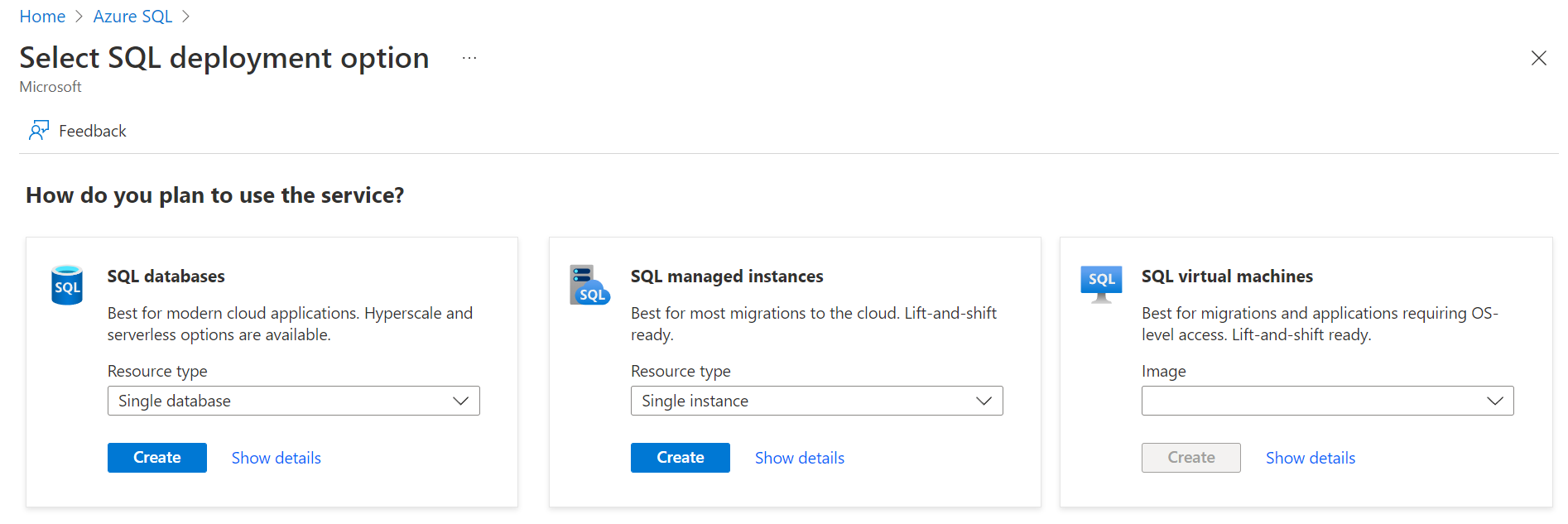
Мы намереваемся использовать вариант SQL Database и тип ресурса единичная база данных (single database). Щелкните кнопку Create для перехода к следующему шагу. Теперь мы перейдем к самому мастеру, с помощью которого проделаем все шаги, необходимые для создания нового экземпляра. Пройдите по шагам и заполните соответствующие пункты. По достижению страницы дополнительных настроек опцию использования существующих данных следует установить в значение Sample, как показано ниже. При этом будет создана учебная база данных AdventureWorkLT. Это один из наиболее легких способов создания базы данных, содержащей тестовые данные.
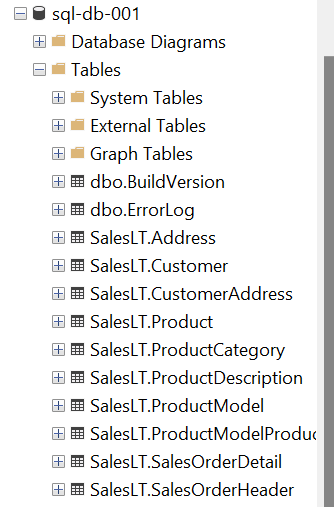
После создания экземпляра баз данных нам потребуется редактор для доступа к этому экземпляру. SQL Server Management Studio (SSMS) является свободно распространяемым редактором от Microsoft, который может использоваться для доступа к экземпляру баз данных, размещенному в базе данных Azure SQL. Предполагается, что вы уже установили ее и можете получить доступ к экземпляру баз данных. Тогда доступ к экземпляру будет выглядеть, как показано ниже с уже созданными тестовыми данными.
Что такое медиана?
В двух словах, медиана - это среднее значение в диапазоне отсортированных значений. Скажем, если у нас есть диапазон значений от 1 до 11, то число 6 будет медианой, т.к. это среднее значение, которое находится между верхней и нижней половинами диапазона. Если диапазон включает четное число значений, то медианой будет 5.5.
Создание функции медианы SQL - метод 1
Мы узнали, как вычислить медиану. Применив ту же методологию, мы можем легко реализовать функциональность медианы. Давайте для простоты создадим новую таблицу и добавим в нее несколько случайных значений, как показано ниже.
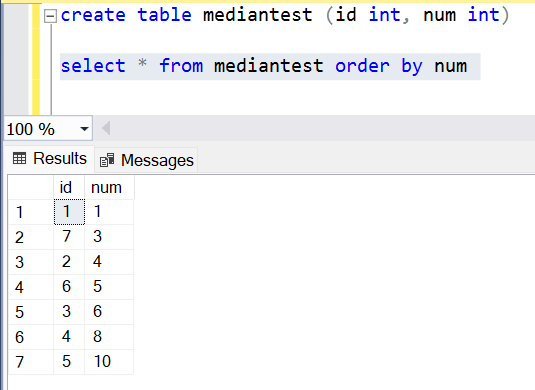
После создания таблицы мы можем выполнить запрос к ее данным в нескольких частях, и скомбинировать их, используя функцию RANK и CTE. Наконец, мы могли бы запросить 50 процентов данных в возрастающем порядке и выбрать из них максимальное значение, которое и было бы средним. А затем мы могли бы запросить другие 50 процентов данных в убывающем порядке и выбрать минимальное значение, которое опять таки было бы средним значением. И мы либо получим одно и то же значение дважды, либо два значения, находящихся на границе первой и второй половин. Так ли иначе, сложив эти два значения и разделив сумму на 2, мы получим медиану. Эта логика может быть применена к функции медианы SQL, как показано ниже.
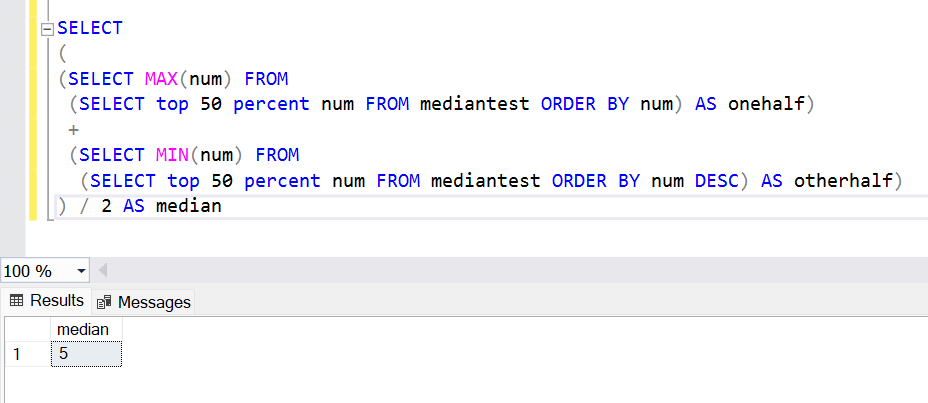
Таким образом, мы можем легко создать функцию медианы в SQL, используя эту логику и обернув ее в функцию. Это один из способов, который может быть не самым эффективным с точки зрения его выполнения оптимизатором запросов. SQL Server предоставляет еще одну функцию, с помощью которой можно обеспечить функциональность медианы. Давайте ее рассмотрим.
Создание функции медианы SQL - метод 2
В SQL Server имеется функция с именем percentile_cont, которая вычисляет и интерполирует данные на основе заданного процентиля, являющегося входным параметром функции. Функция имеет следующий синтаксис:

Параметр numeric_literal - это требуемое нам значение процентиля. В нашем случае медиана является центром диапазона, поэтому процентиль должен быть 0.5. Группа, которую мы собираемся использовать, - это поле id, так как мы хотим найти процентиль для группы записей. В пределах группы эта функция должна разбить данные по заданному ключу. Если у нас имеются уникальные значения ключа для каждой записи, мы не получим желаемый вывод. В нашем случае мы хотим найти медиану для 7 записей, имеющихся в нашей таблице. Т.е. функция должна разбить данные по ключу, и мы хотим, чтобы все наши записи находились в одной и той же секции. Для этого мы можем просто обновить записи, чтобы они имели один и тот же id. Тогда они станут частью одной и той же секции при выполнении функции. После обновления ключа, чтобы сделать его общим для всех записей, они станут такими:

Теперь, когда данные подготовлены, пора сформулировать запрос. Запрос показан ниже. Здесь мы выбираем существующие поля и добавляем новое для вычисления медианы с помощью встроенной функции percentile_cont. Мы передаем в эту функцию значение параметра 0.5. Мы упорядочиваем данные по числовым значениям, среди которых мы хотим найти медиану, и разбиваем данные по полю id. Поскольку все записи имеют один и тот же id, они попадают в одну и ту же секцию, для которой затем вычисляется медиана.
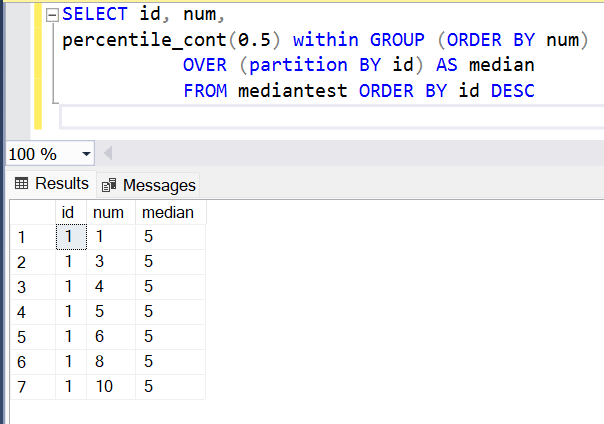
Результат выполнения запроса показан на рисунке. Значение медианы для заданного диапазона данных равно 5. Логика может быть легко обернута функцией с параметризованным значением.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой