
Какая разница между PERCENT_RANK и CUME_DIST?
Пересказ статьи Kathi Kellenberger. What’s the Difference Between PERCENT_RANK and CUME_DIST?
Помните стандартные тесты, которые вы сдавали в школе? Они сравнивали ваше выполнение с другими, ранжировали, но не давали фактического процента правильных ответов.
Microsoft реализовал несколько новых оконных функций в SQL Server 2012, в том числе две, которые сравнивают элементы в списке, аналогично результатам стандартных тестов. Этими двумя функциями являются PERCENT_RANK и CUME_DIST. Они подобны функции RANK, но возвращают процент в группе, а не просто ранговый номер.
Для списка оценок PERCENT_RANK возвращает процент значений, меньших чем текущая оценка. CUME_DIST, которая означает накопительное распределение, возвращает фактическое положение оценки. Если имеется 100 оценок и PERCENT_RANK составляет 90, это означает, что данный результат выше чем 90 оценок. Если CUME_DIST равен 90, это означает, что оценка является 90-той в списке.
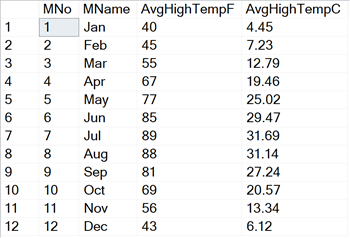
Вот пример, использующий среднюю месячную наибольшую температуру для St. Louis, MO. Сначала создадим таблицу, содержащую строку для каждого месяца и температуры.
Теперь посмотрим, как ранжируется температура с использованием RANK, PERCENT_RANK и CUME_DIST.
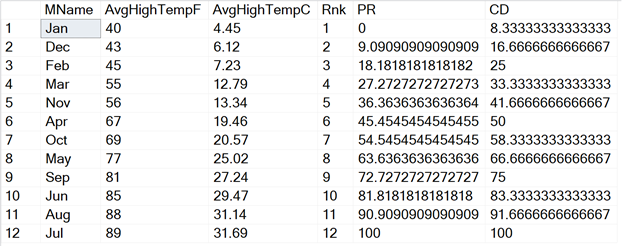
Январь является самым холодным месяцем. Нет месяца, холоднее чем январь, поэтому его температура имеет PERCENT_RANK = 0. CUME_DIST для нее равен 8.33% (значения умножались на 100, чтобы вернуть проценты), поскольку температура составляет 8,33% (1/12) в списке.
Июль - самый жаркий месяц. И PERCENT_RANK, и CUME_DIST возвращают 100, поскольку его температура жарче, чем во все другие месяцы, и находится на вершине списка. Когда вы используете эти функции, вы всегда видите 1 или 100%, возвращаемые для самого высокого элемента списка.
Если вам интересно, как вычисляются эти значения, то, как уже говорилось, они основываются на ранге. Вот формулы:
Чтобы увидеть, как это работает, выполните запрос:
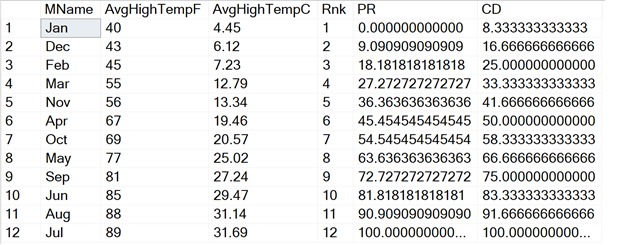
За исключением нулей после десятичной точки, результаты выглядят одинаково. Имеется одна проблема при использовании этих формул. Если разбиение содержит только один элемент, то вы получите ошибку деления на нуль при использовании формулы PERCENT_RANK.
А что насчет производительности? Есть ли разница в производительности между использованием вычислений и более простых функций? Моя интуиция говорит, что разницы быть не должно, поскольку функции основаны на вычислениях. Но это не тот случай. Формулы несколько более эффективны, чем функции, для большого числа строк. Чтобы увидеть это, выполните следующий код для создания большой временной таблицы в AdventureWorks.
Чтобы увидеть разницу, используйте STATISTICS IO. Выполните эти запросы и посмотрите вкладку Messages (сообщения).

Запрос, использующий функцию CUME_DIST имеет более 2 миллионов логических чтений из worktable (рабочей таблицы), в то время как функция - 700 тысяч. В каждом случае слишком много логических чтений! К счастью, когда эти функции используются в реальной задаче, то применяются к значительно меньшему числу строк, поэтому производительность не столь важна.
В SQL Server эта проблема решена, начиная с CTP3, самой последней доступной версии на момент написания статьи. В этой версии новый метод, называемый Batch Mode on Rowstore (пакетный режим на построчном хранении), используется, когда можно получить большую разницу в производительности. Ядро определяет, когда его использовать, но в своих прежних экспериментах я обнаружила его при около 130 тысячах строк, когда оконный агрегат является частью запроса.
Если переключить уровень совместимости на SQL Server 2019 (150) и снова выполнить эти запросы, число логических чтений для рабочих таблиц уменьшается до нуля.

Конечно, вам нужен SQL Server 2019, чтобы увидеть этот прирост производительности.
Для многих проектов любая функция может работать одинаково хорошо. Если это влияет на результаты, вы теперь знаете разницу между ними и сможете выбрать ту, которая лучшим образом подойдет для вашей ситуации.
Вот пример, использующий среднюю месячную наибольшую температуру для St. Louis, MO. Сначала создадим таблицу, содержащую строку для каждого месяца и температуры.
CREATE TABLE #MonthlyTempsStl(MNo Int,
MName varchar(15),
AvgHighTempF INT,
AvgHighTempC DECIMAL(4,2))
INSERT INTO #MonthlyTempsStl(Mno, MName, AvgHighTempF)
VALUES(1,'Jan',40),(2,'Feb',45),(3,'Mar',55),
(4,'Apr',67),(5,'May',77),(6,'Jun',85),
(7,'Jul',89),(8,'Aug',88),(9,'Sep',81),
(10,'Oct',69),(11,'Nov',56),(12,'Dec',43)
UPDATE #MonthlyTempsStl
SET AvgHighTempC = (AvgHighTempF - 32)/1.8;
SELECT * FROM #MonthlyTempsStl;Теперь посмотрим, как ранжируется температура с использованием RANK, PERCENT_RANK и CUME_DIST.
SELECT MName, AvgHighTempF, AvgHighTempC,
RANK() OVER(ORDER BY AvgHighTempf) AS Rnk,
PERCENT_RANK() OVER(ORDER BY AvgHighTempF) * 100.0 AS PR,
CUME_DIST() OVER(ORDER BY AvgHighTempF) * 100.0 AS CD
FROM #MonthlyTempsStl;Январь является самым холодным месяцем. Нет месяца, холоднее чем январь, поэтому его температура имеет PERCENT_RANK = 0. CUME_DIST для нее равен 8.33% (значения умножались на 100, чтобы вернуть проценты), поскольку температура составляет 8,33% (1/12) в списке.
Июль - самый жаркий месяц. И PERCENT_RANK, и CUME_DIST возвращают 100, поскольку его температура жарче, чем во все другие месяцы, и находится на вершине списка. Когда вы используете эти функции, вы всегда видите 1 или 100%, возвращаемые для самого высокого элемента списка.
Если вам интересно, как вычисляются эти значения, то, как уже говорилось, они основываются на ранге. Вот формулы:
PERCENT_RANK = (RANK – 1)/(COUNT -1)
CUME_DIST = RANK/COUNT
Чтобы увидеть, как это работает, выполните запрос:
SELECT MName, AvgHighTempF, AvgHighTempC,
RANK() OVER(ORDER BY AvgHighTempf) AS Rnk,
(RANK() OVER(ORDER BY AvgHighTempF) -1)*100.0/(COUNT(*) OVER() -1) AS PR,
RANK()OVER(ORDER BY AvgHighTempF)*100.0/(COUNT(*) OVER()) AS CD
FROM #MonthlyTempsStl;За исключением нулей после десятичной точки, результаты выглядят одинаково. Имеется одна проблема при использовании этих формул. Если разбиение содержит только один элемент, то вы получите ошибку деления на нуль при использовании формулы PERCENT_RANK.
А что насчет производительности? Есть ли разница в производительности между использованием вычислений и более простых функций? Моя интуиция говорит, что разницы быть не должно, поскольку функции основаны на вычислениях. Но это не тот случай. Формулы несколько более эффективны, чем функции, для большого числа строк. Чтобы увидеть это, выполните следующий код для создания большой временной таблицы в AdventureWorks.
CREATE TABLE #SOD(SalesOrderID INT, SalesOrderDetailID INT, LineTotal Money);
INSERT INTO #SOD(SalesOrderID, SalesOrderDetailID, LineTotal)
SELECT SalesOrderID, SalesOrderDetailID, LineTotal
FROM Sales.SalesOrderDetail
UNION ALL
SELECT SalesOrderID + MAX(SalesOrderID) OVER(), SalesOrderDetailID, LineTotal
FROM Sales.SalesOrderDetail;
CREATE INDEX SalesOrderID_SOD ON #SOD
(SalesOrderID, SalesOrderDetailID) INCLUDE(LineTotal);Чтобы увидеть разницу, используйте STATISTICS IO. Выполните эти запросы и посмотрите вкладку Messages (сообщения).
SET STATISTICS IO ON;
SET NOCOUNT ON;
GO
PRINT 'Cume_dist'
SELECT SalesOrderID, SalesOrderDetailID, LineTotal,
CUME_DIST() OVER(PARTITION BY SalesOrderID ORDER BY LineTotal) * 100 AS Ranking
FROM #SOD
ORDER BY SalesOrderID, Ranking;
PRINT 'Formula'
SELECT SalesOrderID, SalesOrderDetailID, LineTotal,
RANK() OVER(PARTITION BY SalesOrderID ORDER BY LineTotal) * 100.0/COUNT(*) OVER(PARTITION BY SalesOrderID) AS Ranking
FROM #SOD
ORDER BY SalesOrderID, Ranking;Запрос, использующий функцию CUME_DIST имеет более 2 миллионов логических чтений из worktable (рабочей таблицы), в то время как функция - 700 тысяч. В каждом случае слишком много логических чтений! К счастью, когда эти функции используются в реальной задаче, то применяются к значительно меньшему числу строк, поэтому производительность не столь важна.
В SQL Server эта проблема решена, начиная с CTP3, самой последней доступной версии на момент написания статьи. В этой версии новый метод, называемый Batch Mode on Rowstore (пакетный режим на построчном хранении), используется, когда можно получить большую разницу в производительности. Ядро определяет, когда его использовать, но в своих прежних экспериментах я обнаружила его при около 130 тысячах строк, когда оконный агрегат является частью запроса.
Если переключить уровень совместимости на SQL Server 2019 (150) и снова выполнить эти запросы, число логических чтений для рабочих таблиц уменьшается до нуля.
Конечно, вам нужен SQL Server 2019, чтобы увидеть этот прирост производительности.
Для многих проектов любая функция может работать одинаково хорошо. Если это влияет на результаты, вы теперь знаете разницу между ними и сможете выбрать ту, которая лучшим образом подойдет для вашей ситуации.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой