
Как думать подобно SQL Server: использование статистики при построении планов запроса
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine: Using Statistics to Build Query Plans
В последнем случае SQL Server выбирал между поиском по индексу и сканированием таблицы, балансируя вокруг точки перехода, чтобы выяснить, какой из вариантов будет более эффективным для выполнения запроса.
Что мне нравится в SQL Server, так это огромное число вещей, которые он должен рассмотреть при построении плана запроса. Он должен подумать о:
И это все он должен сделать, не глядя на данные в ваших таблицах. Заглянуть внутрь самих страниц было бы мошенничеством, и SQL Server не позволено это до тех пор, пока не начнется выполнение запроса. (Это начинает понемногу меняться в SQL Server 2017 и старше.)
Каждый индекс имеет связанную с ним статистику с тем же именем, и каждая статистика представляет собой единственную 8-килобайтную страницу метаданных, которые описывают содержание ваших индексов. Статистика существует вечно (и, по большей части, не менялась), так что это одно из тех мест документации SQL Server, которое действительно блестит: Books Online содержит тонну информации о статистике. Вам, честно говоря, не нужно знать её большую часть - но если вы хотите сделать вдумчивую настройку производительности, там есть масса отличного материала.
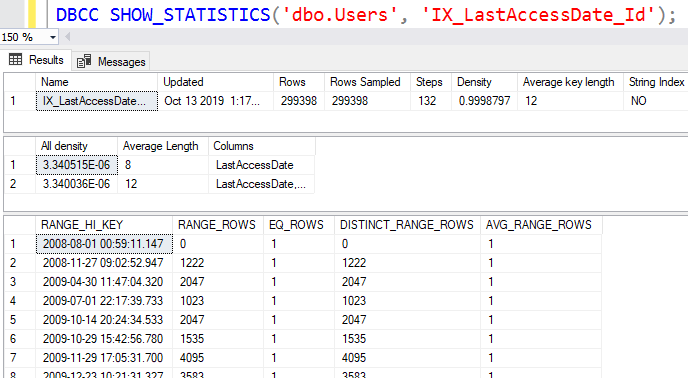
А сейчас давайте просто остановимся и почитаем содержимое нашей статистики с помощью DBCC SHOW_STATISTICS:
 Я не ожидаю, что вы знаете об этой команде или используете её часто (если вообще используете), но знание хотя бы того, что здесь происходит, начнет формировать ваше представление о том, как выполняется запрос.
Я не ожидаю, что вы знаете об этой команде или используете её часто (если вообще используете), но знание хотя бы того, что здесь происходит, начнет формировать ваше представление о том, как выполняется запрос.
Первый результирующий набор:
Второй результирующий набор показывает столбцы, включенные в статистику - в нашем случае LastAccessDate, затем Id. Первый столбец является основным, поскольку именно на нем строится гистограмма, что показывает третий результирующий набор.
Гистограммы кажутся сложными, но не все так плохо. Я проведу вас по первым двум строкам:
 Каждая строка подобна ведру.
Каждая строка подобна ведру.
Первая строка сообщает: "Первое значение LastAccessDate - 1 августа 2008 года около полуночи. Этой дате соответствует точно одна строка."
Вторая строка сообщает:
Для вашего запроса:
SQL Server открывает гистограмму и выполняет ее скроллинг вниз, чтобы найти знания о данных на момент последнего обновления статистики:
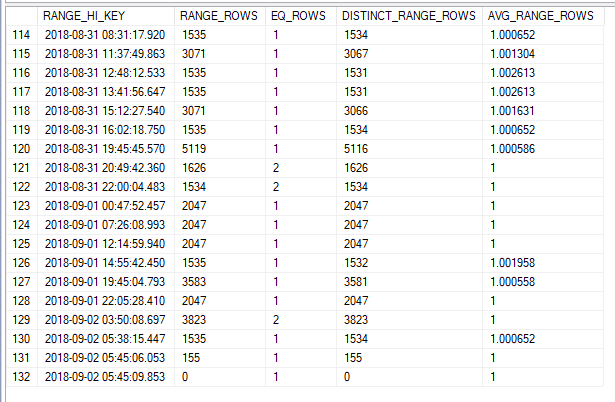 Он доходит до конца и говорит: "Итак, мы ищем 2018-09-02 04:00. У меня нет именно такого ведра, но я знаю, что:
Он доходит до конца и говорит: "Итак, мы ищем 2018-09-02 04:00. У меня нет именно такого ведра, но я знаю, что:
Он суммирует данные и выдает примерное количество строк. Чтобы увидеть его, наведите мышку на Index Seek и посмотрите внизу справа:
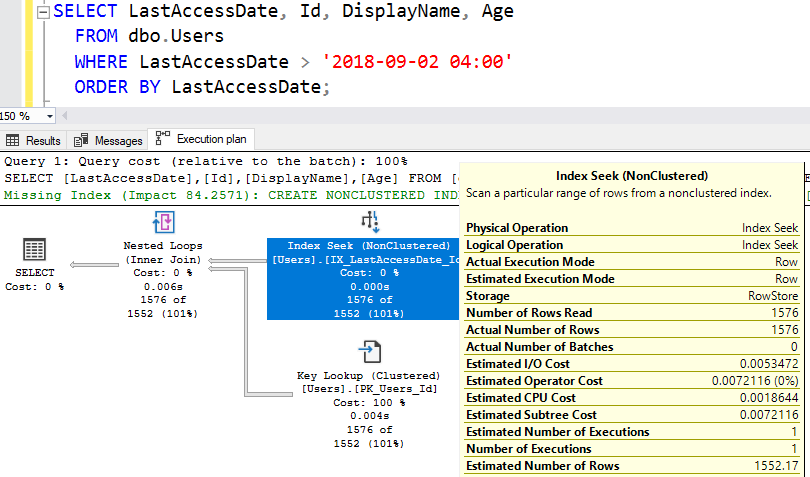 Это довольно хорошая оценка: 1552 строк при фактическом числе возвращаемых строк 1576. Хорошая работа, SQL Server.
Это довольно хорошая оценка: 1552 строк при фактическом числе возвращаемых строк 1576. Хорошая работа, SQL Server.
Чем проще SQL Server'у интерпретировать ваш запрос, тем лучше он работает. Если ваш запрос пытается все спрятать, используя функции или сравнения, тогда все меняется, что мы увидим в следующем выпуске.
- К каким таблицам пытается обратиться ваш запрос (что может быть скрыто за представлениями, функциями и вложениями).
- Как много строк будет возвращено из таблиц, которые вы фильтруете.
- Сколько строк будет затем возвращено из других соединяемых таблиц.
- Какие индексы имеются на всех этих таблицах.
- Какие индексы должны быть обработаны в первую очередь.
- Каким образом должен осуществляться доступ к этим индексам (поиск или сканирование).
- Как должны соединяться данные этих таблиц.
- Сколько памяти потребуется каждому оператору.
- Имеет ли смысл выделять несколько ядер CPU на каждый оператор.
И это все он должен сделать, не глядя на данные в ваших таблицах. Заглянуть внутрь самих страниц было бы мошенничеством, и SQL Server не позволено это до тех пор, пока не начнется выполнение запроса. (Это начинает понемногу меняться в SQL Server 2017 и старше.)
Чтобы принять эти решения, SQL Server использует статистику.
Каждый индекс имеет связанную с ним статистику с тем же именем, и каждая статистика представляет собой единственную 8-килобайтную страницу метаданных, которые описывают содержание ваших индексов. Статистика существует вечно (и, по большей части, не менялась), так что это одно из тех мест документации SQL Server, которое действительно блестит: Books Online содержит тонну информации о статистике. Вам, честно говоря, не нужно знать её большую часть - но если вы хотите сделать вдумчивую настройку производительности, там есть масса отличного материала.
А сейчас давайте просто остановимся и почитаем содержимое нашей статистики с помощью DBCC SHOW_STATISTICS:
Я не ожидаю, что вы знаете об этой команде или используете её часто (если вообще используете), но знание хотя бы того, что здесь происходит, начнет формировать ваше представление о том, как выполняется запрос.Первый результирующий набор:
- Updated - дата/время последнего обновления этой статистики, либо автоматически, либо с помощью заданий обслуживания индексов.
- Rows - число строк в объекте на время обновления статистики.
- Rows Sampled - как и в политике, с ростом численности населения SQL Server прибегает к выборке, чтобы получить общее представление о том, что представляет собой население.
Второй результирующий набор показывает столбцы, включенные в статистику - в нашем случае LastAccessDate, затем Id. Первый столбец является основным, поскольку именно на нем строится гистограмма, что показывает третий результирующий набор.
Гистограммы кажутся сложными, но не все так плохо. Я проведу вас по первым двум строкам:
Каждая строка подобна ведру.Первая строка сообщает: "Первое значение LastAccessDate - 1 августа 2008 года около полуночи. Этой дате соответствует точно одна строка."
Вторая строка сообщает:
- Range_Hi_Key = 2008-11-27 - это означает, что в ведре находятся все пользователи, для которых LastAccessDate > значения для предыдущего ведра (2008-08-01) и до значения 2008-11-27 включительно.
- Eq_Rows - только у одного пользователя LastAccessDate = 2008-11-27 09:02:52:947.
- Range_Rows - в этом ведре находится еще 1222 других строк.
- Distinct_Range_Rows - все из этих 1222 строк имеют отличные значения LastAccessDates. Это возможно, т.к. пользователи не логинятся одновременно.
- Avg_Range_Rows - для любого заданного значения в этом диапазоне имеется только одна совпадающая строка. Поэтому, если вы фильтруете, например, так WHERE LastAccessDate = ‘2008-10-15’, то SQL Server будет давать оценку 1 для соответствующих строк.
Вот откуда берется значение Estimated Number of Rows.
Для вашего запроса:
SELECT LastAccessDate, Id, DisplayName, Age
FROM dbo.Users
WHERE LastAccessDate > '2018-09-02 04:00'
ORDER BY LastAccessDate;
SQL Server открывает гистограмму и выполняет ее скроллинг вниз, чтобы найти знания о данных на момент последнего обновления статистики:
Он доходит до конца и говорит: "Итак, мы ищем 2018-09-02 04:00. У меня нет именно такого ведра, но я знаю, что:- Некоторые строки в ряду 130 могут соответствовать.
- Все строки в рядах 131 и 132 будут соответствовать.
Он суммирует данные и выдает примерное количество строк. Чтобы увидеть его, наведите мышку на Index Seek и посмотрите внизу справа:
Это довольно хорошая оценка: 1552 строк при фактическом числе возвращаемых строк 1576. Хорошая работа, SQL Server.Чем проще SQL Server'у интерпретировать ваш запрос, тем лучше он работает. Если ваш запрос пытается все спрятать, используя функции или сравнения, тогда все меняется, что мы увидим в следующем выпуске.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой