
Логические операции чтения SQL Server - о чем они на самом деле говорят нам?
Пересказ статьи Ami Levin. SQL Server Logical Reads – What do they really tell us?
Трассировка SQL Server, которую наиболее часто используют администраторы баз данных для оценки производительности запросов, предоставляет счетчик 'logical reads' (логические чтения), на который многие администраторы полагаются при оценке производительности ввода/вывода запросов. В данной статье мы проверим истинность этих счетчиков и приведем примеры, которые покажут, что эти счетчики иногда могут ввести в заблуждение...
Я уверен, что вы все использовали трассировки SQL для оценки производительности запросов и пакетов. Для этого наиболее часто используют столбцы Duration, CPU, Writes и Reads. Фактически только эти метрики доступны в событии трассировки SQL Server для оценки производительности. Общим заблуждением является то, что "уменьшение числа чтений, которое выполняет запрос, является важным аспектом улучшения его производительности". Хотя это и справедливо во многих случаях, в этой статье я хочу обратить ваше внимание на тот факт, что "это не обязательно так?" иногда наоборот оказывается справедливым.
Во-первых, нам следует понять, что действительно означает Read. Вот цитата из документации Майкрософт об архитектуре ввода/вывода, которая четко определяет логические и физические чтения: "Ввод/вывод экземпляра SQL Server делится на логический и физический ввод/вывод. Логические чтения имеет место всякий раз, когда движок базы данных запрашивает страницу из кэша буфера. Если страницы не оказывается в кэше, то выполняется физическое чтение для считывания страницы в кэш буфера. Если страница в данный момент уже находится в кэше, никаких физических чтений не выполняется, а буферный кэш просто использует страницу, уже находящуюся в памяти."
Важно помнить, что SQL Trace считает логические чтения, а не физические. Я полагаю, что это обусловлено тем фактом, что физические чтения являются общими для всех в данное время выполняемых пакетов на сервере и, следовательно, не обязательно привязаны к конкретному событию, несмотря на то, что они всегда вызываются конкретным событием. В зависимости от текущего содержимого кэша, одни и те же запросы или пакеты могут вызывать запуск физических чтений, а могут и не вызывать. Физические чтения действительно могут создавать проблемы с производительностью, поскольку задействуют подсистемы хранения, которые, к сожалению, до сих пор существенно более медленные по сравнению с логическими чтениями, которые выполняются в сверхбыстрых современных модулях памяти.
Метрики физических чтений доступны при использовании STATISTICS IO и из динамических представлений SQL Server.
Я думаю, что лучший способ объяснения - это примеры. Для демонстрации я использовал SQL Server 2005 SP3 и учебную базу AdventureWorks.
Поскольку мы не можем знать заранее содержимое кэша в данный момент времени при выполнении кода примера, я явным образом очистил кэш для моделирования худшего сценария с пустым кэшем.
Давайте возьмем следующий запрос и предположим, что я решаю задачу оптимизации производительности:
Вот метрики для этого запроса, записанные на моем ПК с помощью profiler:
Замечание: числа, приведенные ниже, показывают среднее значение нескольких запусков при непрогретом кэше.
CPU: ~40, Reads: ~840, Duration ~300ms.
Опция "missing indexes" (отсутствующие индексы) в Management Studio предлагает мне добавить следующий индекс:
Будучи послушным DBA, я сразу создаю этот индекс и снова выполняю тот же запрос. Теперь я получил следующие метрики производительности в профайлере:
CPU: ~20, Reads: ~4000, Duration ~200ms.
Что произошло? Улучшило ли производительность добавление этого индекса или ухудшило её? Кажется, что данная информация противоречива. CPU и продолжительность (duration), видимо, существенно улучшились, но число логических чтений увеличилось почти в 5 раз!
Чтобы понять, что происходит под капотом, мы должны обратиться к плану выполнения.
Вот оригинальный план выполнения запроса до создания предложенного индекса:

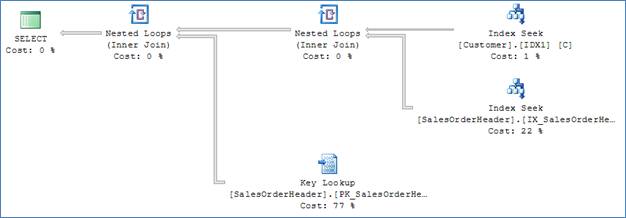
А вот план, который оптимизатор выбрал после создания предложенного индекса:
В исходном плане оптимизатор для соединения таблиц выбрал физический оператор hash match. При использовании hash match доступ к каждому значению custimerID из каждой соединяемой таблицы необходим только один раз. Блоки, определяемые хэш-ключом, строились на основании значений custimerID из таблицы Custimer, а затем проверялись сканированием таблицы SalesOrderHeader. Каждую страницу требуется прочитать только раз, и возвращаются все значения. Вы можете проверить это подсчитав число страниц, используемое обеими таблицами - таблица Customer ~ 110 страниц, а таблица SalesOrderHeader ~ 700 страниц. Это дает около 800 чтений, которые мы наблюдаем в трассе. Также важно помнить, что хэш-таблица была проверена 31465 раз - по разу на каждый ключ из таблицы SalesOrderHeader. Эти проверки, которые потребляют ресурсы, не относятся к логическому чтению и не представлены отдельными счетчиками в трассе SQL и в STATISTICS IO.
После создания индекса оптимизатор получил много больше вариантов для работы. Индекс на таблице Customer позволил выполнять эффективную фильтрацию поиска по обеим предикатам TerritoryID и CustomerType, что дает менее 100 строк, которые удовлетворяют фильтру. Оптимизатор решает (правильно), что выполнение оператора nested loops, извлекающего указатели на все соответствующие строки из таблицы Customer, и затем выполнение поиска закладок для извлечения столбцов OrderDate и OrderID для списка предложения select будет более эффективным. Теперь, поскольку каждая строка должна разыскиваться в индексе отдельно (index seek), к одним и тем же страницам необходимо получать доступ в памяти множество раз, каждый их которых вносит вклад в логические чтения. В результате общее число логических чтений значительно возросло.
В целом же производительность запроса существенно улучшилась в нескольких аспектах:
Этот пример ясно демонстрирует, что при оценке производительности запроса вы должны всегда рассматривать все аспекты его выполнения и помнить, что в некоторых случаях высокие метрики логических чтений могут вводить в заблуждение. Очистка буферного кэша и использование STATISTICS IO, напротив, обеспечат вас счетчиком физических чтений, которые во многих случаях более точно отражают требования к вводу/выводу анализируемого запроса.
И последняя мысль: хотя больше никаких рекомендаций по индексам не было предложено оптимизатором запросов, можете ли вы подумать о дополнительном индексе, чтобы еще больше улучшить производительность? Взгляните на прилагаемый демо-код, где я предложил дополнительный индекс, и его влиянии на производительность.
P.S. Попробуйте выполнить этот демо-код на SQL Server 2008, и вы будете удивлены...
Во-первых, нам следует понять, что действительно означает Read. Вот цитата из документации Майкрософт об архитектуре ввода/вывода, которая четко определяет логические и физические чтения: "Ввод/вывод экземпляра SQL Server делится на логический и физический ввод/вывод. Логические чтения имеет место всякий раз, когда движок базы данных запрашивает страницу из кэша буфера. Если страницы не оказывается в кэше, то выполняется физическое чтение для считывания страницы в кэш буфера. Если страница в данный момент уже находится в кэше, никаких физических чтений не выполняется, а буферный кэш просто использует страницу, уже находящуюся в памяти."
Важно помнить, что SQL Trace считает логические чтения, а не физические. Я полагаю, что это обусловлено тем фактом, что физические чтения являются общими для всех в данное время выполняемых пакетов на сервере и, следовательно, не обязательно привязаны к конкретному событию, несмотря на то, что они всегда вызываются конкретным событием. В зависимости от текущего содержимого кэша, одни и те же запросы или пакеты могут вызывать запуск физических чтений, а могут и не вызывать. Физические чтения действительно могут создавать проблемы с производительностью, поскольку задействуют подсистемы хранения, которые, к сожалению, до сих пор существенно более медленные по сравнению с логическими чтениями, которые выполняются в сверхбыстрых современных модулях памяти.
Метрики физических чтений доступны при использовании STATISTICS IO и из динамических представлений SQL Server.
Я думаю, что лучший способ объяснения - это примеры. Для демонстрации я использовал SQL Server 2005 SP3 и учебную базу AdventureWorks.
Поскольку мы не можем знать заранее содержимое кэша в данный момент времени при выполнении кода примера, я явным образом очистил кэш для моделирования худшего сценария с пустым кэшем.
Давайте возьмем следующий запрос и предположим, что я решаю задачу оптимизации производительности:
SELECT C.CustomerID, SOH.SalesOrderID, SOH.OrderDate
FROM Sales.Customer C
INNER JOIN
Sales.SalesOrderHeader SOH
ON SOH.CustomerID = C.CustomerID
WHERE C.TerritoryID = 1 AND C.CustomerType = N’S’
Вот метрики для этого запроса, записанные на моем ПК с помощью profiler:
Замечание: числа, приведенные ниже, показывают среднее значение нескольких запусков при непрогретом кэше.
CPU: ~40, Reads: ~840, Duration ~300ms.
Опция "missing indexes" (отсутствующие индексы) в Management Studio предлагает мне добавить следующий индекс:
/*
Missing Index Details from logical_reads.sql – AMI-PC.AdventureWorks (DBSOPHICAmi (52))
Query Processor оценивает улучшение стоимости запроса на 13.1751% при применении следующего индекса.
*/
/*
USE [AdventureWorks]
GO
CREATE NONCLUSTERED INDEX [< имя индекса >]
ON [Sales].[Customer] ([TerritoryID],[CustomerType])
INCLUDE ([CustomerID])
GO
*/
Будучи послушным DBA, я сразу создаю этот индекс и снова выполняю тот же запрос. Теперь я получил следующие метрики производительности в профайлере:
CPU: ~20, Reads: ~4000, Duration ~200ms.
Что произошло? Улучшило ли производительность добавление этого индекса или ухудшило её? Кажется, что данная информация противоречива. CPU и продолжительность (duration), видимо, существенно улучшились, но число логических чтений увеличилось почти в 5 раз!
Чтобы понять, что происходит под капотом, мы должны обратиться к плану выполнения.
Вот оригинальный план выполнения запроса до создания предложенного индекса:
А вот план, который оптимизатор выбрал после создания предложенного индекса:
В исходном плане оптимизатор для соединения таблиц выбрал физический оператор hash match. При использовании hash match доступ к каждому значению custimerID из каждой соединяемой таблицы необходим только один раз. Блоки, определяемые хэш-ключом, строились на основании значений custimerID из таблицы Custimer, а затем проверялись сканированием таблицы SalesOrderHeader. Каждую страницу требуется прочитать только раз, и возвращаются все значения. Вы можете проверить это подсчитав число страниц, используемое обеими таблицами - таблица Customer ~ 110 страниц, а таблица SalesOrderHeader ~ 700 страниц. Это дает около 800 чтений, которые мы наблюдаем в трассе. Также важно помнить, что хэш-таблица была проверена 31465 раз - по разу на каждый ключ из таблицы SalesOrderHeader. Эти проверки, которые потребляют ресурсы, не относятся к логическому чтению и не представлены отдельными счетчиками в трассе SQL и в STATISTICS IO.
После создания индекса оптимизатор получил много больше вариантов для работы. Индекс на таблице Customer позволил выполнять эффективную фильтрацию поиска по обеим предикатам TerritoryID и CustomerType, что дает менее 100 строк, которые удовлетворяют фильтру. Оптимизатор решает (правильно), что выполнение оператора nested loops, извлекающего указатели на все соответствующие строки из таблицы Customer, и затем выполнение поиска закладок для извлечения столбцов OrderDate и OrderID для списка предложения select будет более эффективным. Теперь, поскольку каждая строка должна разыскиваться в индексе отдельно (index seek), к одним и тем же страницам необходимо получать доступ в памяти множество раз, каждый их которых вносит вклад в логические чтения. В результате общее число логических чтений значительно возросло.
В целом же производительность запроса существенно улучшилась в нескольких аспектах:
- Только правильное подмножество строк извлекалось из таблицы Customer, потенциально сокращая физический ввод/вывод и уровень блокировок.
- Исключены хэш-функции, интенсивно использующие CPU.
- Сокращаются объемы памяти, как для данных, так и хэш-блоков.
Этот пример ясно демонстрирует, что при оценке производительности запроса вы должны всегда рассматривать все аспекты его выполнения и помнить, что в некоторых случаях высокие метрики логических чтений могут вводить в заблуждение. Очистка буферного кэша и использование STATISTICS IO, напротив, обеспечат вас счетчиком физических чтений, которые во многих случаях более точно отражают требования к вводу/выводу анализируемого запроса.
И последняя мысль: хотя больше никаких рекомендаций по индексам не было предложено оптимизатором запросов, можете ли вы подумать о дополнительном индексе, чтобы еще больше улучшить производительность? Взгляните на прилагаемый демо-код, где я предложил дополнительный индекс, и его влиянии на производительность.
P.S. Попробуйте выполнить этот демо-код на SQL Server 2008, и вы будете удивлены...
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой