
Когда использовать CHAR, VARCHAR или VARCHAR(MAX)
Пересказ статьи Greg Larsen. When to use CHAR, VARCHAR, or VARCHAR(MAX)
В каждой базе данных имеются различные виды данных, которые нужно хранить. Некоторые данные строго числовые, в то время как другие данные состоят только из букв или комбинации букв, чисел и даже специальных символов. Даже при простом хранении данных в памяти или на диске требуется, чтобы каждая часть данных имела тип. Выбор правильного типа зависит от характеристик сохраняемых данных. В этой статье объясняется разница между CHAR, VARCHAR и VARCHAR(MAX).
При выборе типа данных столбца необходимо подумать о характеристиках данных, чтобы назначить правильный тип данных. Будет ли каждое значение иметь одну и ту же длину, или размер будет сильно различаться от значения к значению? Как часто будут меняться данные? Будет ли длина столбца меняться со временем? Могут быть и другие факторы, подобные эффективному использованию пространства и производительности, которые могут привести вас к принятию того или иного типа данных.
Типы данных CHAR, VARCHAR и VARCHAR(MAX) могут хранить символьные данные. В этой статье будут обсуждаться и сравниваться эти три различных типа символьных данных. Приведенная информация призвана помочь вам выбрать подходящий среди этих трех типов данных.
Тип данных CHAR является типом данных фиксированной длины. Он может хранить буквы, числа и специальные символы в строках размером до 8000 байт. Тип данных CHAR наилучшим образом используется для хранения данных, которые имеют сопоставимую длину. Например, двухсимвольные коды штатов США, односимвольные коды половой принадлежности, номера телефонов, почтовые коды и т.п. Столбец CHAR является не лучшим выбором для хранения данных, у которых существенно варьируется длина. Столбцы, хранящие данные типа адресов или мемо-полей не подходят для столбцов с типом данных CHAR.
Это не означает, что столбец CHAR не может содержать значения, которые варьируются по размеру. Когда в столбец CHAR заносятся строки, которые короче, чем длина столбца, справа будут добавляться пробелы. Число этих пробелов определяется разностью между размером столбца и длиной сохраняемых символов. Поскольку столбцы CHAR при необходимости полностью добиваются пробелами, каждый столбец занимает одно и то же пространство на диске или в памяти. Концевые пробелы также играют роль при поиске в столбцах типа CHAR. Подробнее об этом несколько позже.
Столбцы VARCHAR, как подразумевает название, хранят данные переменной длины. Они могут хранить буквы, числа и специальные символы, как и столбец CHAR, и поддерживают строки размером до 8000 байт. Столбец переменной длины занимает только то место, которое требуется для хранения строки символов, и не дополняются никакими пробелами. По этой причине столбцы VARCHAR отлично подходят для хранения строк, которые сильно варьируются по размеру.
Для поддержки столбцов переменной длины необходимо, помимо самих данных, хранить их длину. Поскольку длина необходима для вычислений и используется ядром базы данных при чтении и сохранении столбцов переменной длины, считается, что они несколько менее производительны по сравнению со столбцами CHAR. Однако, если учесть, что они используют только то пространство, которое им необходимо, экономия места на диске сама по себе может компенсировать потери производительности при использовании типа VARCHAR.
Фундаментально отличие CHAR от VARCHAR состоит в том, что тип данных CHAR имеет фиксированную длину, в то время как тип данных VARCHAR поддерживает столбцы данных переменной длины. Но он и похожи. Оба предназначены для хранения алфавитно-цифровых данных. Для лучшего понимания разницы между этими двумя типами, посмотрите таблицу 1, где сделан обзор их подобия и отличий.
Таблица 1: сравнение типов CHAR и VARCHAR

"N" означает не максимальное число символов, которое может храниться в столбце CHAR или VARCHAR, а максимальное число байтов, которое займет тип данных. SQL Server имеет различные коллации для хранения символов. Некоторые наборы символов, подобные Latin, хранят каждый символ и одном байте пространства. В то время как другие наборы символов, например, японский, требуют нескольких байтов на символ.
Столбцы CHAR и VARCHAR могут хранить до 8000 байтов. Если используется односимвольный набор, то столбец CHAR или VARCHAR может хранить до 8000 символов. Если используется мультибайтовая коллация, максимальное число символов, которое может хранить CHAR или VARCHAR, будет меньше 8000. Обсуждение коллации выходит за рамки этой статьи, но если вы хотите больше узнать об однобайтовом и многобайтовыми наборами символов, обратитесь к документации.
Если столбец определен как CHAR(N) или VARCHAR(N), "N" представляет число байтов, которое может храниться в столбце. При заполнении столбца CHAR(N) или VARCHAR(N) символьной строкой может возникнуть подобная ошибка усечения, показанная на рисунке 1.
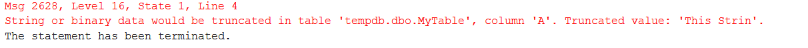
Рис.1 Ошибка усечения
Эта ошибка возникает при попытке сохранить строку, размер которой превышает максимальную длину столбца
CHAR или VARCHAR. Когда возникает подобная ошибка усечения, код TSQL прерывается, и последующий код не выполняется. Это можно продемонстрировать следующим кодом в листинге 1.
Листинг 1: код, приводящий к ошибке усечения
Код в листинге 1 вызывает ошибку, показанную на рисунке 1, при выполнении оператора INSERT. Оператор SELECT, следующий за оператором INSERT, не был выполнен из-за ошибки усечения. Ошибка усечения и прерывание выполнения скрипта могут давать вам желаемую функциональность, но иногда вы не хотите получать ошибку усечения, прерывающую ваш код.
Предположим, что необходимо перенести данные из старой системы в новую. В старой системе есть таблица MyOldData, которая содержит данные, созданные с помощью скрипта в листинге 2.
Листинг 2: таблица в старой системе
Планируется перенести данные из таблицы MyOldData в таблицу MyNewTable, которая имеет меньший размер столбца ItemDesc. Код в листинге 3 используется для создания новой таблицы и переноса данных.
Листинг 3: перенос данных в новую таблицу
При выполнении кода в листинге 3 вы получите ошибку усечения, подобную ошибке на рис.1, и никакие данные перенесены не будут.
Для успешного переноса данных необходимо определиться с тем, что делать с усечением, чтобы гарантировать перенос всех строк. Одним из методов является усечение описания элемента (ItemDesc) с помощью функции SUBSTRING при выполнении кода в листинге 4.
Листинг 4: Устранение ошибки усечения с помощью SUBSTRING
При выполнении кода в листинге 4 все записи переносятся. При этом ItemDesc превышающая 40 будет усекаться с помощью функции SUBSTRING, но есть и другой способ.
Если вы хотите избежать ошибки усечения без написания специального кода усечения столбцов, длина которых слишком велика, можно выключить параметр ANSI_WARNINGS, как показано в листнге 5.
Листинг 5: устранение ошибки усечения при выключении ANSI_WARNINGS.
При выключении параметра ANSI_WARNINGS ядро SQL Server не следует стандарту ISO для некоторых состояний ошибок, одним из которых является состояние ошибки усечения. При отключении этого параметра SQL Server автоматически усекает исходный столбец для соответствия его целевым столбцам без возвращения ошибки. Следует осторожно использовать выключение параметра ANSI_WARNINGS, поскольку при этом могут также остаться незамеченными другие ошибки. Поэтому изменение параметра ANSI_WARNINGS следует использовать ситуативно.
Тип данных VARCHAR(MAX) подобен типу данных VARCHAR в том, что он поддерживает символьные данные переменной длины. VARCHAR(MAX) отличается от VARCHAR тем, что он поддерживает строки символов длиной вплоть до 2 Гб (2,147,483,647 байтов). Вам следует рассмотреть использование VARCHAR(MAX) только тогда, когда каждая строка, сохраняемая в этом типе данных существенно варьируется по длине, и значение может превышать 8000 байтов.
Вы можете спросить себя, почему бы не использовать VARCHAR(MAX) везде вместо использования VARCHAR(N)? Вы можете, но имеется несколько причин, почему этого делать не стоит:
столбцы VARCHAR(MAX) не могут быть включены в ключевые столбцы индекса;
столбцы VARCHAR(MAX) не позволяют ограничить длину столбца;
для хранения больших строк столбцы VARCHAR(MAX) используют единицы распределения LOB_DATA. Хранилище LOB_DATA существенней медленней, чем использование единиц распределения хранилища IN_ROW_DATA;
хранилище LOB_DATA не поддерживает сжатие страниц и строк.
Можно подумать, что столбцы VARCHAR(MAX) будут устранять ошибку усечения, которую мы наблюдали ранее. Это частично верно при условии, что вы не пытаетесь сохранить строку со значением длинее, чем 2,147,483,647 байтов. Если вы попытаетесь записать строку, размер которой превышает 2,147,483,647 байтов, вы получите ошибку, показанную на рисунке 2.

Рис.2: ошибка, когда размер строки превышает 2 Гб
Столбцы VARCHAR(MAX) следует использовать только тогда, когда вы знаете, что некоторые сохраняемые данные будут ожидаемо превосходить 8000-байтовый предел для столбца VARCHAR(N), и все данные будут короче предела 2 Гб для типа данных VARCHAR(MAX).
Когда столбец CHAR не полностью заполнен строкой символов, неиспользованные символы замещаются пробелами. Когда столбец CHAR дополняется пробелами, это может вызвать некоторые проблемы при конкатенации столбцов CHAR. Для лучшего понимания рассматрим несколько примеров, которые используют таблицу, созданную в листинге 6.
Листинг 6: таблица для примеров Sample
Таблица Sample, созданная в листинге 6, содержит 4 столбца. Первые два определены как CHAR(20), а вторые два - VARCHAR(20). Эти столбцы будут использоваться для хранения моего имени и фамилии.
Для демонстрации проблем конкатенации, связанной с дополняемыми столбцами CHAR, выполните код в листинге 7.
Листинг 7: демонстрация проблемы конкатенации
Результат выполнения кода в листнге 7

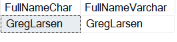
Здесь столбец FirstNameCHAR содержит несколько пробелов между именем и фамилией. Эти пробелы являются пробелами, дополненными в столбце FirstNameCHAR при сохранении имени в столбце типа CHAR. Столбец FullNameVARCHAR не содержит пробелов между именем и фамилией. Если длина записываемого значения меньше длины столбца VARCHAR, пробелы не добавляются.
При конкатенации столбцов CHAR вам может понадобиться удалить концевые пробелы, чтобы получить желаемый результат. Вы можете использовать функцию RTRIM для удаления пробелов, как показано в листинге 8.
Листинг 8: удаление концевых пробелов с помощью функции RTRIM
Результат выполнения скрипта показан на рисунке ниже.
Пр использовани функции RTRIM все дополнительные пробелы, добавленные к столбцам FirstNameCHAR и LastNameCHAR удаляются перед выполнением конкатенации.
Поскольку столбцы CHAR могут дополняться пробелами, поиск пробела может стать проблемой.
Предположим, что имеется таблица, содержащая фразы, подобные создаваемым в листинге 9.
Листинг 9: создание таблицы Phrase
Некоторые фразы в таблице Phrase состоят из одного слова, а другие содержать два. Для поиска в таблице Phrase всех фраз, которые содержат два слова, воспользуемся кодом в листинге 10.
Листинг 10: попытка найти фразы из двух слов
Результат выполнения скрипта показан ниже.

Почему были возвращены все фразы из таблицы Phrase, хотя имеется только две строки, состоящие из двух слов? Поисковая строка % % также находит пробелы, которые были добавлены в конце значения столбца. И опять, функция RTRIM может использоваться, чтобы гарантировать, что дополненные пробелы не будут включены в результаты поиска при выполнении кода в листинге 11.
Листинг 11: удаление концевых пробелов
Вы можете сами проверить, что будут возвращены только фразы из двух слов.
Количество работы, которое выполняет движок базы данных при сохранении и извлечения столбцов VARCHAR, больше, чем для столбца CHAR. При каждом извлечении информации из столбца VARCHAR движок базы данных должен использовать информацию о длине, хранящуюся вместе с данными в столбце VARCHAR.
Использование информации о длине вызывает лишние циклы работы ЦП. В то же время фиксированная длина столбца CHAR позволяет SQL Server более легко выполнять навигацию по записям столбца CHAR, благодаря его фиксированной длине.
При работе со столбцами CHAR и VARCHAR проблемой может стать дисковое пространство. Поскольку столбец типа CHAR имеет фиксированную длину, он всегда будут занимать одинаковое пространство диска. Столбцы VARCHAR изменяются по размеру, поэтому необходимое пространство основывается на размере хранимых строк, а не на размере в определении столбца. Когда подавляющее большинство значений, хранимых в столбце CHAR, меньше заданного размера, то использование столбца VARCHAR может использовать меньше дискового пространства. Когда используется меньше дискового пространства, требуется меньше операций ввода/вывода при работе с данными столбца, что означает улучшение производительности. Эти два соображения определяют выбор между CHAR и VARCHAR.
Столбцы CHAR фиксированы по размеру, в то время как столбцы VARCHAR и VARCHAR(MAX) поддерживают данные переменной длины. Столбцы CHAR следует использовать для столбцов, длина которых меняется незначительно. Строковые значения, которые значительно варьируются по длине и не превышают 8000 байтов, следует хранить в столбце VARCHAR. Если у вас огромные строки (свыше 8000 байтов), то следует использовать VARCHAR(MAX). При использовании столбцов VARCHAR вместе с данными хранится информация о длине строки. Вычисление и хранение значения длины для столбца VARCHAR означает, что SQL Server должен выполнить немного больше работы для записи и извлечения столбцов VARCHAR по сравнению типом данных CHAR.
Когда вам предстоит решить, должен ли новый столбец иметь тип CHAR, VARCHAR или VARCHAR(MAX), задайте себе несколько вопросов, чтобы выбрать подходящий тип. Все ли сохраняемые строковые значения близки по размеру? Если да, то следует выбрать CHAR. Если сохраняемые строки значительно варьируются по размеру, и их размер не превышает 8000, используйте VARCHAR. В противном случае следует использовать VARCHAR(MAX).
Типы данных CHAR, VARCHAR и VARCHAR(MAX) могут хранить символьные данные. В этой статье будут обсуждаться и сравниваться эти три различных типа символьных данных. Приведенная информация призвана помочь вам выбрать подходящий среди этих трех типов данных.
Символьный тип данных фиксированной длины CHAR
Тип данных CHAR является типом данных фиксированной длины. Он может хранить буквы, числа и специальные символы в строках размером до 8000 байт. Тип данных CHAR наилучшим образом используется для хранения данных, которые имеют сопоставимую длину. Например, двухсимвольные коды штатов США, односимвольные коды половой принадлежности, номера телефонов, почтовые коды и т.п. Столбец CHAR является не лучшим выбором для хранения данных, у которых существенно варьируется длина. Столбцы, хранящие данные типа адресов или мемо-полей не подходят для столбцов с типом данных CHAR.
Это не означает, что столбец CHAR не может содержать значения, которые варьируются по размеру. Когда в столбец CHAR заносятся строки, которые короче, чем длина столбца, справа будут добавляться пробелы. Число этих пробелов определяется разностью между размером столбца и длиной сохраняемых символов. Поскольку столбцы CHAR при необходимости полностью добиваются пробелами, каждый столбец занимает одно и то же пространство на диске или в памяти. Концевые пробелы также играют роль при поиске в столбцах типа CHAR. Подробнее об этом несколько позже.
Символьный тип данных переменной длины VARCHAR
Столбцы VARCHAR, как подразумевает название, хранят данные переменной длины. Они могут хранить буквы, числа и специальные символы, как и столбец CHAR, и поддерживают строки размером до 8000 байт. Столбец переменной длины занимает только то место, которое требуется для хранения строки символов, и не дополняются никакими пробелами. По этой причине столбцы VARCHAR отлично подходят для хранения строк, которые сильно варьируются по размеру.
Для поддержки столбцов переменной длины необходимо, помимо самих данных, хранить их длину. Поскольку длина необходима для вычислений и используется ядром базы данных при чтении и сохранении столбцов переменной длины, считается, что они несколько менее производительны по сравнению со столбцами CHAR. Однако, если учесть, что они используют только то пространство, которое им необходимо, экономия места на диске сама по себе может компенсировать потери производительности при использовании типа VARCHAR.
Различия типов данных CHAR и VARCHAR
Фундаментально отличие CHAR от VARCHAR состоит в том, что тип данных CHAR имеет фиксированную длину, в то время как тип данных VARCHAR поддерживает столбцы данных переменной длины. Но он и похожи. Оба предназначены для хранения алфавитно-цифровых данных. Для лучшего понимания разницы между этими двумя типами, посмотрите таблицу 1, где сделан обзор их подобия и отличий.
Таблица 1: сравнение типов CHAR и VARCHAR
Что означает "N" в CHAR(N) или VARCHAR(N)
"N" означает не максимальное число символов, которое может храниться в столбце CHAR или VARCHAR, а максимальное число байтов, которое займет тип данных. SQL Server имеет различные коллации для хранения символов. Некоторые наборы символов, подобные Latin, хранят каждый символ и одном байте пространства. В то время как другие наборы символов, например, японский, требуют нескольких байтов на символ.
Столбцы CHAR и VARCHAR могут хранить до 8000 байтов. Если используется односимвольный набор, то столбец CHAR или VARCHAR может хранить до 8000 символов. Если используется мультибайтовая коллация, максимальное число символов, которое может хранить CHAR или VARCHAR, будет меньше 8000. Обсуждение коллации выходит за рамки этой статьи, но если вы хотите больше узнать об однобайтовом и многобайтовыми наборами символов, обратитесь к документации.
Ошибка усечения
Если столбец определен как CHAR(N) или VARCHAR(N), "N" представляет число байтов, которое может храниться в столбце. При заполнении столбца CHAR(N) или VARCHAR(N) символьной строкой может возникнуть подобная ошибка усечения, показанная на рисунке 1.
Рис.1 Ошибка усечения
Эта ошибка возникает при попытке сохранить строку, размер которой превышает максимальную длину столбца
CHAR или VARCHAR. Когда возникает подобная ошибка усечения, код TSQL прерывается, и последующий код не выполняется. Это можно продемонстрировать следующим кодом в листинге 1.
Листинг 1: код, приводящий к ошибке усечения
USE tempdb;
GO
CREATE TABLE MyTable (A VARCHAR(10));
INSERT INTO MyTable VALUES ('This String');
-- Продолжение
SELECT COUNT(*) FROM MyTable;
GOКод в листинге 1 вызывает ошибку, показанную на рисунке 1, при выполнении оператора INSERT. Оператор SELECT, следующий за оператором INSERT, не был выполнен из-за ошибки усечения. Ошибка усечения и прерывание выполнения скрипта могут давать вам желаемую функциональность, но иногда вы не хотите получать ошибку усечения, прерывающую ваш код.
Предположим, что необходимо перенести данные из старой системы в новую. В старой системе есть таблица MyOldData, которая содержит данные, созданные с помощью скрипта в листинге 2.
Листинг 2: таблица в старой системе
USE tempdb;
GO
CREATE TABLE MyOldData (Name VARCHAR(20), ItemDesc VARCHAR(45));
INSERT INTO MyOldData
VALUES ('Widget', 'This item does everything you would ever want'),
('Thing A Ma Jig', 'A thing that dances the jig');
GOПланируется перенести данные из таблицы MyOldData в таблицу MyNewTable, которая имеет меньший размер столбца ItemDesc. Код в листинге 3 используется для создания новой таблицы и переноса данных.
Листинг 3: перенос данных в новую таблицу
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
INSERT INTO MyNewData SELECT * FROM MyOldData;
SELECT * FROM MyNewData;
GO
При выполнении кода в листинге 3 вы получите ошибку усечения, подобную ошибке на рис.1, и никакие данные перенесены не будут.
Для успешного переноса данных необходимо определиться с тем, что делать с усечением, чтобы гарантировать перенос всех строк. Одним из методов является усечение описания элемента (ItemDesc) с помощью функции SUBSTRING при выполнении кода в листинге 4.
Листинг 4: Устранение ошибки усечения с помощью SUBSTRING
DROP Table MyNewData
GO
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
INSERT INTO MyNewData SELECT Name, substring(ItemDesc,1,40)
FROM MyOldData;
SELECT * FROM MyNewData;
GOПри выполнении кода в листинге 4 все записи переносятся. При этом ItemDesc превышающая 40 будет усекаться с помощью функции SUBSTRING, но есть и другой способ.
Если вы хотите избежать ошибки усечения без написания специального кода усечения столбцов, длина которых слишком велика, можно выключить параметр ANSI_WARNINGS, как показано в листнге 5.
Листинг 5: устранение ошибки усечения при выключении ANSI_WARNINGS.
DROP Table MyNewData
GO
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
SET ANSI_WARNINGS OFF;
INSERT INTO MyNewData SELECT * FROM MyOldData;
SET ANSI_WARNINGS ON;
SELECT * FROM MyNewData;
GOПри выключении параметра ANSI_WARNINGS ядро SQL Server не следует стандарту ISO для некоторых состояний ошибок, одним из которых является состояние ошибки усечения. При отключении этого параметра SQL Server автоматически усекает исходный столбец для соответствия его целевым столбцам без возвращения ошибки. Следует осторожно использовать выключение параметра ANSI_WARNINGS, поскольку при этом могут также остаться незамеченными другие ошибки. Поэтому изменение параметра ANSI_WARNINGS следует использовать ситуативно.
VARCHAR(MAX)
Тип данных VARCHAR(MAX) подобен типу данных VARCHAR в том, что он поддерживает символьные данные переменной длины. VARCHAR(MAX) отличается от VARCHAR тем, что он поддерживает строки символов длиной вплоть до 2 Гб (2,147,483,647 байтов). Вам следует рассмотреть использование VARCHAR(MAX) только тогда, когда каждая строка, сохраняемая в этом типе данных существенно варьируется по длине, и значение может превышать 8000 байтов.
Вы можете спросить себя, почему бы не использовать VARCHAR(MAX) везде вместо использования VARCHAR(N)? Вы можете, но имеется несколько причин, почему этого делать не стоит:
столбцы VARCHAR(MAX) не могут быть включены в ключевые столбцы индекса;
столбцы VARCHAR(MAX) не позволяют ограничить длину столбца;
для хранения больших строк столбцы VARCHAR(MAX) используют единицы распределения LOB_DATA. Хранилище LOB_DATA существенней медленней, чем использование единиц распределения хранилища IN_ROW_DATA;
хранилище LOB_DATA не поддерживает сжатие страниц и строк.
Можно подумать, что столбцы VARCHAR(MAX) будут устранять ошибку усечения, которую мы наблюдали ранее. Это частично верно при условии, что вы не пытаетесь сохранить строку со значением длинее, чем 2,147,483,647 байтов. Если вы попытаетесь записать строку, размер которой превышает 2,147,483,647 байтов, вы получите ошибку, показанную на рисунке 2.
Рис.2: ошибка, когда размер строки превышает 2 Гб
Столбцы VARCHAR(MAX) следует использовать только тогда, когда вы знаете, что некоторые сохраняемые данные будут ожидаемо превосходить 8000-байтовый предел для столбца VARCHAR(N), и все данные будут короче предела 2 Гб для типа данных VARCHAR(MAX).
Проблемы конкатенации со столбцами CHAR
Когда столбец CHAR не полностью заполнен строкой символов, неиспользованные символы замещаются пробелами. Когда столбец CHAR дополняется пробелами, это может вызвать некоторые проблемы при конкатенации столбцов CHAR. Для лучшего понимания рассматрим несколько примеров, которые используют таблицу, созданную в листинге 6.
Листинг 6: таблица для примеров Sample
USE tempdb;
GO
CREATE TABLE Sample (
ID int identity,
FirstNameChar CHAR(20),
LastNameChar CHAR(20),
FirstNameVarChar VARCHAR(20),
LastNameVarChar VARCHAR(20));
INSERT INTO Sample VALUES ('Greg', 'Larsen', 'Greg', 'Larsen');Таблица Sample, созданная в листинге 6, содержит 4 столбца. Первые два определены как CHAR(20), а вторые два - VARCHAR(20). Эти столбцы будут использоваться для хранения моего имени и фамилии.
Для демонстрации проблем конкатенации, связанной с дополняемыми столбцами CHAR, выполните код в листинге 7.
Листинг 7: демонстрация проблемы конкатенации
SELECT FirstNameChar + LastNameChar AS FullNameChar,
FirstNameVarChar + LastNameVarChar AS FullNameVarChar FROM Sample;Результат выполнения кода в листнге 7
Здесь столбец FirstNameCHAR содержит несколько пробелов между именем и фамилией. Эти пробелы являются пробелами, дополненными в столбце FirstNameCHAR при сохранении имени в столбце типа CHAR. Столбец FullNameVARCHAR не содержит пробелов между именем и фамилией. Если длина записываемого значения меньше длины столбца VARCHAR, пробелы не добавляются.
При конкатенации столбцов CHAR вам может понадобиться удалить концевые пробелы, чтобы получить желаемый результат. Вы можете использовать функцию RTRIM для удаления пробелов, как показано в листинге 8.
Листинг 8: удаление концевых пробелов с помощью функции RTRIM
SELECT RTRIM(FirstNameChar) + RTRIM(LastNameChar) AS FullNameChar,
FirstNameVarChar + LastNameVarChar AS FullNameVarchar
FROM Sample;Результат выполнения скрипта показан на рисунке ниже.
Пр использовани функции RTRIM все дополнительные пробелы, добавленные к столбцам FirstNameCHAR и LastNameCHAR удаляются перед выполнением конкатенации.
Проблемы с поиском пробелов в столбцах CHAR
Поскольку столбцы CHAR могут дополняться пробелами, поиск пробела может стать проблемой.
Предположим, что имеется таблица, содержащая фразы, подобные создаваемым в листинге 9.
Листинг 9: создание таблицы Phrase
USE tempdb;
GO
CREATE TABLE Phrase (PhraseChar CHAR(100));
INSERT INTO Phrase VALUES ('Worry Less'),
('Oops'),
('Think Twice'),
('Smile');Некоторые фразы в таблице Phrase состоят из одного слова, а другие содержать два. Для поиска в таблице Phrase всех фраз, которые содержат два слова, воспользуемся кодом в листинге 10.
Листинг 10: попытка найти фразы из двух слов
SELECT PhraseChar FROM Phrase WHERE PhraseChar like '% %';Результат выполнения скрипта показан ниже.
Почему были возвращены все фразы из таблицы Phrase, хотя имеется только две строки, состоящие из двух слов? Поисковая строка % % также находит пробелы, которые были добавлены в конце значения столбца. И опять, функция RTRIM может использоваться, чтобы гарантировать, что дополненные пробелы не будут включены в результаты поиска при выполнении кода в листинге 11.
Листинг 11: удаление концевых пробелов
SELECT PhraseChar FROM Phrase
WHERE RTRIM(PhraseChar) like '% %';Вы можете сами проверить, что будут возвращены только фразы из двух слов.
Сравнение производительности VARCHAR и CHAR
Количество работы, которое выполняет движок базы данных при сохранении и извлечения столбцов VARCHAR, больше, чем для столбца CHAR. При каждом извлечении информации из столбца VARCHAR движок базы данных должен использовать информацию о длине, хранящуюся вместе с данными в столбце VARCHAR.
Использование информации о длине вызывает лишние циклы работы ЦП. В то же время фиксированная длина столбца CHAR позволяет SQL Server более легко выполнять навигацию по записям столбца CHAR, благодаря его фиксированной длине.
При работе со столбцами CHAR и VARCHAR проблемой может стать дисковое пространство. Поскольку столбец типа CHAR имеет фиксированную длину, он всегда будут занимать одинаковое пространство диска. Столбцы VARCHAR изменяются по размеру, поэтому необходимое пространство основывается на размере хранимых строк, а не на размере в определении столбца. Когда подавляющее большинство значений, хранимых в столбце CHAR, меньше заданного размера, то использование столбца VARCHAR может использовать меньше дискового пространства. Когда используется меньше дискового пространства, требуется меньше операций ввода/вывода при работе с данными столбца, что означает улучшение производительности. Эти два соображения определяют выбор между CHAR и VARCHAR.
CHAR, VARCHAR и VARCHAR(MAX)
Столбцы CHAR фиксированы по размеру, в то время как столбцы VARCHAR и VARCHAR(MAX) поддерживают данные переменной длины. Столбцы CHAR следует использовать для столбцов, длина которых меняется незначительно. Строковые значения, которые значительно варьируются по длине и не превышают 8000 байтов, следует хранить в столбце VARCHAR. Если у вас огромные строки (свыше 8000 байтов), то следует использовать VARCHAR(MAX). При использовании столбцов VARCHAR вместе с данными хранится информация о длине строки. Вычисление и хранение значения длины для столбца VARCHAR означает, что SQL Server должен выполнить немного больше работы для записи и извлечения столбцов VARCHAR по сравнению типом данных CHAR.
Когда вам предстоит решить, должен ли новый столбец иметь тип CHAR, VARCHAR или VARCHAR(MAX), задайте себе несколько вопросов, чтобы выбрать подходящий тип. Все ли сохраняемые строковые значения близки по размеру? Если да, то следует выбрать CHAR. Если сохраняемые строки значительно варьируются по размеру, и их размер не превышает 8000, используйте VARCHAR. В противном случае следует использовать VARCHAR(MAX).
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой