
Как думать подобно SQL Server: когда поиск таковым не является
Пересказ статьи Brent Ozar. How to Think Like the Engine: When a Seek Isn’t
В прошлый раз я ввел понятие предикатов сканирования: операции плана выполнения, которые неспособны выполнить непосредственный поиск требуемых строк. Давайте возьмем другой запрос:
DropIndexes;
GO
CREATE INDEX IX_LastAccessDate_Id_DisplayName_Age
ON dbo.Users(LastAccessDate, Id, DisplayName, Age);
GO
SELECT Id
FROM dbo.Users
WHERE LastAccessDate > '1800/01/01'
AND DisplayName = N'Brent Ozar';
GO
Если у нас есть ТОЛЬКО индекс серых страниц на LastAccessDate, Id, DisplayName и Age, план нашего запроса выглядит примерно так:
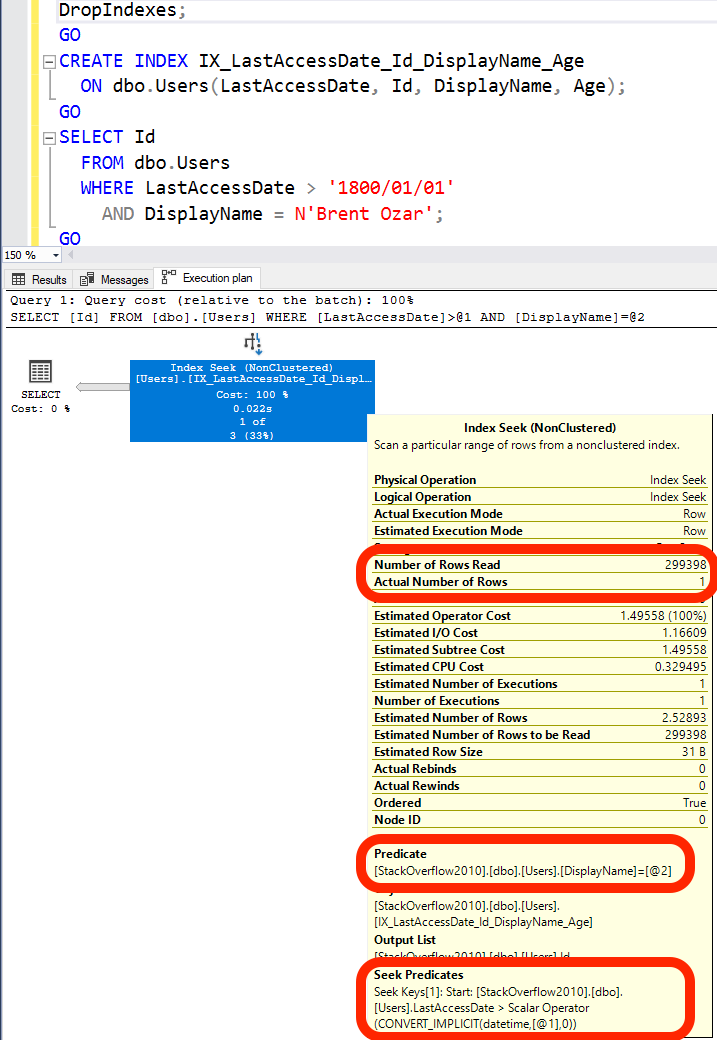
Я собираюсь описать его снизу вверх, поскольку так проще:
- Seek Predicates (поисковые предикаты): SQL Server смог выполнить поиск в этом индексе конкретной даты/времени. Он прыгнул к первому пользователю с LastAccessDate = 1800/01/01. Но это не исключит множество пользователей, хотя бы потому, что во времена оны Stack Overflow еще не существовал. Только теперь, когда SQL Server "нашел" этого пользователя, начинается настоящая работа.
- Predicate (предикат): теперь SQL Server проверяет имя в каждой строке, разыскивая человека с DisplayName = ‘Brent Ozar’.
- Number of Rows Read (число чтений строк): 299398 - поскольку мы должны проверить каждую отдельную строку в таблице, чтобы найти Brent.
Вы видите здесь Index Seek, но это не легкий оператор. Мы читаем каждую строку в таблице.
"Тогда почему SQL Server называет это поиском?"
Когда SQL Server строит планы выполнения, он использует всю информацию, которая ему известна на этот момент. Это не означает, что её достаточно много, и она к тому же может устареть. Мы говорили о том, как SQL Server использует статистику для построения планов, но статистика не обновляется в реальном времени.
Конечно, когда SQL Server обновил статистику на этой таблице в последний раз, он знал, что никто не заходил до 1800/01/01, но это не может гарантировать, что распределение данных не изменилось за время, прошедшее со времени последнего обновления статистики. Кроме того, у нас есть возможность запретить обновление статистики, поэтому статистика МОЖЕТ оказаться устаревшей.
Конечно, вы знаете на основе столбца с именем LastAccessDate, что никто не заходил на сайт StackOverflow.com в прошлом. Но данные просто не работают таким образом. SQL Server не знает, пока вы не сообщите ему это - и как раз здесь приходят на помощь вещи типа ограничений, сообщающие SQL Server бизнес-правила о ваших данных.
SQL Server должен просто сказать: "Хорошо, я знаю, что у меня есть индекс, который начинается с LastAccessDate, и они ищут конкретный диапазон LastAccessDate. Я могу прыгнуть к этому диапазону и пропустить любые дополнительные данные, которые были добавлены с момента последнего обновления статистики."
Технически этот план запроса работает в целом прекрасно - с ним все правильно. Но в этом плане выполнения что-то вводит в заблуждение, не так ли? Оператор говорит “Index Seek”, что подразумевает исключение строк, и "1 из 3" также звучит легко. Эта толстая стрелка - ваш единственный ключ, что здесь происходит больше работы, чем бросается поначалу в глаза.
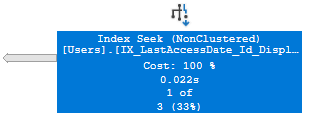
О, этот толстый размер стрелки? На актуальном плане это как бы связано с данными, выходящими из оператора на плане выполнения. Но это совсем не так - на актуальном плане это относится к количеству данных, которые были прочитаны оператором. Чем толще стрелка, тем больше работы было сделано.
Поэтому, когда вы видите толстую стрелку на актуальном плане, посмотрите в направлении, откуда исходит стрелка.
(Как тут не запутаться? Даже стрела отвлекает ваше внимание от проблемы. Я иногда думаю, что Microsoft делает это просто для того, чтобы обеспечить меня работой.)
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой