
Эй, это не моя сортировка!
Пересказ статьи Erik Darling. Hey, That’s Not My Sort!
Понимание плана
При чтении плана вы иногда замечаете сортировки, которые явно не те, что вы просили для упорядочения данных.
Иногда они появляются для поддержки сохраняющих порядок операторов, например: stream aggregate, merge join или segment. В другой раз они появляются, чтобы оптимизировать операцию, которая бы, в противном случае, полагалась на случайный ввод/вывод.
Случайный ввод/вывод считается значительно более дорогим, чем последовательный. Это происходит из-за того, что оптимизатор немного староват и не слишком удобен для хранилищ, конструктивно отличающихся от проигрывателя.
Иногда это вводит в заблуждение, поэтому я собираюсь рассмотреть пять запросов и их планы, куда оптимизатор внедряет оператор сортировки при том, что мы не заказывали никакой конкретный порядок.
Дело не в том, хорош или плох оператор Sort, я хочу просто показать вам, почему они иногда возникают.
Я повторю еще раз: ключевые столбцы кластеризованного индекса неявно присутствуют во всех ваших некластеризованных индексах. Где они хранятся в индексе, зависит от уникальности, но если ваш некластеризованный индекс в начале содержит столбцы, которые не являются ключами кластеризованного индекса, они не будут упорядочены на страницах индекса.
Когда оптимизатор выбирает план поиска ключа, он эффективно соединяет некластеризованный индекс с кластеризованным по ключевым столбцам кластеризованного индекса.
В некоторых случаях оптимизатор может принять решение сортировать выход некластеризованного индекса, чтобы уменьшить число случайных операций ввода-вывода, участвующих в поиске ключей.
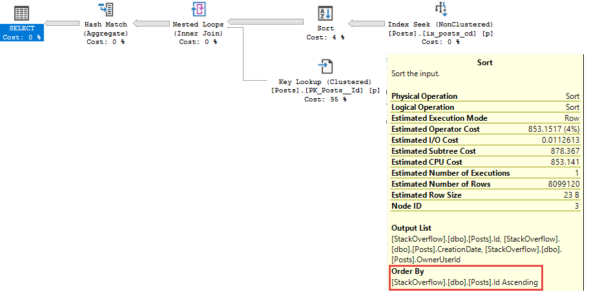
Так просто выполняется быстрей
Здесь вот что происходит. Столбец Id в таблице Posts является PK/CX. Некластеризованный индекс, который использовался для нашего запроса выглядит так:
Понятно, что столбца Id нет в определении.
Оптимизатор предпочел Stream Aggregate вместо Hash Aggregate. К сожалению (используя тот же некластеризованный индекс, что и прежде), столбец OwnerUserId никак не упорядочен. Это только включенный столбец на листовом уровне индекса, и не в каком-либо порядке, и он не существует на промежуточных страницах в качестве столбцов, по которым выполняется поиск.
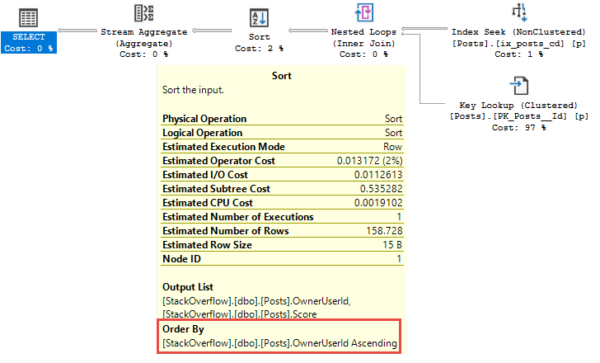
Островки в потоке
Там, где агрегаты Hash Match могут брать данные в любом порядке (это не обязательно делает их лучше, но погодите), Stream Aggregates требуется сначала все упорядочить.
Хотя это компромисс. Что касается Hash Match aggregate, то он ведет себя немного похоже на Hash Join в том, что все строки должны быть предоставлены оператору до начала хэширования. При Stream Aggregate, если данные не упорядочены в индексе, требуется выполнить сортировку. Sort ведет себя подобно Hash Join (ура! Компромисс!), и все строки должны передаваться оператору Sort до начала сортировки.
Общим для сортировки и хэширования также является то, что они обе потребляют память. Отсюда и возникает эта суета с выделением памяти.
Как и для Stream Aggregate, Merge Join требует отсортированного входа. В этом плане есть определенный смысл, поскольку с помощью двух сортировок вы можете избавить от дубликатов некоторый объем данных до сортировки. Здесь также имеется Stream Aggregate после Merge Join, который требует сортированного входа. Если Sort был после Merge Join (по каким-то странным причинам), пришлось бы сортировать гораздо больше данных.
Дико, да?
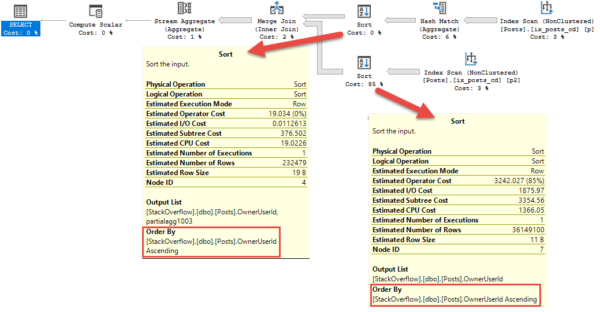
Пробка
Hash Match применяется к одной стороне соединения, чтобы уменьшить число строк для сортировки и соединения.
Почему не обеих сторон?
Хороший вопрос.
Этот план немного более очевиден, но я решил включить его для полноты
Я надеюсь, что когда-нибудь вы обнаружите это.
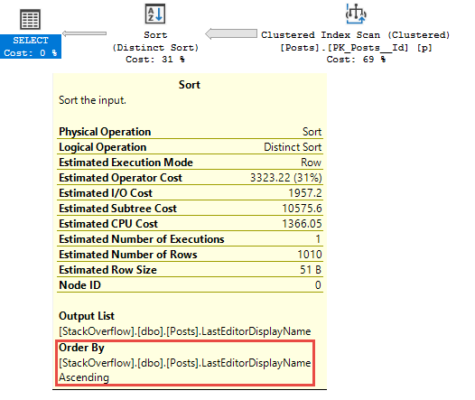
Здесь все в порядке
Если вы используете DISTINCT или GROUP BY в своих запросах, оптимизатор может выбрать их реализацию с помощью Distinct Sort.
Но почему не Sort с последующим Stream Aggregate?
Хороший вопрос.
Может и то, и другое?
Я знаю, вы думаете, что я жульничаю здесь.
Здесь есть сортировка, однако Sort здесь почти ничего не делает. Все эти запросы используют один и тот же индекс, как и прежде. Полностью поддерживается сортировка по CreationDate.
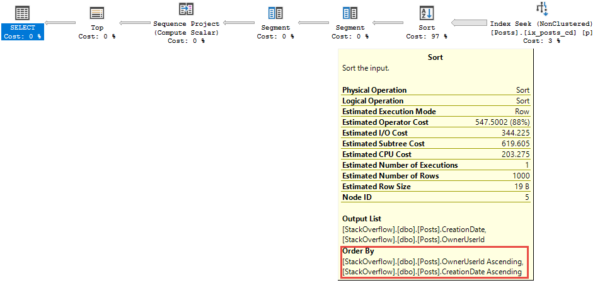
Теперь хорошо
Или, по крайней мере, так будет, если мы сначала не поставим Partition By OwnerUserId.
Partition By также сортирует данные. Вот почему важно правильное индексирование.
Оптимизатор фактически не имеет других альтернатив. Во многих других планах одно и то же можно сделать по-разному. Здесь только это.
Теперь, когда вы увидите мистическое появление оператора Sort в ваших планах запросов, вы будете иметь представление о том, почему это произошло.
Надеюсь, что помог вам в интерпретации и настройке, если последняя потребуется.
Помните, что единственное лекарство от сортировки по поисковому аргументу (сортировке не по выражению) - это индекс, который ее поддерживает. Добавление или пересмотр индексов может помочь (переписывание запросов тоже помогает, иногда...).
Случайный ввод/вывод считается значительно более дорогим, чем последовательный. Это происходит из-за того, что оптимизатор немного староват и не слишком удобен для хранилищ, конструктивно отличающихся от проигрывателя.
Иногда это вводит в заблуждение, поэтому я собираюсь рассмотреть пять запросов и их планы, куда оптимизатор внедряет оператор сортировки при том, что мы не заказывали никакой конкретный порядок.
Дело не в том, хорош или плох оператор Sort, я хочу просто показать вам, почему они иногда возникают.
План первый: оптимизированный поиск ключа
Я повторю еще раз: ключевые столбцы кластеризованного индекса неявно присутствуют во всех ваших некластеризованных индексах. Где они хранятся в индексе, зависит от уникальности, но если ваш некластеризованный индекс в начале содержит столбцы, которые не являются ключами кластеризованного индекса, они не будут упорядочены на страницах индекса.
Когда оптимизатор выбирает план поиска ключа, он эффективно соединяет некластеризованный индекс с кластеризованным по ключевым столбцам кластеризованного индекса.
SELECT p.OwnerUserId, SUM(p.Score) AS ScoreSum, MIN(p.CreationDate) AS MinScore, MAX(p.CreationDate) AS MaxScore
FROM dbo.Posts AS p WITH ( INDEX = ix_posts_cd )
WHERE p.CreationDate >= '2016-01-01'
GROUP BY p.OwnerUserId В некоторых случаях оптимизатор может принять решение сортировать выход некластеризованного индекса, чтобы уменьшить число случайных операций ввода-вывода, участвующих в поиске ключей.
Так просто выполняется быстрей
Здесь вот что происходит. Столбец Id в таблице Posts является PK/CX. Некластеризованный индекс, который использовался для нашего запроса выглядит так:
CREATE INDEX ix_posts_cd
ON dbo.Posts (CreationDate) INCLUDE (OwnerUserId);Понятно, что столбца Id нет в определении.
План второй: сортировка для поддержки Stream Aggregate
Оптимизатор предпочел Stream Aggregate вместо Hash Aggregate. К сожалению (используя тот же некластеризованный индекс, что и прежде), столбец OwnerUserId никак не упорядочен. Это только включенный столбец на листовом уровне индекса, и не в каком-либо порядке, и он не существует на промежуточных страницах в качестве столбцов, по которым выполняется поиск.
SELECT p.OwnerUserId, SUM(p.Score) AS ScoreSum
FROM dbo.Posts AS p
WHERE p.CreationDate BETWEEN '2008-06-01' AND '2008-08-01'
GROUP BY p.OwnerUserIdОстровки в потоке
Там, где агрегаты Hash Match могут брать данные в любом порядке (это не обязательно делает их лучше, но погодите), Stream Aggregates требуется сначала все упорядочить.
Хотя это компромисс. Что касается Hash Match aggregate, то он ведет себя немного похоже на Hash Join в том, что все строки должны быть предоставлены оператору до начала хэширования. При Stream Aggregate, если данные не упорядочены в индексе, требуется выполнить сортировку. Sort ведет себя подобно Hash Join (ура! Компромисс!), и все строки должны передаваться оператору Sort до начала сортировки.
Общим для сортировки и хэширования также является то, что они обе потребляют память. Отсюда и возникает эта суета с выделением памяти.
План третий: сортировка для поддержки Merge Join
Как и для Stream Aggregate, Merge Join требует отсортированного входа. В этом плане есть определенный смысл, поскольку с помощью двух сортировок вы можете избавить от дубликатов некоторый объем данных до сортировки. Здесь также имеется Stream Aggregate после Merge Join, который требует сортированного входа. Если Sort был после Merge Join (по каким-то странным причинам), пришлось бы сортировать гораздо больше данных.
SELECT COUNT(*)
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.OwnerUserId = p2.OwnerUserIdДико, да?
Пробка
Hash Match применяется к одной стороне соединения, чтобы уменьшить число строк для сортировки и соединения.
Почему не обеих сторон?
Хороший вопрос.
План четыре: Distinct Sort (уникальная сортировка)
Этот план немного более очевиден, но я решил включить его для полноты
Я надеюсь, что когда-нибудь вы обнаружите это.
Здесь все в порядке
Если вы используете DISTINCT или GROUP BY в своих запросах, оптимизатор может выбрать их реализацию с помощью Distinct Sort.
SELECT DISTINCT p.LastEditorDisplayName
FROM dbo.Posts AS pНо почему не Sort с последующим Stream Aggregate?
Хороший вопрос.
Может и то, и другое?
План пять: оконная функция
Я знаю, вы думаете, что я жульничаю здесь.
SELECT TOP 1000
p.OwnerUserId, DENSE_RANK() OVER ( PARTITION BY p.OwnerUserId ORDER BY p.CreationDate ) AS ranking_something
FROM dbo.Posts AS p
WHERE p.CreationDate >= '2010-10-30'Здесь есть сортировка, однако Sort здесь почти ничего не делает. Все эти запросы используют один и тот же индекс, как и прежде. Полностью поддерживается сортировка по CreationDate.
Теперь хорошо
Или, по крайней мере, так будет, если мы сначала не поставим Partition By OwnerUserId.
Partition By также сортирует данные. Вот почему важно правильное индексирование.
Оптимизатор фактически не имеет других альтернатив. Во многих других планах одно и то же можно сделать по-разному. Здесь только это.
Успокойтесь
Теперь, когда вы увидите мистическое появление оператора Sort в ваших планах запросов, вы будете иметь представление о том, почему это произошло.
Надеюсь, что помог вам в интерпретации и настройке, если последняя потребуется.
Помните, что единственное лекарство от сортировки по поисковому аргументу (сортировке не по выражению) - это индекс, который ее поддерживает. Добавление или пересмотр индексов может помочь (переписывание запросов тоже помогает, иногда...).
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой