
Как думать подобно SQL Server: более широкие индексы для борьбы с плохим T-SQL
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine: Building Wider Indexes to Deal with Bad T-SQL
В последней статье мы столкнулись с проблемой при выполнении этих двух запросов:
SELECT LastAccessDate, Id, DisplayName, Age
FROM dbo.Users
WHERE LastAccessDate BETWEEN '2018-08-31' AND '2018-09-01'
ORDER BY LastAccessDate;
SELECT LastAccessDate, Id, DisplayName, Age
FROM dbo.Users
WHERE CAST(LastAccessDate AS DATE) = '2018-08-31'
ORDER BY LastAccessDate;Когда SQL Server увидел функцию в предложении WHERE второго запроса, он сбился на оценку в 1 строку, что и вызвало наши проблемы. При этом SQL Server выполнял поиск по индексу + поиск ключа, что не было оптимальным решением.
Если нам не позволено менять запрос, мы можем улучшить ситуацию построением более широкого покрывающего индекса. Прямо сейчас мы имеем такой индекс:
CREATE INDEX IX_LastAccessDate_Id ON dbo.Users(LastAccessDate, Id);Но допустим, что мы добавили один из этих индексов:
CREATE INDEX IX_LastAccessDate_Id_Includes
ON dbo.Users(LastAccessDate, Id)
INCLUDE (DisplayName, Age);
GO
CREATE INDEX IX_LastAccessDate_Id_DisplayName_Age
ON dbo.Users(LastAccessDate, Id, DisplayName, Age);
GOПолученные листовые страницы индекса будут выглядеть примерно так:
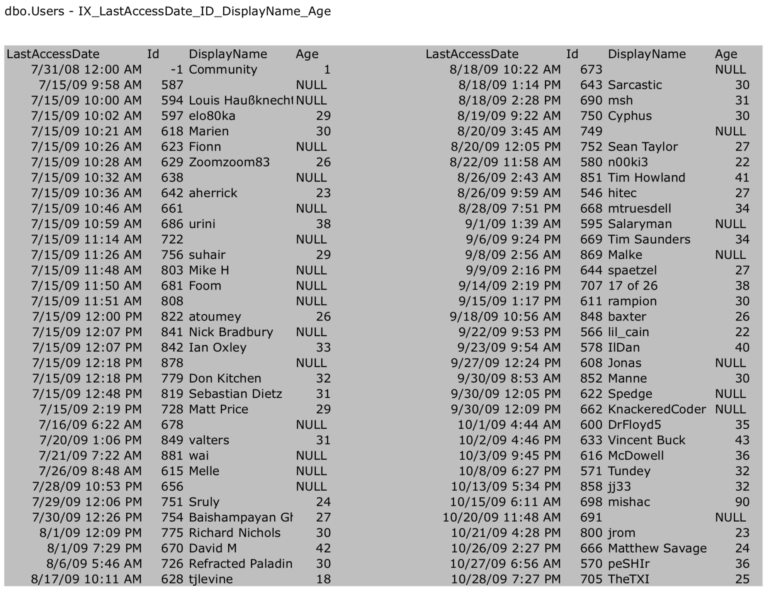
Насколько я понимаю вас, читатель, вашей первой реакцией будет кинуться вниз к комментариям и начать молотить по клавиатуре, обсуждая разницу между включаемыми столбцами и столбцами в ключе индекса. Удержим эту мысль. Мы вернемся к ней в следующей публикации этой серии. Пока же просто продолжим.
Добавьте любой из этих индексов - серьезно, мне все равно, какой вы выберите, но выберите только один - и планы запросов теперь выглядят идентично для ЛЮБОГО диапазона дат, даже для всей таблицы:
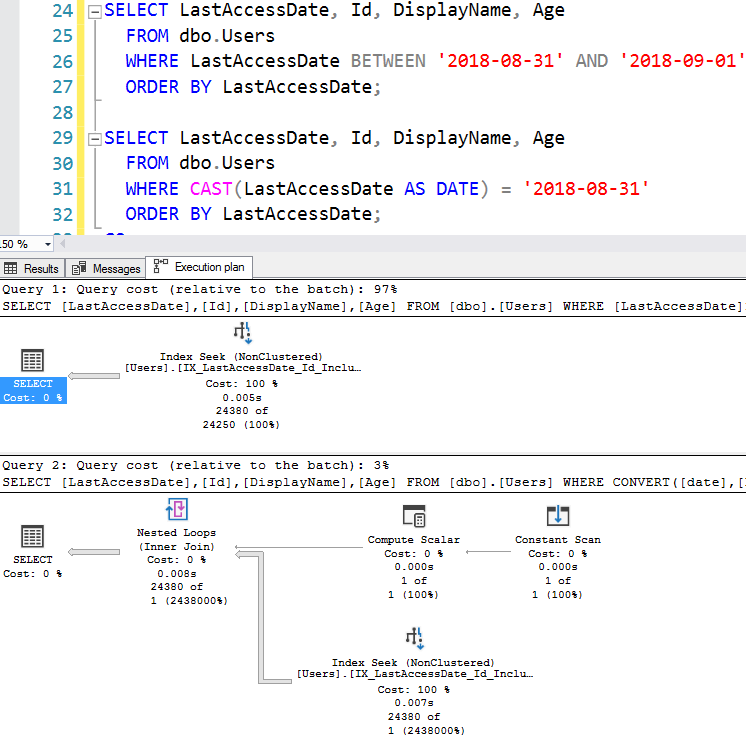
О, магия покрывающих индексов. Делайте индекс достаточно широким, и вы проложите дорогу вашим запросам. Теперь SQL Server не должен беспокоиться о точке перехода, поскольку этот индекс работает идеально вне зависимости от того, сколько строк мы получаем на выходе.
Так планы одинаковы, правильно?
Ну, нет. Посмотрим внимательно, и щелкнем по вкладке Messages (сообщения). SQL Server прячет там от вас грязные секреты:
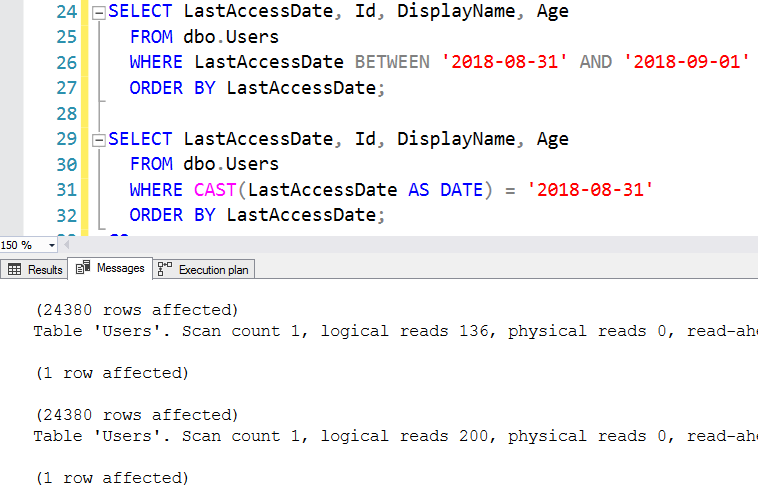
Нижний запрос фактически читает больше страниц, хотя он возвращает то же самое число строк! Почему так? Наведите мышку на каждый оператор index seek и посмотрите на число прочитанных строк. Вот результат для верхнего запроса:
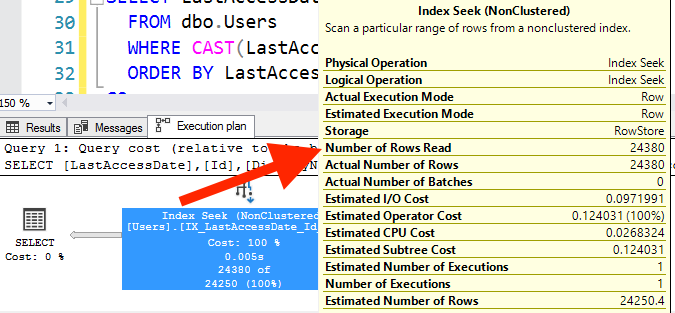
В верхнем запросе, когда ваши даты точно определены, SQL Server смог выполнить поиск непосредственно в индексе с правильной точки, прочитав 24380 отвечающих критерию строк. Однако в нижнем запросе:
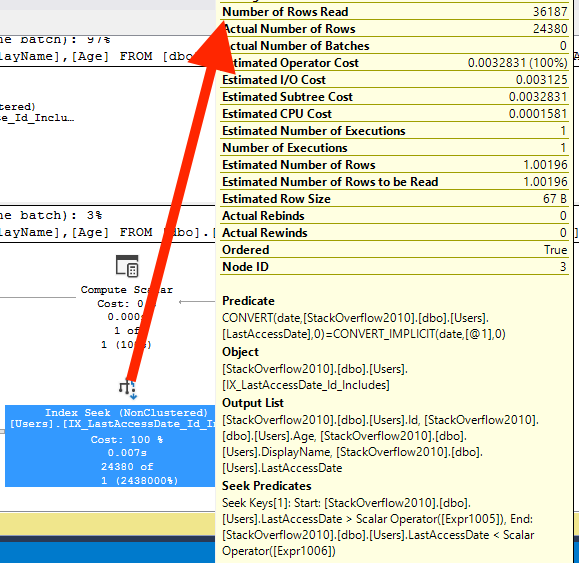
SQL Server напомнил меня в китайском буфете: он либо не знает, откуда стартовать, либо не знает, где финишировать, поэтому он накладывает больше строк на свою тарелку, чем ему необходимо. Мы обнаружим причину такого поведения (остаточный предикат) <ссылка вперед> далее в этой серии.
А пока не переживайте об этих 60-70 логических чтениях. Не зацикливайтесь на этом поиске в индексе, который не так хорош, как мог бы быть. Ведь он все равно намного лучше, чем 73225 логических операций чтения, которые мы имели в прошлый раз, и лучше, чем 7405 чтений, которые потребуются для сканирования таблицы.
60 чтений не имеют большого значения, но есть 3 важных вещи.
Вот эти три вещи, над которыми нужно попотеть:
1. Оценка числа строк (1) совершенно неточна, что нанесет ущерб последующим операциям в вашем запросе, например, если вы будете выполнять соединение с другими таблицами.
2. Даже если вы смотрите фактический план, процентное отношение стоимости остается оценочным - SQL Server никогда не возвращается, чтобы пересчитать "фактическую" стоимость запроса.
3. Оценочная стоимость запроса довольно далека от реальности:
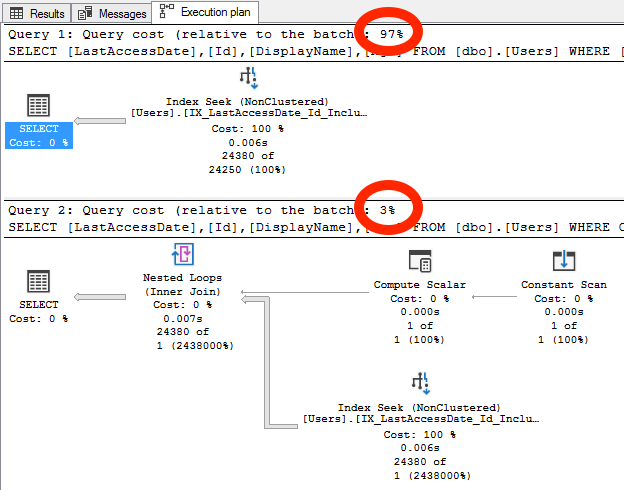
SQL Server говорит, что стоимость верхнего запроса составляет 97% от стоимости всего пакета, а нижнего - 3%. Это не верно: нижний запрос делает БОЛЬШЕ чтений, чем верхний запрос! В целом, причина, по которой нижний запрос показывает такую низкую стоимость в 3%, заключается в том, что SQL Server неточно оценивает число возвращаемых строк (1 строка).
Если функция в нижнем запросе действительно производит только одну строку, И если SQL Server достаточно умен, чтобы прочитать только действительно нужные строки (что не так с этой функцией), то уверен, что стоимость нижнего запроса будет дешевле.
Далее мы поговорим о том, должны ли столбцы входить в ключ индекса или быть включенными в индекс.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой