
Как команда CHOOSE влияет на производительность?
Пересказ статьи Grant Fritchey. HOW DOES THE CHOOSE COMMAND AFFECT PERFORMANCE?
На первый взгляд, я, честно говоря, не думаю, что она сама по себе влияет на производительность, и зависит от того, где и как вы ее используете. Однако ответ всегда лучше подкреплять тестированием.
Команда T-SQL CHOOSE
Команда CHOOSE была добавлена в SQL Server 2012. Она довольно простая. Вы предоставляете массив и нумерованный индекс для этого массива, и команда CHOOSE будет возвращать соответствующее этому индексу значение. Рассмотрим вначале простую процедуру, и выполним её:
CREATE OR ALTER PROC dbo.CarrierAndFlag
(
@SalesOrderID INT,
@Flag INT
)
AS
BEGIN
SELECT sod.CarrierTrackingNumber,
CHOOSE(@Flag, 'A', 'B', 'C') AS Flag
FROM Sales.SalesOrderDetail AS sod
WHERE sod.SalesOrderID = @SalesOrderID;
END;
GO
EXEC dbo.CarrierAndFlag @SalesOrderID = 43662, -- int
@Flag = 2; -- intДля этого значения Flag, процедура вернет значение 'B'. План выполнения выглядит так:
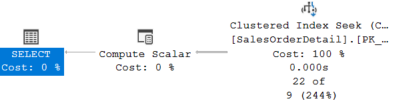
Простой поиск по кластеризованному индексу. Ничего особенного. Конечно, работа выполняется в операторе Compute Scalar. Мы можем там это увидеть:
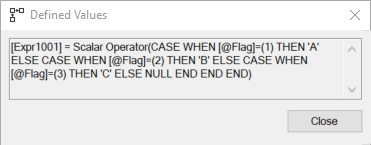
Теперь мы можем модифицировать нашу процедуру так, чтобы использовать CHOOSE со столбцами, а не предложенным массивом:
CREATE OR ALTER PROC dbo.CarrierAndFlag
(
@SalesOrderID INT,
@Flag INT
)
AS
BEGIN
SELECT sod.CarrierTrackingNumber,
CHOOSE(@Flag, sod.OrderQty,sod.LineTotal,sod.UnitPrice) AS Flag
FROM Sales.SalesOrderDetail AS sod
WHERE sod.SalesOrderID = @SalesOrderID;
END;
GOПолученный в результате план выполнения идентичен представленному выше, конечно, за исключением изменений в Compute Scalar:
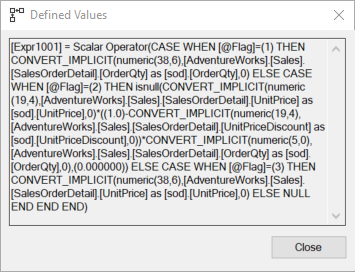
В документации описывается, как используется старшинство типов данных для определения преобразования, но в целом мы не видим здесь проблем с производительностью. Фактически, в среднем, первая итерация выполнялась около 449 мс при 3,24 чтениях. Вторая итерация заняла 447 мс и 3,24 чтения. Другими словами, идентично по всем показателям.
Итак, мы можем с уверенностью сказать, что CHOOSE не влияет на производительность, так ведь?
Минуточку.
Некластеризованные индексы и CHOOSE
Я собираюсь изменить процедуру на поиск по ProductID. В AdventureWorks есть некластеризованный индекс, который может быть полезен:
CREATE OR ALTER PROC dbo.CarrierAndFlag
(
@ProductID INT,
@Flag INT
)
AS
BEGIN
SELECT sod.CarrierTrackingNumber,
CHOOSE(@Flag, sod.OrderQty,sod.LineTotal,sod.UnitPrice) AS Flag
FROM Sales.SalesOrderDetail AS sod
WHERE sod.ProductID = @ProductID;
END;
GOИ, в зависимости от значения, которое вы передаете для ProductID (прослушивание параметра, другая история), вы получите следующий план:
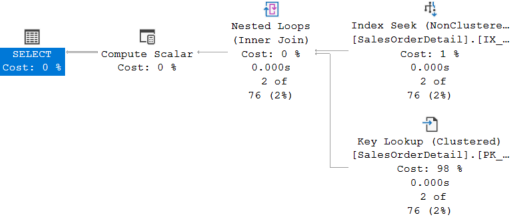
Итак, кажется, что CHOOSE не влияет на выбор индекса. Можем мы добавить оператор INCLUDE, чтобы устранить Key Lookup, и заставить CHOOSE работать как надо? Вот мой индекс:
CREATE INDEX ChooseTest
CREATE INDEX ChooseTest
ON Sales.SalesOrderDetail (ProductID)
INCLUDE (
CarrierTrackingNumber,
OrderQty,
LineTotal,
UnitPriceDiscount,
UnitPrice
);Если теперь мы выполним запрос, то получим следующий план выполнения:

Вот и все. Ответ получен, вы можете использовать CHOOSE в любой ситуации, и влияния на производительность оказано не будет.
Погодите, еще один момент.
CHOOSE в предложении WHERE
Что произойдет, если мы переместимся за пределы вполне безопасного места в SELECT? Давайте опять изменим процедуру:
CREATE OR ALTER PROC dbo.CarrierAndFlag
(
@Flag INT
)
AS
BEGIN
SELECT sod.CarrierTrackingNumber
FROM Sales.SalesOrderDetail AS sod
WHERE sod.ProductID = CHOOSE(@Flag, 897, 998, 432);
END;
GOЕсли теперь мы выполним код для значения @Flag = 2, то получим следующий план:
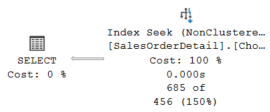
И здесь начинается самое интересное. Если мы перекомпилируем процедуру или удалим её из кеша, и передадим значение @Flag = 1, результат изменится с 685 на 2. Хотя оценка числа строк остается той же. Она использует среднее значение статистики в индексе. И используется индекс.
Давайте поломаем.
Ломаем использование индекса с CHOOSE
Честно говоря, я был шокирован, что перемещение функции в предложение WHERE не привело тут же к сканированию. Конечно, возможно, сканированию некластеризованного индекса, но точно scan, а не seek.
Итак, проведя несколько экспериментов, изменяющих значение к строке, которое свелось к мягкому неявному преобразованию, мы по-прежнему имеем использование индекса. Попытка с десятичными числами дало то же самое. Это имеет смысл согласно документации. Даже смешанные типы данных не повлияли на планы.
Затем я добавил столбец в оператор CHOOSE. И получил такой план:
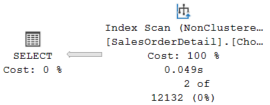
Ключ находится в предикате:
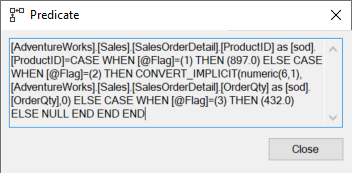
Добавляя столбец, я пробовал использовать разные типы данных, безопасные, ничего сверхординарного и, несмотря ни на что, я снова получал сканирование.
Заключение
Я мог бы еще написать целую кучу тестов. Если бы вы меня спросили о поведении CHOOSE в предложении WHERE, я бы предположил, что это всегда будет сводиться к сканированию. Я был немного удивлен, что она может несколько лучше использовать индексы. Однако поведение при добавлении столбца имело для меня большой смысл.
В целом, я бы сказал, что использование CHOOSE в предложении SELECT прекрасно с точки зрения производительности. При фильтрации, если вы используете значения, вероятно, тоже все хорошо. Но если вы пытаетесь добавить туда столбцы, не делайте этого.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой