
Как думать подобно SQL server: порядок столбцов в индексе весьма важен
Пересказ статьи Brent Ozar. How to Think Like the Engine: Index Column Order Matters a LOT
Мы работали с кластеризованным индексом таблицы Users, который построен на столбце identity, значения в котором начинаются с 1 и продолжаются до ...:
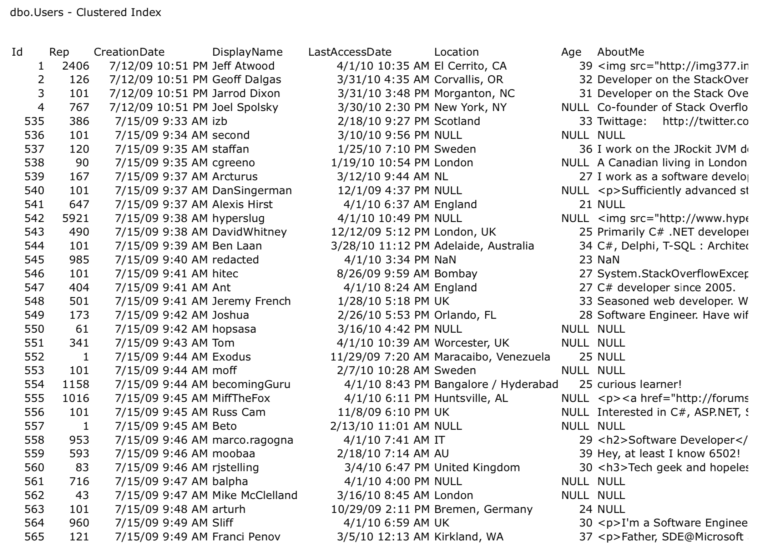
Затем в последней статье серии мы добавили широкий некластеризованный индекс по LastAccessDate, Id, DisplayName и Age:
CREATE INDEX IX_LastAccessDate_Id_DisplayName_Age
ON dbo.Users(LastAccessDate, Id, DisplayName, Age);
GO
листовые страницы которого выглядят так:
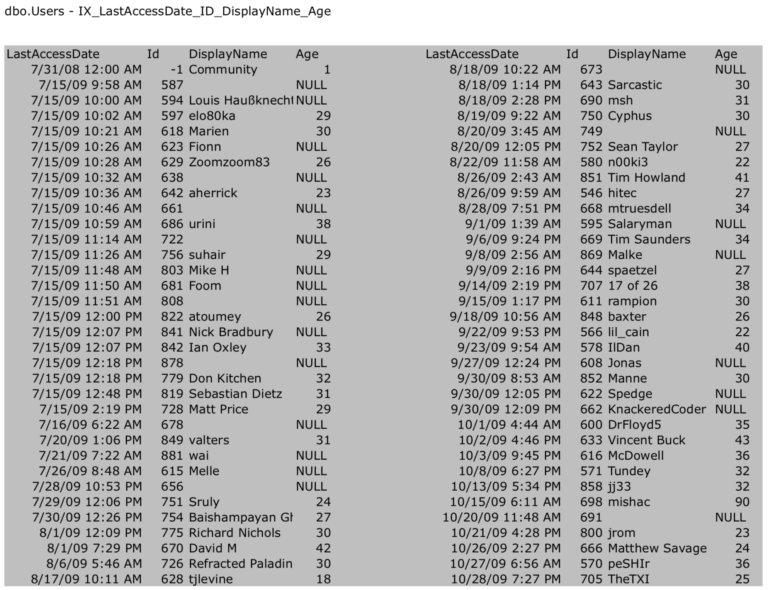
Итак, что произойдет, если мы выполним такой запрос:
SELECT Id
FROM dbo.Users
WHERE DisplayName = N'Brent Ozar';
DisplayName присутствует в некластеризованном индексе, но мы не можем использовать его для поиска.
Если вы посмотрите на серые страницы индекса, они организованы по LastAccessDate, затем по Id, затем по DisplayName. Мы не может использовать эти страницы непосредственного для поиска Brent.
В этом случае большинство людей полагают, что SQL Server будет сканировать (не искать) весь кластеризованный индекс (белые страницы). Если у нас нет индекса, который непосредственно поддерживает наш запрос, мы полагаем, что SQL Server прибегнет к сканированию таблицы. Хорошие новости: он может оказаться умнее.
SQL Server говорит: "Если я должен сканировать всю таблицу, чтобы найти несколько строк, нет ли наиболее узкой/минимальной копии таблицы, которую я мог бы просканировать, чтобы достичь своей цели?" Ведь можно использовать серый индекс - он просто собирается просканировать его так же, как он просканировал бы кластеризованный индекс. Какой индекс меньше/больше? Давайте используем sp_BlitzIndex, чтобы ответить на этот вопрос:
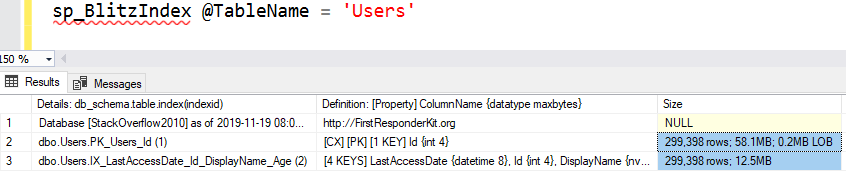
- CX/PK - это кластеризованный индекс, и его размер 58,1 Мб.
- Некластеризованный индекс (серые страницы) занимает 12,5 Мб.
Оба индекса имеют одинаковое число строк (299398), т.е. все строки в таблице включены в оба объекта. Оба содержат каждое значение DisplayName. Поэтому если вы ищете человека по DisplayName, вам было бы значительно проще просканировать 12,5 Мб страниц, а не 58,1 Мб страниц - и SQL Server думает так же. Он использует серые страницы:
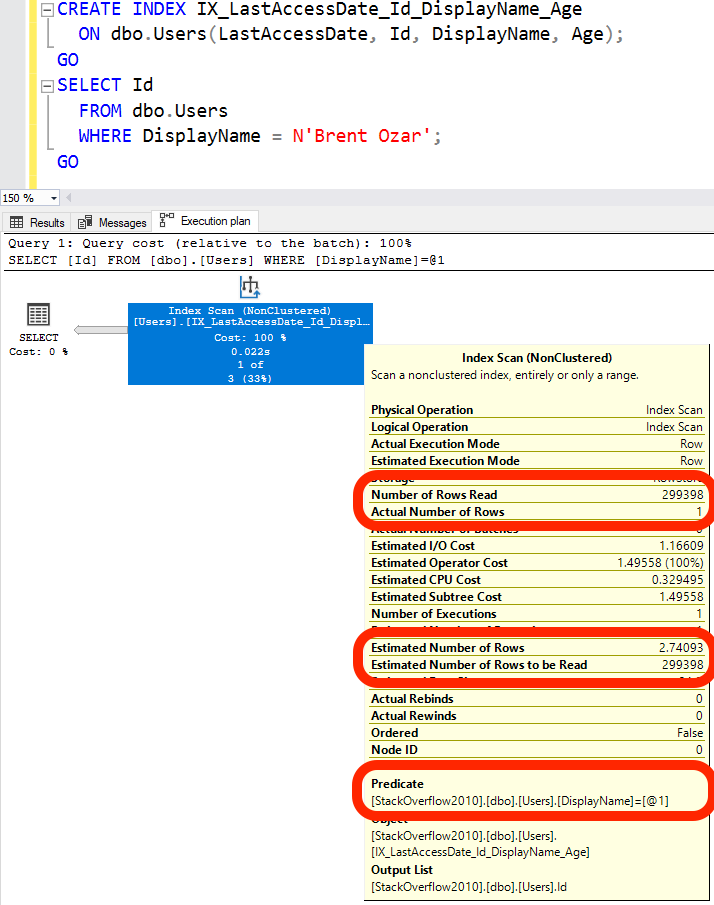 Число чтений строк (Number Of Rows Read) = 299398, поскольку SQL Server должен просканировать весь индекс, чтобы найти Brent Ozar'ов. Только один из нас появился. (Слава Богу.)
Число чтений строк (Number Of Rows Read) = 299398, поскольку SQL Server должен просканировать весь индекс, чтобы найти Brent Ozar'ов. Только один из нас появился. (Слава Богу.)Оценка числа чтений строк (Estimated Number of Rows Read) = 299398, поскольку SQL Server знает, что он должен прочитать всю таблицу, чтобы найти меня. Если бы я сказал SELECT TOP 1, тогда SQL Server смог бы закончить, как только обнаружил совпадающую строку, тем самым он мог бы прочитать меньше строк.
Predicate = @1 - несколько сложней. Отметим, что здесь говорится о предикате, а не поисковом предикате (Seek Predicate). Само слово “Predicate” означает, что SQL Server ищет эти данные, но он не может выполнить прямой поиск разыскиваемой строки - поскольку DisplayName не является первым столбцом в индексе.
Для получения поискового предиката необходимо, чтобы индекс начинался с DisplayName.
Давайте создадим такой, и повторно выполним наш запрос:
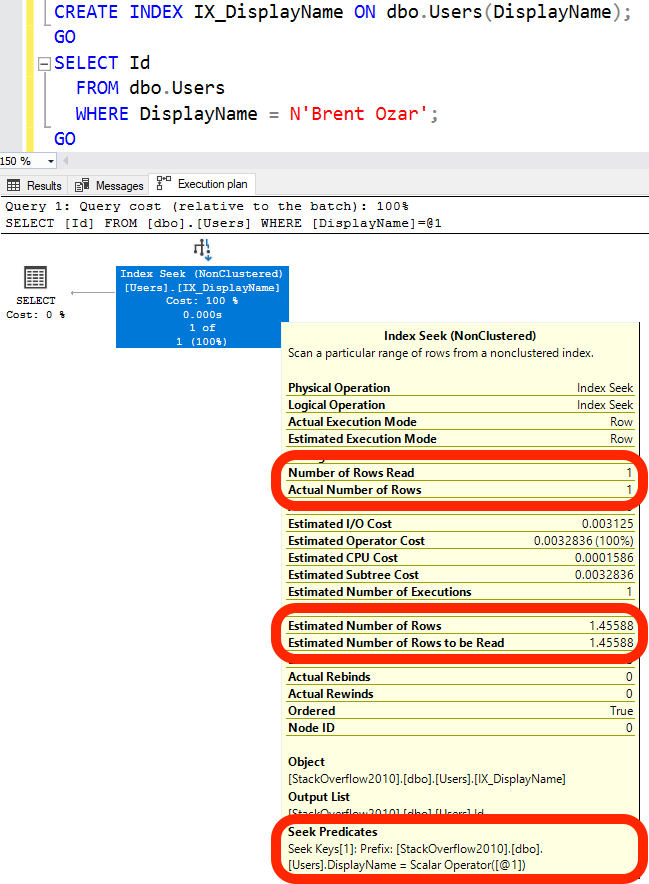 Теперь стало лучше: SQL Server может выполнить непосредственный поиск DisplayName.
Теперь стало лучше: SQL Server может выполнить непосредственный поиск DisplayName.Число чтений строк =1, как и фактическое число строк. Это означает, что вы получили реально хороший индекс для вашего запроса: SQL Server может прочитать в точности столько строк, сколько требуется, не больше.
Теперь мы имеем поисковый предикат (Seek Predicate), а не просто плоский предикат (Predicate). Мне бы хотелось, чтобы вместо слова "Predicate", SQL Server использовал термин предикат сканирования (Scan Predicate), поскольку, когда вы видите только слово "Predicate", вы вероятно читаете больше строк, чем фактически требуется; и это признак того, что вы могли бы улучшить производительность настройкой индексов.
Когда вы проектируете индексы, первый столбец играет большую роль.
Вы услышите мнения, что первый столбец должен быть действительно селективным или даже уникальным. Это в чем-то справедливо, но не вполне.
Что действительно важно, так это то, что первый столбец должен быть тем, по чему вы выполняете фильтрацию. Если мои запросы не фильтруют по LastAccessDate - как в рассматриваемом здесь примере - то индекс, который начинается с LastAccessDate, не сильно вам поможет, хотя LastAccessDate является весьма селективным (уникальным).
Однако, даже если вы выполняете поиск в первом столбце, это не означает, что вы закончили проектировать индексы. Даже простой запрос может иметь смесь поисковых и сканирующих предикатов. Но об этом далее.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой