
Когда использовать оператор SELECT...INTO
Пересказ статьи Phil Factor. When to use the SELECT…INTO statement
Мы можем использовать SELECT...INTO в SQL Server для создания новой таблицы из табличного источника данных. SQL Server использует атрибуты выражений в списке SELECT для определения структуры новой таблицы.
До версии SQL Server 2005 использование SELECT...INTO в рабочем коде считалось плохим стилем (code smell), влияющим на производительность, поскольку при этом запрашивались блокировки схемы, накладываемые на системные таблицы. В результате SQL Server оказывался недоступным в течение выполнения этого запроса, поскольку DDL-оператор включается в неявную транзакцию, которая может занимать продолжительное время пока данные вставляются в рамках того же оператора. Однако это поведение пофиксили в SQL Server 2005, когда изменилась модель блокировок.
Оператор SELECT...INTO стал популярным, поскольку это был более быстрый способ вставки данных по сравнению с использованием INSERT INTO ...SELECT. Это было обусловлено, главным образом, тем, что операция SELECT...INTO использовала, где это возможно, режим неполного протоколирования (bulk-logged). Хотя INSERT INTO теперь тоже может использовать этот режим, вы все еще можете увидеть лучшую производительность в SQL Server 2012 и 2014, поскольку SELECT...INTO может быть распараллелен в этих версиях, тогда как параллельное выполнение INSERT INTO появилось только в версии SQL Server 2016. Однако при SELECT...INTO вы по-прежнему должны определять все необходимые индексы, ограничения и т.д. на новой таблице.
Как правило, SELECT...INTO остается полезным инструментом для разработки, но теперь он не имеет очевидных преимуществ в производительности, и имеет сомнительное значение для рабочих баз данных. Этот оператор не является частью стандарта SQL. Обычно легче работать с таблицами, созданными оператором CREATE TABLE, поскольку при этом вы получаете преимущество в предварительном задании ограничений и типов данных, что дополнительно уменьшает вероятность несогласованности данных.
Рекомендуется избегать использования SELECT...INTO в рабочем коде.
Назначением SELECT...INTO в SQL Server было сохранение табличного источника в рамках процесса. Вот простой пример:
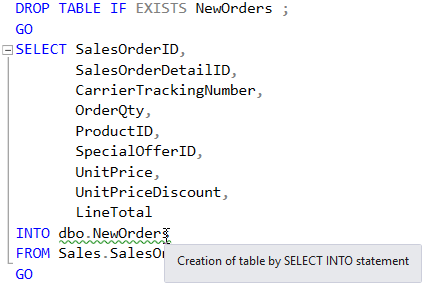
При этом табличным источником может быть не только обычная таблица, а также пользовательская функция, OpenQuery, OpenDataSource, предложение OPENXML, производная таблица, соединяемая таблица, пивот-таблица, удаленный источник данных, табличная переменная или переменная функция. С этими более экзотичными табличными источниками синтаксис SELECT...INTO становится более полезным.
Люди часто используют SELECT...INTO ошибочно полагая, что это быстрый способ сделать копию таблицы, а потому удивляются, что никакие индексы, ограничения, вычисляемые столбцы или триггеры, определенные для исходной таблицы, не были перенесены в новую. Они не могут быть специфицированы в операторе SELECT...INTO в принципе. Это также относится к допустимости NULL значений или сохранению вычисляемых столбцов. Все эти задачи должны выполняться уже после того, как созданная таблица будет заполнена данными, что неизбежно занимает время.
Хотя вы можете использовать функцию IDENTITY (тип данных, начальное значение, шаг) для установки поля счетчика и, когда источником является одна таблица, получить столбец в результирующей таблицы со свойством identity. Вероятно, этот факт и приводит разработчиков к мысли, что переносятся и другие атрибуты столбцов.
Помимо этого, данный оператор не может создавать секционированные (фрагментированные) таблицы, разреженные столбцы или другие атрибуты, наследуемые из исходной таблицы. Как это могло бы быть сделано, если табличный источник представляет собой запрос с множеством соединений или полученный из экзотических внешних источников данных?
Начиная с SQL 2012 SP1 CU10, SELECT...INTO может выполняться параллельно. Однако, начиная с SQL Server 2016, допускается параллельное выполнение обычного оператора INSERT INTO…SELECT с определенными ограничениями. Поэтому некоторое преимущество в производительности при использовании SELECT...INTO становится весьма призрачным. Процесс INSERT INTO также может быть ускорен, если он может использовать режим неполного протоколирования, а не режим полного восстановления (fully-recovered), вставкой пустой таблицы или таблицы без кластеризованного индекса, и установкой хинта TABLOCK для таблицы.
Ниже приводится сводка некоторых ограничений при использовании SELECT...INTO.
Существует некоторые заблуждения, связанные с проблемами, которые могут возникнуть при использовании SELECT...INTO с временными таблицами. SELECT...INTO приобрел отчасти несправедливую репутацию по этой причине, однако это является частью более общей проблемы блокировок в базе tempdb при высокой нагрузке создания и удаления небольшой временной таблицы. Когда SELECT...INTO принимался с энтузиазмом, он мог существенно увеличить этот тип активности. Эта проблема могла быть легко разрешена в SQL Server 2000
и выше включением флажка трассировки TF1118, который уже не требуется, начиная с версии SQL Server 2016.
Подводя итоги, можно сказать, что SELECT...INTO является хорошим способом создания табличного источника, временно сохраняемого как часть процесса, если вам не приходится
беспокоиться об ограничениях, индексах и специальных столбцах. Это не лучший способ копирования таблицы, поскольку только основные элементы схемы могут быть скопированы. За прошедшие годы возникали факторы, которые увеличивали или принижали привлекательность SELECT...INTO, но в целом следует избегать их применения где попало. Лучше создавать таблицу явно со всеми её характеристиками, чтобы гарантировать согласованность данных.
Оператор SELECT...INTO стал популярным, поскольку это был более быстрый способ вставки данных по сравнению с использованием INSERT INTO ...SELECT. Это было обусловлено, главным образом, тем, что операция SELECT...INTO использовала, где это возможно, режим неполного протоколирования (bulk-logged). Хотя INSERT INTO теперь тоже может использовать этот режим, вы все еще можете увидеть лучшую производительность в SQL Server 2012 и 2014, поскольку SELECT...INTO может быть распараллелен в этих версиях, тогда как параллельное выполнение INSERT INTO появилось только в версии SQL Server 2016. Однако при SELECT...INTO вы по-прежнему должны определять все необходимые индексы, ограничения и т.д. на новой таблице.
Как правило, SELECT...INTO остается полезным инструментом для разработки, но теперь он не имеет очевидных преимуществ в производительности, и имеет сомнительное значение для рабочих баз данных. Этот оператор не является частью стандарта SQL. Обычно легче работать с таблицами, созданными оператором CREATE TABLE, поскольку при этом вы получаете преимущество в предварительном задании ограничений и типов данных, что дополнительно уменьшает вероятность несогласованности данных.
Рекомендуется избегать использования SELECT...INTO в рабочем коде.
Создание таблиц с помощью оператора SELECT INTO
Назначением SELECT...INTO в SQL Server было сохранение табличного источника в рамках процесса. Вот простой пример:
При этом табличным источником может быть не только обычная таблица, а также пользовательская функция, OpenQuery, OpenDataSource, предложение OPENXML, производная таблица, соединяемая таблица, пивот-таблица, удаленный источник данных, табличная переменная или переменная функция. С этими более экзотичными табличными источниками синтаксис SELECT...INTO становится более полезным.
Является ли SELECT INTO частью стандарта ANSI?
ANSI стандарт поддерживает конструкцию SELECT...INTO во встроенном SQL; она называется единичным select и загружает то, что возвращает единственная строка, в переменные базового языка.
Люди часто используют SELECT...INTO ошибочно полагая, что это быстрый способ сделать копию таблицы, а потому удивляются, что никакие индексы, ограничения, вычисляемые столбцы или триггеры, определенные для исходной таблицы, не были перенесены в новую. Они не могут быть специфицированы в операторе SELECT...INTO в принципе. Это также относится к допустимости NULL значений или сохранению вычисляемых столбцов. Все эти задачи должны выполняться уже после того, как созданная таблица будет заполнена данными, что неизбежно занимает время.
Хотя вы можете использовать функцию IDENTITY (тип данных, начальное значение, шаг) для установки поля счетчика и, когда источником является одна таблица, получить столбец в результирующей таблицы со свойством identity. Вероятно, этот факт и приводит разработчиков к мысли, что переносятся и другие атрибуты столбцов.
Помимо этого, данный оператор не может создавать секционированные (фрагментированные) таблицы, разреженные столбцы или другие атрибуты, наследуемые из исходной таблицы. Как это могло бы быть сделано, если табличный источник представляет собой запрос с множеством соединений или полученный из экзотических внешних источников данных?
Начиная с SQL 2012 SP1 CU10, SELECT...INTO может выполняться параллельно. Однако, начиная с SQL Server 2016, допускается параллельное выполнение обычного оператора INSERT INTO…SELECT с определенными ограничениями. Поэтому некоторое преимущество в производительности при использовании SELECT...INTO становится весьма призрачным. Процесс INSERT INTO также может быть ускорен, если он может использовать режим неполного протоколирования, а не режим полного восстановления (fully-recovered), вставкой пустой таблицы или таблицы без кластеризованного индекса, и установкой хинта TABLOCK для таблицы.
Ниже приводится сводка некоторых ограничений при использовании SELECT...INTO.
- Свойство INDENTITY для столбца переносится, но если не:
Оператор SELECT содержит соединенные таблицы (при использовании JOIN или UNION), предложения GROUP BY или агрегатные функции. Если вы хотите избежать переноса свойства IDENTITY в новую таблицу, но хотите сохранить значения в столбце, можно добавить заведомо ложное условие соединения или UNION, который не добавит строк.
Столбец IDENTITY указывается в списке SELECT более одного раза.
Столбец IDENTITY входит в выражение.
Столбец IDENTITY берется из удаленного источника данных.
- Вы не SELECT...INTO в табличнозначный параметр или табличную переменную, хотя можете использовать их в предложении FROM.
- Даже если исходная таблица является секционированной, новая таблица создается в файловой группе по умолчанию. Однако в SQL Server 2017 возможно указать файловую группу, в которой создается новая таблица с помощью предложения ON.
- Вы можете задать предложение ORDER BY, но оно будет игнорироваться. Поэтому порядок IDENTITY_INSERT не гарантируется.
- Когда вычисляемый столбец включается в список SELECT, соответствующий столбец в новой таблице не является вычисляемым столбцом. Значения в новом столбце являются результатом вычисления при выполнении оператора SELECT...INTO.
- Как и в случае CREATE TABLE, если оператор SELECT...INTO содержится в явной транзакции, на соответствующие строки в задействованных системных таблицах накладывается блокировка без взаимного доступа, пока транзакция не завершится. В процессе выполнения транзакции другие процессы, которые используют эти системные таблицы, будут находиться в состоянии ожидания.
Существует некоторые заблуждения, связанные с проблемами, которые могут возникнуть при использовании SELECT...INTO с временными таблицами. SELECT...INTO приобрел отчасти несправедливую репутацию по этой причине, однако это является частью более общей проблемы блокировок в базе tempdb при высокой нагрузке создания и удаления небольшой временной таблицы. Когда SELECT...INTO принимался с энтузиазмом, он мог существенно увеличить этот тип активности. Эта проблема могла быть легко разрешена в SQL Server 2000
и выше включением флажка трассировки TF1118, который уже не требуется, начиная с версии SQL Server 2016.
Заключение
Подводя итоги, можно сказать, что SELECT...INTO является хорошим способом создания табличного источника, временно сохраняемого как часть процесса, если вам не приходится
беспокоиться об ограничениях, индексах и специальных столбцах. Это не лучший способ копирования таблицы, поскольку только основные элементы схемы могут быть скопированы. За прошедшие годы возникали факторы, которые увеличивали или принижали привлекательность SELECT...INTO, но в целом следует избегать их применения где попало. Лучше создавать таблицу явно со всеми её характеристиками, чтобы гарантировать согласованность данных.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой