
Общие шаблоны плана запроса для соединений: Sorting Lookups
Пересказ статьи Erik Darling. Common Query Plan Patterns For Joins: Sorting Lookups
Многие люди видят lookup и думают "добавить покрывающий индекс" вне зависимости от каких-либо сопутствующих деталей. Затем они добавляют индекс с 40 включенными столбцами для решения чего-то, что не является проблемой.
Сегодня мы собираемся рассмотреть несколько других вещей, которые могут происходить внутри lookup.
Но сначала нам нужно поговорить о том, как это возможно.
Когда у вас есть таблица с кластеризованным индексом, её ключевые столбцы будут храниться во всех ваших некластеризованных индексах.
Где они будут храниться зависит от того, как вы определите некластеризованный индекс - уникальным или нет.
Так можно поиграться дома:
Тут две таблицы. Оба определения идентичны, за исключением некластеризованного индекса на #spaces. Он уникальный.
Вот два особенных запроса.
Планы этих запросов тоже имеют небольшое отличие.

Некластеризованный индекс поддерживает два поисковых предиката. Уникальный индекс имеет один поиск плюс остаточный предикат.
Здесь нет необходимости в lookup, поскольку в обоих случаях ключевые столбцы кластеризованного индекса находятся в некластеризованном индексе. Но так же и lookup возможен.
Мы можем разместить совпадающие строки между кластеризованным и некластеризованным индексами.
К сожалению, столбцы в этой таблице закончились, поэтому нам придется бросить наших верных друзей в дебрях tempdb.
Я уверен, что уже говорил об этом ранее, но lookup могут использоваться как для выходных столбцов, так и для оценки предикатов в предложении WHERE. Выходные столбцы могут браться из любой части запроса, который запрашивает столбцы, отсутствующие в нашем некластеризованном индексе.

Поисковый предикат (Seek predicate), который вы можете видеть внизу обеих инструментальных подсказок, является связью между двумя индексами по ключевым столбцам кластеризованного индекса.
Мы собираемся начать и закончить с этим индексом:
Он просто хорош. Он не только обеспечил нас представленными выше скриншотами, но также будет рулить всеми остальными запросами, которые мы собираемся рассмотреть.
Изумительно.
Кластеризованный индекс на таблице Posts называется Id. Поскольку у нас есть некластеризованный индекс, этот столбец будет храниться в нем и упорядочиваться по ключу индекса.
Будем рассматривать следующие вещи, имеющие отношение к контексту lookup:
Вам придется подождать до утра, чтобы получить данные предварительной загрузки.
Давайте начнем с этого запроса!
Поскольку у нас предикат на неравенство по CreationDate, порядок столбца Id больше не сохраняется при выводе.
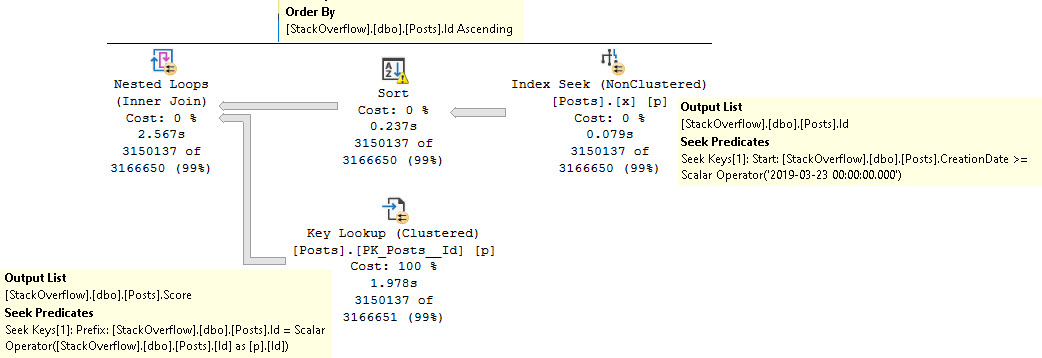
План запроса справа налево:
Сортировка нужна здесь для того, чтобы расположить столбец Id в более удобном порядке для обратного соединения с кластеризованным индексом.
Если мы немного изменим предложение WHERE, то получим слегка отличный план выполнения со скрытой сортировкой.
В свойствах соединения вложенными циклами (nested loops join) мы увидим, что оно тратило выделенную память, а свойство Optimized (оптимизировано) установлено в True.

Выделение памяти гораздо более распространено для сортировок и хеш-соединений. Подробно об этом можно почитать в блоге Крейга Фридмана:
Причина, по которой я полностью привел цитату вместо того, чтобы дать ссылку, заключается в том, что когда я собирался найти этот пост, оказалось, что из четырех моих закладок на блог Крейга только одна оказалась не битой. Постоянное перемещение и удаление контента Майкрософт, по меньшей мере, раздражает.
Lookup'ы имеют множество различных аспектов, что делает их интересными. В этом посте есть для меня несколько интересных моментов из-за аспекта выделения памяти. Я трачу много времени на решение проблем производительности запросов, связанных с тем, как SQL Server использует и балансирует память.
Войны хранилищ
Когда у вас есть таблица с кластеризованным индексом, её ключевые столбцы будут храниться во всех ваших некластеризованных индексах.
Где они будут храниться зависит от того, как вы определите некластеризованный индекс - уникальным или нет.
Так можно поиграться дома:
DROP TABLE IF EXISTS #tabs, #spaces;
CREATE TABLE #tabs
(
id int NOT NULL PRIMARY KEY,
next_id int NOT NULL,
INDEX t (next_id)
);
CREATE TABLE #spaces
(
id int NOT NULL PRIMARY KEY,
next_id int NOT NULL,
INDEX s UNIQUE (next_id)
);
INSERT
#tabs (id, next_id)
VALUES (1, 2);
INSERT
#spaces (id, next_id)
VALUES (1, 2);Тут две таблицы. Оба определения идентичны, за исключением некластеризованного индекса на #spaces. Он уникальный.
Выводы
Вот два особенных запроса.
SELECT
t.*
FROM #tabs AS t WITH(INDEX = t)
WHERE t.id = 1
AND t.next_id = 2;
SELECT
s.*
FROM #spaces AS s WITH(INDEX = s)
WHERE s.id = 1
AND s.next_id = 2;Планы этих запросов тоже имеют небольшое отличие.
Некластеризованный индекс поддерживает два поисковых предиката. Уникальный индекс имеет один поиск плюс остаточный предикат.
Здесь нет необходимости в lookup, поскольку в обоих случаях ключевые столбцы кластеризованного индекса находятся в некластеризованном индексе. Но так же и lookup возможен.
Мы можем разместить совпадающие строки между кластеризованным и некластеризованным индексами.
К сожалению, столбцы в этой таблице закончились, поэтому нам придется бросить наших верных друзей в дебрях tempdb.
Я уверен, что уже говорил об этом ранее, но lookup могут использоваться как для выходных столбцов, так и для оценки предикатов в предложении WHERE. Выходные столбцы могут браться из любой части запроса, который запрашивает столбцы, отсутствующие в нашем некластеризованном индексе.
Поисковый предикат (Seek predicate), который вы можете видеть внизу обеих инструментальных подсказок, является связью между двумя индексами по ключевым столбцам кластеризованного индекса.
Мы собираемся начать и закончить с этим индексом:
CREATE INDEX x
ON dbo.Posts(CreationDate);Он просто хорош. Он не только обеспечил нас представленными выше скриншотами, но также будет рулить всеми остальными запросами, которые мы собираемся рассмотреть.
Изумительно.
Кластеризованный индекс на таблице Posts называется Id. Поскольку у нас есть некластеризованный индекс, этот столбец будет храниться в нем и упорядочиваться по ключу индекса.
Будем рассматривать следующие вещи, имеющие отношение к контексту lookup:
- Явные сортировки
- Неявные сортировки
- Упорядоченная предварительная выборка
- Неупорядоченная предварительная выборка
Вам придется подождать до утра, чтобы получить данные предварительной загрузки.
Давайте начнем с этого запроса!
SELECT
AverageWhiteBand =
AVG(p.Score)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20190323';Поскольку у нас предикат на неравенство по CreationDate, порядок столбца Id больше не сохраняется при выводе.
План запроса справа налево:
- Поиск в нашем великолепном индексе
- Сортировка выходного столбца Id
- Снова поиск в кластеризованном индексе для получения столбца Score
Сортировка нужна здесь для того, чтобы расположить столбец Id в более удобном порядке для обратного соединения с кластеризованным индексом.
Если мы немного изменим предложение WHERE, то получим слегка отличный план выполнения со скрытой сортировкой.
SELECT
AverageWhiteBand =
AVG(p.Score)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20190923'В свойствах соединения вложенными циклами (nested loops join) мы увидим, что оно тратило выделенную память, а свойство Optimized (оптимизировано) установлено в True.
Выделение памяти гораздо более распространено для сортировок и хеш-соединений. Подробно об этом можно почитать в блоге Крейга Фридмана:
Заметим, что соединение вложенными циклами включает дополнительное ключевое слово: OPTIMIZED. Это ключевое слово говорит о том, что nested loops join может попытаться переупорядочить входные строки для улучшения производительности ввода-вывода. Это поведение подобно явной сортировке, которую мы наблюдали в двух моих предыдущих постах, но в отличие от полной сортировки, это, скорее, лучший вариант. Т.е. результаты из оптимизированного соединения вложенными циклами могут быть (а фактически с большой вероятностью будут) не полностью отсортированы.
SQL Server использует оптимизированное соединение вложенными циклами только тогда, когда оптимизатор на основе оценок стоимости и кардинального числа считает, что сортировка скорее всего не понадобится, но все же возможно, что сортировка может быть полезна в случае, если оценки стоимости и кардинального числа окажутся некорректными. Другими словами, оптимизированное соединение вложенными циклами можно полагать как "защитную меру" в тех случаях, когда SQL Server выбирает nested loops join, но было бы лучше выбрать альтернативный план типа полного сканирования или соединения вложенными циклами с явной сортировкой. Для запроса выше, в котором соединяется несколько строк, оптимизация вряд ли вообще повлияет.
Причина, по которой я полностью привел цитату вместо того, чтобы дать ссылку, заключается в том, что когда я собирался найти этот пост, оказалось, что из четырех моих закладок на блог Крейга только одна оказалась не битой. Постоянное перемещение и удаление контента Майкрософт, по меньшей мере, раздражает.
Lookup'ы имеют множество различных аспектов, что делает их интересными. В этом посте есть для меня несколько интересных моментов из-за аспекта выделения памяти. Я трачу много времени на решение проблем производительности запросов, связанных с тем, как SQL Server использует и балансирует память.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой