
Новый COUNT в городе
Пересказ статьи Greg Larsen. There is a New COUNT in Town
В течение долгого времени мы использовали функцию COUNT(DISTINCT) для подсчета числа строк с уникальными значениями в столбце таблицы. В надвигающемся SQL Server 2019 есть новый способ получения оценки числа уникальных значений строки таблицы. Это делается с помощью функции APPROX_COUNT_DISTINCT(). Эта новая функция не дает точного числа строк для каждого отличного значения в таблице, а лишь возвращает приблизительное их число. Эта новая функция потребляет меньше ресурсов, чем испытанная точная функция COUNT(DISTINCT).
Какую проблему пытается решить APPROX_COUNT_DISTINCT()?
Новая функция APPROX_COUNT_DISTINCT() пытается решить "проблему числа различных значений". В основном она состоит в том, что подсчет уникальных значений требует все больше памяти с ростом их числа. В некоторый момент SQL Server не может больше справляться с подсчетом числа уникальных значений в памяти и вынужден сбрасывать данные в tempdb. Увеличение накладных расходов в связи с этим приводит к увеличению времени выполнения.
Функция APPROX_COUNT_DISTINCT() значительно менее требовательна к памяти по сравнению с COUNT(DISTINCT), используя алгоритм HyperLogLog. Этот алгоритм позволяет оценить число уникальных значений числом свыше 1,000,000,000 с точностью вычислений 2% (процент ошибок). При этом требуется меньше 1.5 КВ памяти, что способствует более быстрому выполнению.
Если для вас скорость выполнения важнее абсолютной точности, то вы можете использовать эту функцию вместо COUNT(DISTINCT).
Вызов функции аналогичен функции COUNT(DISTINCT):
APPROX_COUNT_DISTINCT ( выражение )
"Выражение" может быть любого типа, за исключением image, sql_variant, ntext или text.
Тестирование производительности APPROX_COUNT_DISTINCT()
Для получения и сравнения метрик скорости и объема потребляемой памяти, я буду использовать гипотетический вариант использования в конкретной ситуации:
Вариант использования:
Разработать информационную панель, которая покажет количество уникальных IP-адресов, с которых заходили на наш сайт, в текущем месяце по сравнению с этим показателем в прошлом месяце.
Ситуация:
Я работаю с поисковой системой и отвечаю за построение запросов к данным, которые мы собираем. Одним из направлений является отслеживание IP-адресов посетителей нашего сайта. Мы собираем миллиарды строк данных каждый месяц. Босс поручил мне разработать запрос, который может использоваться в качестве индикатора информационной панели и который покажет рост или падение числа уникальных IP-адресов от месяца к месяцу. При этом требуется, чтобы новый запрос отрабатывал максимально быстро на таблице IP-адресов, содержащей миллиарды и миллиарды строк. Босс допускает некоторое снижение точности результата, если это даст существенный рост скорости выполнения.
Для создания среды для тестирования я разработал базу данных и наполнил таблицу с именем Visits2 миллиардом случайным образом сгенерированных данных. Вы можете найти код, используемый для создания этой базы данных в листинге 3 в конце (оригинала) статьи.
Сначала я хочу проверить, насколько быстро работает функция APPROX_COUNT_DISTINCT() по сравнению с функцией COUNT(DISTINCT). Для этого я запускал два запроса SELECT. Первый оператор SELECT использовал функцию COUNT(DISTINCT), а второй - APPROX_COUNT_DISTINCT(). Код, содержащийся в листинге 1, подсчитывает количество уникальных IP-адресов, с которых были заходы на наш сайт в июле и августе.
SET STATISTICS TIME ON;
GO
SELECT COUNT(DISTINCT IP_Address) AS NumOfIP_Addresses, DATEPART (month,VisitDate) AS MonthNum
FROM [dbo].[Visits2]
WHERE DATEPART (month,VisitDate) IN (7,
GROUP BY DATEPART (month,VisitDate);
GO
SELECT APPROX_COUNT_DISTINCT(IP_Address) AS NumOfIP_Addresses, DATEPART (month,VisitDate) AS MonthNum
FROM [dbo].[Visits2]
WHERE DATEPART (month,VisitDate) IN (7,
GROUP BY DATEPART (month,VisitDate);
Листинг 1. Код для сравнения функций COUNT(DISTINCT) и APPROX_COUNT_DISTINCT()
Этот код включает статистику по времени и запускает каждый из операторов SELECT. Я использую статистику для определения времени CPU и общего времени (elapsed time), которое потребовалось для выполнения запросов. Результаты представлены ниже.
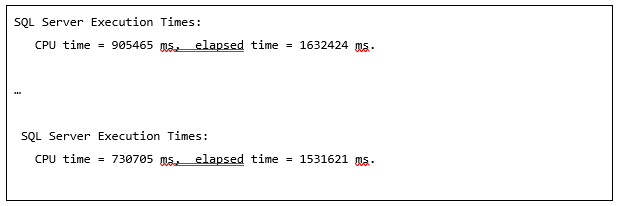
Результаты 1: замеры времени при выполнении кода из листинга 1
Как можно увидеть, APPROX_COUNT_DISTINCT использует меньше времени процессора и времени выполнения по сравнению с запросом COUNT(DISTINCT). Разница составляет немногим более 6% для времени выполнения и почти 24% для CPU.
Чтобы определить объем выделяемой памяти на каждый оператор SELECT, я использовал вывод плана выполнения. Результаты 2 демонстрируют план выполнения для этих двух запросов.
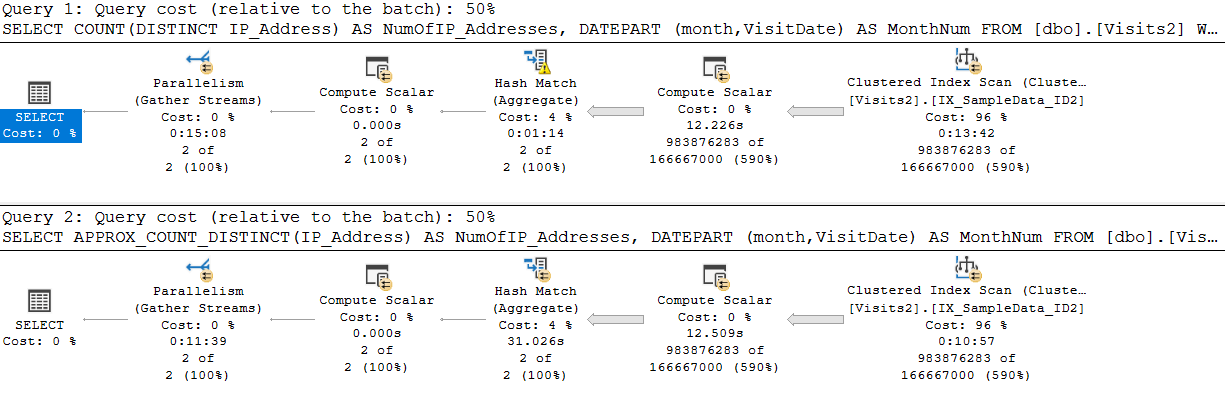
Результаты 2. План выполнения для кода на Листинге 1
Первое, что нужно отметить, сравнивая эти два плана, это то, что Cost операции Hash Match для функции COUNT(DISTINCT) более чем в два раза выше стоимости этой операции для функции APPROX_COUNT_DISTINCT().
Если поместить курсор над оператором Hash Match для функции COUNT(DISTINCT), я вижу сбрасывание на диск (Результаты 3), чего не происходит для APPROX_COUNT_DISTINCT() (Результаты 4).
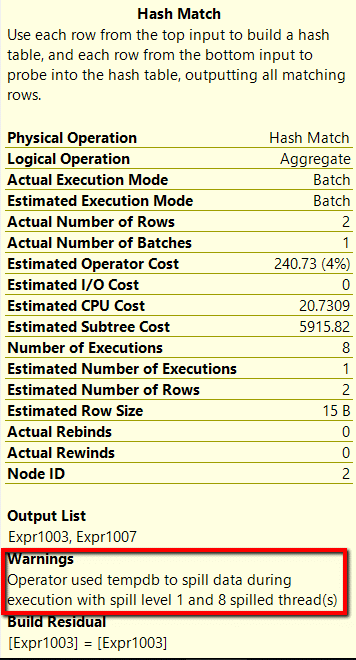
Результаты 3. Характеристики операции Hash Match для функции COUNT(DISTINCT)
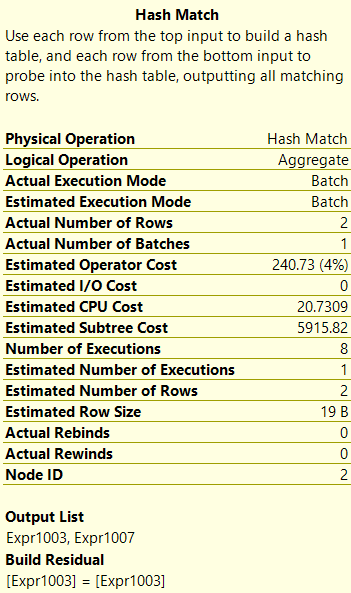
Результаты 4. Характеристики операции Hash Match для функции APPROX_COUNT_DISTINCT
Чтобы увидеть объем памяти, распределенной между двумя функциями, поместим курсор над иконкой SELECT в плане выполнения. Результат 5 относится к функции COUNT(DISTINCT), а Результат 6 - к APPROX_COUNT_DISTINCT.

Результаты 5. Выделение памяти для COUNT(DISTINCT)
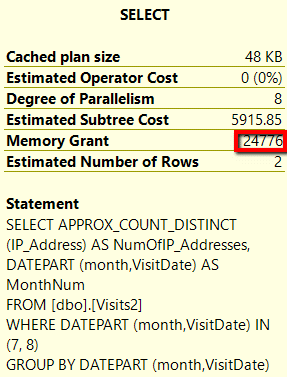
Результаты 6. Выделение памяти для APPROX_COUNT_DISTINCT
Видим, что функция COUNT(DISTINCT) требует 1,847,736 памяти, в то время как APPROX_COUNT_DISTINCT() - 24,776; это в 74 раза меньше.
Тестирование точности APPROX_COUNT_DISTINCT()
Для тестирования точности я сравнивал число различных значений, вычисляемых этими двумя функциями (см. Листинг 1). Функция COUNT(DISTINCT) вернула число 16,581,375 для июля, в то время как APPROX_COUNT_DISTINCT() - 17,075,480, т.е. разница составляет немногим более 2.97%. Поскольку это число выходит за пределы ошибки в 2%, как заявлено в документации, я связался с Майкрософт по этому поводу.
Инженер Майкрософт ответил, что ядро SQL Server использует “sophisticated analytic sampling method” для получения предполагаемого числа, и по этой причине возможно придумать такую таблицу, которая погубит метод выборки и даст совершенно неверные результаты.
Из первого теста я смог увидеть, что фактически функция APPROX_COUNT_DISTINCT() выполняется быстрей и требует меньше ресурсов по сравнению с функцией COUNT(DISTINCT). Единственной проблемой было то, что в моих тестах ошибка составила 2.97% по сравнению с заявленными 2%.
Поэтому я провел дополнительное тестирование, выполняя операторы, которые представлены ниже в Листинге 2.
SELECT COUNT(DISTINCT ID) AS COUNT_ID,
COUNT(DISTINCT I100) AS COUNT_I100,
COUNT(DISTINCT I1000) AS COUNT_I1000,
COUNT(DISTINCT I10000) AS COUNT_I10000,
COUNT(DISTINCT I1000000) AS COUNT_I1000000,
COUNT(DISTINCT I10000000) AS COUNT_I10000000
FROM Visits2;
GO
SELECT APPROX_COUNT_DISTINCT(ID) AS COUNT_ID,
APPROX_COUNT_DISTINCT(I100) AS COUNT_I100,
APPROX_COUNT_DISTINCT(I1000) AS COUNT_I1000,
APPROX_COUNT_DISTINCT(I10000) AS COUNT_I10000,
APPROX_COUNT_DISTINCT(I1000000) AS COUNT_I1000000,
APPROX_COUNT_DISTINCT(I10000000) AS COUNT_I10000000
FROM Visits2;
Листинг 2. Запросы дополнительного тестирования
Код из листинга 2 будет определять число уникальных значений для столбцов, которые содержат разное число таких значений. Результаты выполнения кода на листинге 2 представлены в Результатах 7.
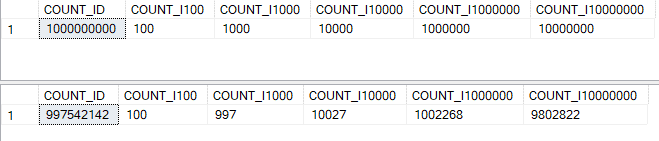
Результаты 7. Вывод исполнения кода на Листинге 2
Как вы можете увидеть на рисунке 7, функция APPROX_COUNT_DISTINCT() дает такое же число, что и функция COUNT(DISTINCT), когда число уникальных значений невелико. В моём случае менее 1000 уникальных значений. Однако для каждого столбца, который имел более 100 значений, функция APPROX_COUNT_DISTINCT() давала приближенное число, которое было больше или меньше реального значения, возвращаемого функцией COUNT(DISTINCT). При росте числа различных значений функция APPROX_COUNT_DISTINCT() дает отличные от точного значения, но достаточно близкие к нему.
Выводы на основании предварительного тестирования
На основании тестов, выполненных на сгенерированных данных, я сделал следующие наблюдения:
- Функция APPROX_COUNT_DISTINCT() возвращает число уникальных значений быстрей, чем функция COUNT(DISTINCT).
- Функция COUNT(DISTINCT) требует больше выделенной памяти, чем APPROX_COUNT_DISTINCT().
- В одной ситуации я получил число уникальных значений, которое больше чем на 2% отличалось от точного значения.
- Если число уникальных значений для данного столбца невелико, функция APPROX_COUNT_DISTINCT() возвращает то же значение, что и функция COUNT(DISTINCT).
Стоит ли начинать использовать функцию APPROX_COUNT_DISTINCT()? Хороший вопрос. Полагаю, что это зависит от конкретной ситуации. Прежде чем использовать новую функцию в рабочем окружении, я бы посоветовал разработать более тщательные тесты и выполнить их на реальных данных, чтобы убедиться в том, что погрешность удовлетворяет вашим ожиданиям.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой