
Массив и пользовательские типы данных в PostgreSQL
Пересказ статьи sabyda. Array and Custom Data Types in PostgreSQL
Введение
Как и всякая другая база данных, PostgreSQL имеет свой собственный набор базовых типов данных, таких как Boolean, Varchar, Text, Date, Time и т.д. Мы можем легко хранить такие типы как числа, дату, время и т.п., используя эти поддерживаемые типы данных, но что если нам требуется хранить несколько элементов данных в единственном столбце?
Предположим, что мы сохраняем данные сотрудников организации, и очевидно, что большинство сотрудников будет иметь несколько контактных номеров, альтернативных контактных номеров. Как нам хранить их в одном столбце, а не создавать разные столбцы для всех этих номеров? В PostgreSQL можно использовать тип данных ARRAY, который мы собираемся подробно рассмотреть.
PostgreSQL также поддерживает различные формы проверок и ограничений, накладываемых на столбец в скриптах DDL. Что если мы захотим иметь похожие ограничения для столбцов нескольких таблиц? Вместо повторяющейся записи избыточной логики ограничений в каждом скрипте DDL, мы можем использовать здесь пользовательский тип данных. Мы так же рассмотрим пользовательские типы данных позже в этой статье.
Предположим, что сотрудник может добавить несколько контактных номеров в свою запись. Нам требуется хранить эти контактные номера в единственном столбце в базе данных. Пусть первый контактный номер является первичным, а остальные все - альтернативными контактными номерами. Мы будем использовать тип данных array, чтобы разместить столбец, содержащий контактный номер для хранения нескольких номеров.
Давайте создадим таблицу сотрудников со столбцом contact_number, имеющим тип данных ARRAY. Для создания таблицы мы можем выполнить следующий запрос :
После создания таблицы мы можем записать туда некоторые данные. Мы имеем трех сотрудников, которые имеют несколько контактных номеров. Добавим их с помощью следующего запроса:
Если проверить теперь содержимое таблицы employee_info, то мы увидим:
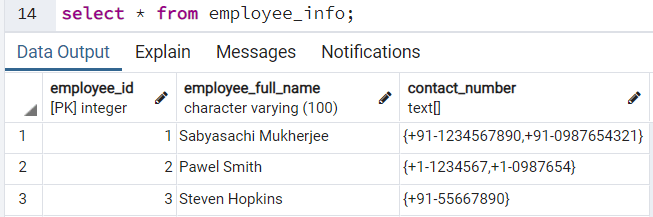
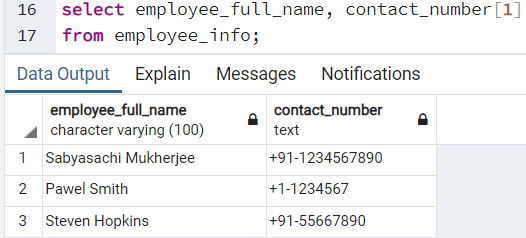
Мы можем получить доступ к элементам массива, используя индекс в квадратных скобках, []. Мы просто предполагали, что первый номер телефона каждого сотрудника является его первичным контактным номером, поэтому используемым индексом должен быть "1". Если мы хотим запросить первичный контактный номер каждого сотрудника в организации, то можем выполнить следующий запрос:
Мы получаем следующий результат:
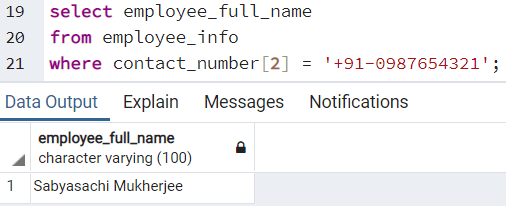
Можно выполнять также много других операций с типом данных array, так же, как мы можем это делать со столбцами других типов данных. Мы можем проверить информацию о сотруднике, у которого вторым контактным номером является "+91-0987654321", выполнив следующий запрос:
При этом будет выполнен поиск всех тех записей в таблице, для которых второй контактный номер (второй элемент массива) совпадает с заданным номером. Будет возвращен следующий результат:
Что если мы в нижеприведенном наборе данных попытаемся обратиться к третьему контактному номеру сотрудника Sabyasachi Mukherjee, который не существует?
Запрос для получения третьего контактного номера Sabyasachi должен выглядеть так:
Однако, если выполнить это запрос, мы получим в ответ NULL-значение, поскольку у данного сотрудника только 2 контактных номера. В большинстве языков, если попытаться получить доступ к элементу, индекс которого превышает размер массива, обычно возникает соответствующее исключение. Но здесь мы получаем только NULL.
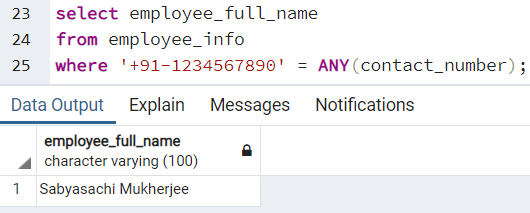
Предположим, что нам нужно выяснить имя сотрудника, имеющего конкретный номер телефона. Это потребует доступа к каждой записи в таблице и проверки того, удовлетворяет ли "какой-нибудь" контактный номер искомому. Тут мы используем функцию ANY(). В случае, если несколько сотрудников имеют один и тот же номер телефона (чего не должно быть в идеале), в результате будут напечатаны имена нескольких сотрудников.
В подобном случае мы можем выполнить следующий запрос:
Это дает нам следующий вывод:
Мы увидели, как тип данных массива на самом деле может пригодиться, когда нам требуется сохранить множество информации одной категории в одной записи.
Помимо использования встроенных типов данных, гибкость PostgreSQL придает возможность создания типов данных, определяемых пользователем. Мы можем создать пользовательский тип данных, используя либо CREATE DOMAIN, либо CREATE TYPE. CREATE DOMAIN создает пользовательский тип данных с поддержкой использования ограничений типа NOT NULL, CHECK и т.д.. CREATE TYPE создает составной пользовательский тип данных, который используется в хранимых процедурах в качестве типа данных возвращаемого значения.
Мы увидим, как использовать оба варианта - DOMAIN и TYPE - для создания пользовательских типов данных и понимания необходимости их использования в некоторых базовых сценариях, с которыми мы можем столкнуться в ежедневной работе.
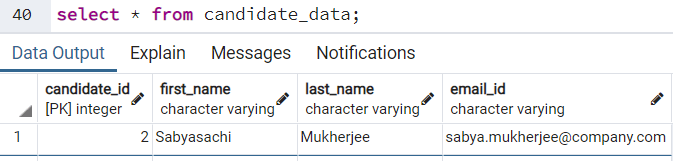
Все мы знаем, что во многих формах мы должны вводить имя и фамилию отдельно. В идеале они не должны содержать пробелов или быть пустыми/NULL. Предположим, у нас есть база данных для хранения данных кандидатов, и нам необходимо гарантировать, что ни пробелов, ни пустых значений нельзя будет ввести в столбцы имени и фамилии. Для достижения этого мы можем использовать следующий запрос создания таблицы:
Но возможен случай, когда у нас может быть много подобных таблиц, в которых хранится имя и фамилия, и везде мы должны обеспечить подобную проверку. В этой ситуации вместо наличия ограничения CHECK в каждом запросе CREATE TABLE разумно рекомендуется иметь домен, который будет выполнять проверку этих ограничений, и мы сможем повторно использовать повсюду один и тот же код.
Мы можем создать домен с подобной проверкой таким образом:
Теперь мы так можем использовать этот домен в таблице candidate_data:
Теперь, если мы попытаемся ввести имя с пробелами, система выдаст нам соответствующее сообщение об ошибке:

Однако если вставить данные без пробелов, запрос успешно сохранит запись:
Мы можем создать наш пользовательский домен, и использовать его, когда нам нужно иметь подобные ограничения и проверку в нескольких столбцах многих таблиц в базе данных. Это помогает сделать запросы DDL аккуратней и легче в обслуживании.
Нам может понадобиться информация об именах доменов в схеме, чтобы повторно их использовать. В таком случае мы можем выполнить следующий код в терминале psql:
Эта команда выведет список доменов, созданных в базе данных текущего подключения:

CREATE TYPE позволяет создать пользовательский тип данных, который будет использоваться как тип данных, возвращаемого функцией значения. Предположим, нам нужно получить имя сотрудника и первичный контактный номер из таблицы employee_info по заданному значению employee_id. Для этого мы можем создать функцию, которая будет принимать employee_id и возвращать имя и контактный номер как пользовательский тип данных.
Для начала нам нужно создать подходящий тип данных, используя следующий запрос:
Мы создали составной тип данных, который включает информацию о двух различных столбцах. В этом случае также имеется два различных типа данных. Один - VARCHAR, а другой - INT. Затем нам нужно определить функцию, которая будет принимать employee_id и возвращать имя и контактный номер, соответственно. Тело функции будет выглядеть так:
Оператор RETURN содержит новый тип данных, который мы создали как тип возвращаемого значения.
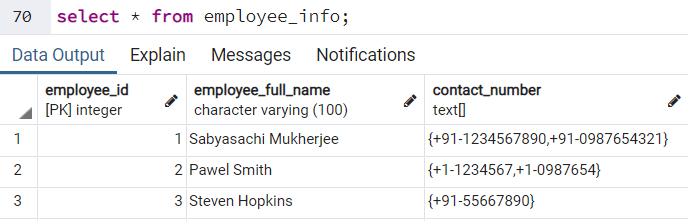
Теперь, если мы проверим информацию, содержащуюся в таблице employee_info, то увидим:
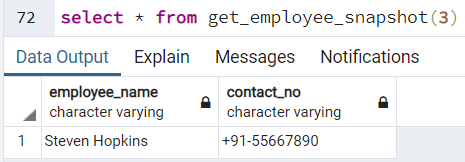
Если мы захотим получить информации о сотруднике с employee_id = 2, мы можем вызвать функцию и получить следующий результат:
Поскольку пользовательские типы данных являются составными, нам может потребоваться отредактировать их в будущем. Что если нам так же потребуется вернуть employee_id? Для редактирования существующего пользовательского типа данных мы можем использовать ключевые слова ALTER TYPE следующим образом:
Замечание. Поскольку вы меняете число полей пользовательского типа данных, вы также должны изменить функцию, чтобы она возвращала то же самое число полей, в противном случае возникнет ошибка.
Чтобы удалить любой атрибут, вы можете выполнить:
Вы можете также переименовать тип данных с помощью ALTER:
Опять таки после переименования пользовательского типа данных, не забудьте изменить ссылку на тип в каждой функции, чтобы не возникали ошибки.
Для удаления пользовательского типа данных, мы можем использовать:
Замечание. Вы сможете только тогда удалить пользовательский тип данных, если на него нет никаких ссылок в функциях или еще где-нибудь.
В этой статье мы узнали, как использовать тип данных ARRAY для хранения множества данных одного типа в одной столбце записи. Мы узнали, как использовать пользовательские домены, чтобы избежать создания одинаковых ограничений во множестве операторов DDL. Мы также научились использовать пользовательские типы данных, чтобы вернуть многие детали как единое целое.
Сценарий
Предположим, что сотрудник может добавить несколько контактных номеров в свою запись. Нам требуется хранить эти контактные номера в единственном столбце в базе данных. Пусть первый контактный номер является первичным, а остальные все - альтернативными контактными номерами. Мы будем использовать тип данных array, чтобы разместить столбец, содержащий контактный номер для хранения нескольких номеров.
Давайте создадим таблицу сотрудников со столбцом contact_number, имеющим тип данных ARRAY. Для создания таблицы мы можем выполнить следующий запрос :
CREATE TABLE employee_info (
employee_id serial PRIMARY KEY,
employee_full_name VARCHAR (100),
contact_number TEXT []
);После создания таблицы мы можем записать туда некоторые данные. Мы имеем трех сотрудников, которые имеют несколько контактных номеров. Добавим их с помощью следующего запроса:
INSERT INTO employee_info (employee_full_name, contact_number)
VALUES('Sabyasachi Mukherjee',ARRAY [ '+91-1234567890','+91-0987654321' ]);
INSERT INTO employee_info (employee_full_name, contact_number)
VALUES('Pawel Smith',ARRAY [ '+1-1234567','+1-0987654' ]);
INSERT INTO employee_info (employee_full_name, contact_number)
VALUES('Steven Hopkins',ARRAY [ '+91-55667890' ]);Если проверить теперь содержимое таблицы employee_info, то мы увидим:
Выборка конкретных данных из массива
Мы можем получить доступ к элементам массива, используя индекс в квадратных скобках, []. Мы просто предполагали, что первый номер телефона каждого сотрудника является его первичным контактным номером, поэтому используемым индексом должен быть "1". Если мы хотим запросить первичный контактный номер каждого сотрудника в организации, то можем выполнить следующий запрос:
select employee_full_name, contact_number[1]
from employee_info;Мы получаем следующий результат:
Можно выполнять также много других операций с типом данных array, так же, как мы можем это делать со столбцами других типов данных. Мы можем проверить информацию о сотруднике, у которого вторым контактным номером является "+91-0987654321", выполнив следующий запрос:
select employee_full_name
from employee_info
where contact_number[2] = '+91-0987654321';При этом будет выполнен поиск всех тех записей в таблице, для которых второй контактный номер (второй элемент массива) совпадает с заданным номером. Будет возвращен следующий результат:
Что если мы пытаемся получить доступ к индексу массива, который не существует?
Что если мы в нижеприведенном наборе данных попытаемся обратиться к третьему контактному номеру сотрудника Sabyasachi Mukherjee, который не существует?
Запрос для получения третьего контактного номера Sabyasachi должен выглядеть так:
select employee_full_name, contact_number[3]
from employee_info
where employee_full_name = 'Sabyasachi Mukherjee';Однако, если выполнить это запрос, мы получим в ответ NULL-значение, поскольку у данного сотрудника только 2 контактных номера. В большинстве языков, если попытаться получить доступ к элементу, индекс которого превышает размер массива, обычно возникает соответствующее исключение. Но здесь мы получаем только NULL.
Поиск конкретных данных в записи массивов
Предположим, что нам нужно выяснить имя сотрудника, имеющего конкретный номер телефона. Это потребует доступа к каждой записи в таблице и проверки того, удовлетворяет ли "какой-нибудь" контактный номер искомому. Тут мы используем функцию ANY(). В случае, если несколько сотрудников имеют один и тот же номер телефона (чего не должно быть в идеале), в результате будут напечатаны имена нескольких сотрудников.
В подобном случае мы можем выполнить следующий запрос:
select employee_full_name
from employee_info
where '+91-1234567890' = ANY(contact_number);Это дает нам следующий вывод:
Мы увидели, как тип данных массива на самом деле может пригодиться, когда нам требуется сохранить множество информации одной категории в одной записи.
Пользовательский тип данных
Помимо использования встроенных типов данных, гибкость PostgreSQL придает возможность создания типов данных, определяемых пользователем. Мы можем создать пользовательский тип данных, используя либо CREATE DOMAIN, либо CREATE TYPE. CREATE DOMAIN создает пользовательский тип данных с поддержкой использования ограничений типа NOT NULL, CHECK и т.д.. CREATE TYPE создает составной пользовательский тип данных, который используется в хранимых процедурах в качестве типа данных возвращаемого значения.
Мы увидим, как использовать оба варианта - DOMAIN и TYPE - для создания пользовательских типов данных и понимания необходимости их использования в некоторых базовых сценариях, с которыми мы можем столкнуться в ежедневной работе.
Пользовательский домен
Все мы знаем, что во многих формах мы должны вводить имя и фамилию отдельно. В идеале они не должны содержать пробелов или быть пустыми/NULL. Предположим, у нас есть база данных для хранения данных кандидатов, и нам необходимо гарантировать, что ни пробелов, ни пустых значений нельзя будет ввести в столбцы имени и фамилии. Для достижения этого мы можем использовать следующий запрос создания таблицы:
CREATE TABLE candidate_data (
candidate_id SERIAL PRIMARY KEY,
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
email_id VARCHAR NOT NULL,
CHECK (
first_name !~ '\s'
AND last_name !~ '\s'
)
);Но возможен случай, когда у нас может быть много подобных таблиц, в которых хранится имя и фамилия, и везде мы должны обеспечить подобную проверку. В этой ситуации вместо наличия ограничения CHECK в каждом запросе CREATE TABLE разумно рекомендуется иметь домен, который будет выполнять проверку этих ограничений, и мы сможем повторно использовать повсюду один и тот же код.
Мы можем создать домен с подобной проверкой таким образом:
CREATE DOMAIN candidate_name AS
VARCHAR NOT NULL CHECK (value !~ '\s');Теперь мы так можем использовать этот домен в таблице candidate_data:
CREATE TABLE candidate_data (
candidate_id SERIAL PRIMARY KEY,
first_name candidate_name,
last_name candidate_name,
email_id VARCHAR NOT NULL
)Теперь, если мы попытаемся ввести имя с пробелами, система выдаст нам соответствующее сообщение об ошибке:
INSERT INTO candidate_data (first_name, last_name, email_id)
VALUES('Sabya sachi','Mukherjee','sabya.mukherjee@company.com');Однако если вставить данные без пробелов, запрос успешно сохранит запись:
INSERT INTO candidate_data (first_name, last_name, email_id)
VALUES('Sabyasachi','Mukherjee','sabya.mukherjee@company.com');Мы можем создать наш пользовательский домен, и использовать его, когда нам нужно иметь подобные ограничения и проверку в нескольких столбцах многих таблиц в базе данных. Это помогает сделать запросы DDL аккуратней и легче в обслуживании.
Дополнительная информация о пользовательских доменах
Нам может понадобиться информация об именах доменов в схеме, чтобы повторно их использовать. В таком случае мы можем выполнить следующий код в терминале psql:
\dD
Эта команда выведет список доменов, созданных в базе данных текущего подключения:
Пользовательский тип данных
CREATE TYPE позволяет создать пользовательский тип данных, который будет использоваться как тип данных, возвращаемого функцией значения. Предположим, нам нужно получить имя сотрудника и первичный контактный номер из таблицы employee_info по заданному значению employee_id. Для этого мы можем создать функцию, которая будет принимать employee_id и возвращать имя и контактный номер как пользовательский тип данных.
Для начала нам нужно создать подходящий тип данных, используя следующий запрос:
CREATE TYPE employee_data AS (
employee_name VARCHAR,
contact_no VARCHAR
);Мы создали составной тип данных, который включает информацию о двух различных столбцах. В этом случае также имеется два различных типа данных. Один - VARCHAR, а другой - INT. Затем нам нужно определить функцию, которая будет принимать employee_id и возвращать имя и контактный номер, соответственно. Тело функции будет выглядеть так:
CREATE OR REPLACE FUNCTION get_employee_snapshot (e_id INT)
RETURNS employee_data AS
$$
SELECT
employee_full_name,
contact_number[1]
FROM
employee_info
WHERE
employee_id = e_id ;
$$
LANGUAGE SQL;Оператор RETURN содержит новый тип данных, который мы создали как тип возвращаемого значения.
Теперь, если мы проверим информацию, содержащуюся в таблице employee_info, то увидим:
Если мы захотим получить информации о сотруднике с employee_id = 2, мы можем вызвать функцию и получить следующий результат:
Поскольку пользовательские типы данных являются составными, нам может потребоваться отредактировать их в будущем. Что если нам так же потребуется вернуть employee_id? Для редактирования существующего пользовательского типа данных мы можем использовать ключевые слова ALTER TYPE следующим образом:
ALTER TYPE employee_data ADD ATTRIBUTE employee_number INT;Замечание. Поскольку вы меняете число полей пользовательского типа данных, вы также должны изменить функцию, чтобы она возвращала то же самое число полей, в противном случае возникнет ошибка.
Чтобы удалить любой атрибут, вы можете выполнить:
ALTER TYPE employee_data DROP ATTRIBUTE employee_number;Вы можете также переименовать тип данных с помощью ALTER:
ALTER TYPE employee_data RENAME TO EMPLOYEE_SNAPSHOT_DATA;Опять таки после переименования пользовательского типа данных, не забудьте изменить ссылку на тип в каждой функции, чтобы не возникали ошибки.
Для удаления пользовательского типа данных, мы можем использовать:
DROP TYPE EMPLOYEE_SNAPSHOT_DATA;Замечание. Вы сможете только тогда удалить пользовательский тип данных, если на него нет никаких ссылок в функциях или еще где-нибудь.
Заключение
В этой статье мы узнали, как использовать тип данных ARRAY для хранения множества данных одного типа в одной столбце записи. Мы узнали, как использовать пользовательские домены, чтобы избежать создания одинаковых ограничений во множестве операторов DDL. Мы также научились использовать пользовательские типы данных, чтобы вернуть многие детали как единое целое.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой