
Индексированные представления - панацея производительности или беда
Пересказ статьи Jason Brimhall. Indexed Views – Performance Panacea or Plight
Индексированное представление - это представление, когда результирующий набор запроса (определения представления) материализуется вместо результирующего набора виртуальной таблицы стандартного (неиндексированного) представления. Часто приходится видеть, что индексированное представление создается с целью улучшить производительность. И слишком часто индексированное представление создается без учета накладных расходов.
Индексированные представления
В этой статье я надеюсь осветить некоторые наиболее важные накладные расходы, которые часто упускаются из вида, когда индексированное представление рассматривается как панацея производительности.
Установка
Для демонстрации игнорируемых затрат индексированных представлений я решил использовать базу данных AdventureWorks2014 (если у вас нет этой тестовой базы данных, вы можете скачать её копию отсюда). Я создам представление в этой базе данных, а затем добавлю к нему несколько индексов. Прежде чем поделиться всей настройкой, я, как все правильные администраторы баз данных, должен определить необходимый базовый уровень. Для этого базового уровня я не делаю ничего ужасно сложного. Я просто укажу размеры таблиц и информацию для сохранения всей базы данных.
Вот мои результаты относительно размера объектов в базе данных AdventureWorks2014:

Эти результаты показывают, что наибольший объект в базе данных - это таблица Person.Person, занимающая всего около 30Мб. Не такая уж большая, да и вся база не столь велика. Давайте посмотрим, что произойдет, когда я добавлю материализованное представление на базе таблицы Person.Person. Вот определение этого представления вместе с индексами, которые я добавлю для улучшения производительности некоторых важных рабочих запросов.
USE [AdventureWorks2014];
GO
CREATE VIEW [Person].[vPerson]
WITH SCHEMABINDING
AS
SELECT pp.BusinessEntityID
, pp.FirstName
, pp.LastName
, sp.[StateProvinceID]
, sp.[StateProvinceCode]
, sp.[IsOnlyStateProvinceFlag]
, sp.[Name] AS [StateProvinceName]
, sp.[TerritoryID]
, cr.[CountryRegionCode]
, cr.[Name] AS [CountryRegionName]
, pbe.AddressTypeID
, pp.AdditionalContactInfo
, pp.Demographics
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON sp.[CountryRegionCode] = cr.[CountryRegionCode]
INNER JOIN Person.Address pa
ON sp.StateProvinceID = pa.StateProvinceID
INNER JOIN Person.BusinessEntityAddress pbe
ON pbe.AddressID = pa.AddressID
INNER JOIN Person.Person pp
ON pp.BusinessEntityID = pbe.BusinessEntityID
WHERE pbe.AddressTypeID = 2;
GO
CREATE UNIQUE CLUSTERED INDEX CI_vPersonID ON Person.vPerson(BusinessEntityID);
CREATE INDEX IX_vPersonName ON Person.vPerson(FirstName,LastName);
CREATE INDEX IX_vPersonState ON Person.vPerson(FirstName,LastName,StateProvinceID,StateProvinceCode,StateProvinceName);После выполнения всего этого кода для создания нового представления с индексами, я имею следующие результаты по размерам:

Создание этого представления понизило кучу хранилищ. Оно поднялось сразу на второе место в списке самых больших объектов в этой базе данных. Вы можете увидеть разницу, сравнив выделенные строки с предыдущим рисунком. Представление vPerson выделено красным на втором рисунке.
Конечно, это может быть надуманный пример, и люди не делают такого в реальном мире, правильно? Ответ простой: НЕТ! ЭТО ПРОИСХОДИТ. Я очень часто наблюдаю подобные ситуации. Слишком часто большие текстовые поля добавляются в индексированное представление, чтобы ускорить выборку. Я сымитировал это добавлением двух XML-столбцов из таблицы Person.Person. Это определенно лишнее, поскольку простое соединение с таблицей на основе BusinessEntityID даст мне эти два столбца. Все чего я добился - это продублировал хранящиеся данные и по самым скромным подсчетам увеличил стоимость хранения на 25% для этой небольшой базы. Для информации, в таблице Person.Person и в этом новом представлением имеется по 13 столбцов.
Я называю увеличение на 25% стоимости хранения значительным. Увеличение хранилища на 25% для единственного материализованного представления не является чем-то особенным. Я видел мультитерабайтные базы данных, в которых 25% общего хранилища данных занимало единственное представление. Если вы испытываете недостаток свободного пространства, любое неожиданное увеличение объема данных может вызвать нелинейный рост требований к данным только лишь из-за наличия индексированных представлений. Принимайте это в расчет, выбирая между настройкой производительности кода и созданием индексированного представления из существующего.
Производительность лейкопластыря
Я связывал использование индексированных представлений со средством для повышения производительности. Это делается преобразованием тормозящего запроса в представление. Идея состоит в том, что запрос будет выполняться быстрее, поскольку создается конкретный индекс под соответствующий набор данных. Как правило, выигрыш в производительности от использования индексированного представления для маскировки плохого запроса ощущается, когда запрос сложный. К сожалению, запрос, рассматриваемый здесь не очень сложный. Поскольку это так, давайте сначала посмотрим на план выполнения другого запроса, который выполняется ужасно медленно, хотя тоже не очень сложен:
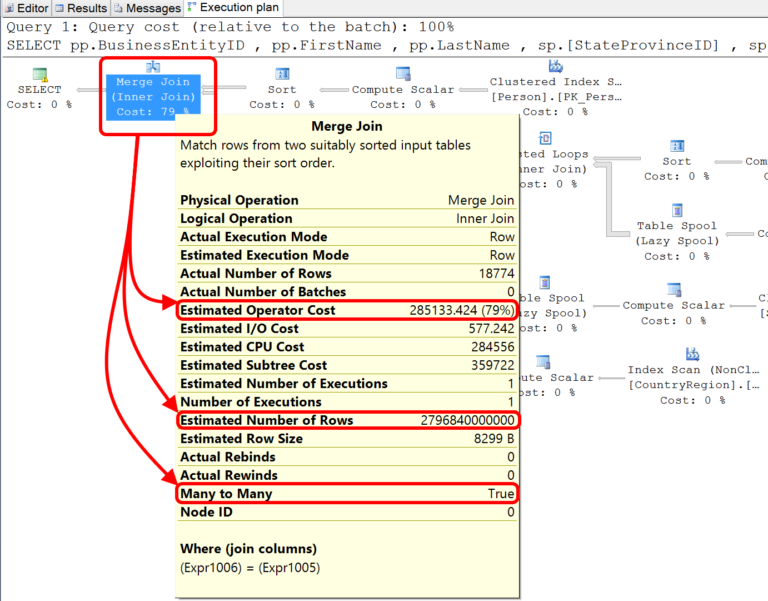
Имеем несколько табличных спулов и сканирования индекса. Видно, что максимальную стоимость в пакете имеет merge join с операцией соединения "многие ко многим". Индексированное представление в этом случае дает мне весьма существенное улучшение на этом запросе (взгляните на эту предполагаемую стоимость, а затем на оценку числа строк). Что если бы я мог бы настроить немного запрос и избежать затрат на хранение? Давайте посмотрим!
Посмотрите на базовый запрос для этого нового представления:
SELECT pp.BusinessEntityID
, pp.FirstName
, pp.LastName
, sp.[StateProvinceID]
, sp.[StateProvinceCode]
, sp.[IsOnlyStateProvinceFlag]
, sp.[Name] AS [StateProvinceName]
, sp.[TerritoryID]
, cr.[CountryRegionCode]
, cr.[Name] AS [CountryRegionName]
, pbe.AddressTypeID
, pp.AdditionalContactInfo
, pp.Demographics
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON RTRIM(LTRIM(sp.[CountryRegionCode])) = RTRIM(LTRIM(cr.[CountryRegionCode]))
INNER JOIN Person.Address pa
ON RTRIM(LTRIM(sp.StateProvinceID)) = RTRIM(LTRIM(pa.StateProvinceID))
INNER JOIN Person.BusinessEntityAddress pbe
ON RTRIM(LTRIM(pbe.AddressID)) = RTRIM(LTRIM(pa.AddressID)) INNER JOIN Person.Person pp
ON RTRIM(LTRIM(pp.BusinessEntityID)) = RTRIM(LTRIM(pbe.BusinessEntityID))
WHERE RTRIM(LTRIM(pbe.AddressTypeID)) = 2;Глядя на запрос, вы можете спросить себя, почему так много функций trim на каждом соединении? Этот экстрим можно легко пофиксить. Ни одно из полей, участвующих в соединениях, не требуется тримить, поскольку они все числового типа. Начав с этого и удалив все использования этой функции в соединениях, мы должны получить значительное улучшение скорости запроса и без использования представления. Тестирование даст результаты производительности, аналогичные первому представлению в этой статье. Это небольшое изменение приводит к 1-секундному выполнению запроса вместо почти 90 секунд. Это огромный прирост, который получен без дополнительных расходов на увеличение размера хранилища.
Встречаю ли я такие вещи на практике? Да! Потратьте немного времени на устранение корневой проблемы вместо поиска быстрого решения, и производительность может вас поразить. Хотя бывают случаи, когда индексированное представление может быть абсолютным требованием. Бывают случаи, когда это оправдано, и нет никакого другого способа обойти его. Если индексированное представление является абсолютной необходимостью, то необходимо учитывать еще несколько факторов.
Исчезающий закон
Выше я показал, что индексированное представление требует места в хранилище, и что созданное новое представление сразу потребовало себе второе по размеру место в базе данных. Теперь, чтобы перейти к следующему моменту, я еще раз покажу, что индексы присутствуют и занимают место на диске. Это можно сделать с помощью следующего запроса:
SELECT o.name AS ObjName
, i.name AS IdxName
, SUM(ps.page_count) AS page_count
, SUM(ps.record_count) AS record_count
, SUM(ps.page_count) / 128.0 AS SizeMB
FROM sys.indexes i
INNER JOIN sys.objects o
ON i.object_id = o.object_id
INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'detailed') ps
ON ps.object_id = o.object_id
WHERE o.name LIKE 'vperson%'
GROUP BY o.name
, i.name;Результаты этого запроса выглядят подобно следующим (напомню, что я создал новое индексированное представление для второго демонстрационного примера, и результаты относятся к этому второму представлению):
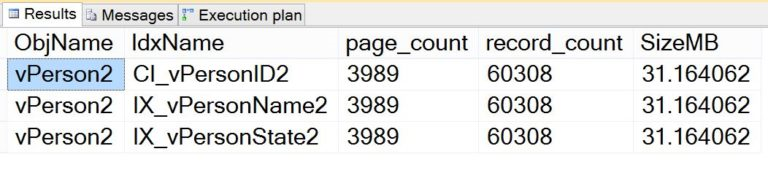
Теперь, когда мы знаем, что индекс присутствует и занимает место, пришло время внести изменения в представление и посмотреть, что произойдет. Я исхожу из ранее сделанного утверждения, что включение двух столбцов XML в представление совершенно не нужно и является причиной слишком большого потребления пространства. Я могу воспользоваться преимуществами представления за небольшую цену, если я ИЗМЕНЮ представление, удалив эти столбцы. Итак, я выполняю следующий оператор ALTER:
ALTER VIEW [Person].[vPerson2]
WITH SCHEMABINDING
AS
SELECT pp.BusinessEntityID
, pp.FirstName
, pp.LastName
, sp.[StateProvinceID]
, sp.[StateProvinceCode]
, sp.[IsOnlyStateProvinceFlag]
, sp.[Name] AS [StateProvinceName]
, sp.[TerritoryID]
, cr.[CountryRegionCode]
, cr.[Name] AS [CountryRegionName]
, pbe.AddressTypeID
FROM [Person].[StateProvince] sp
INNER JOIN [Person].[CountryRegion] cr
ON RTRIM(LTRIM(sp.[CountryRegionCode])) = RTRIM(LTRIM(cr.[CountryRegionCode]))
INNER JOIN Person.Address pa
ON RTRIM(LTRIM(sp.StateProvinceID)) = RTRIM(LTRIM(pa.StateProvinceID))
INNER JOIN Person.BusinessEntityAddress pbe
ON RTRIM(LTRIM(pbe.AddressID)) = RTRIM(LTRIM(pa.AddressID))
INNER JOIN Person.Person pp
ON RTRIM(LTRIM(pp.BusinessEntityID)) = RTRIM(LTRIM(pbe.BusinessEntityID))
WHERE RTRIM(LTRIM(pbe.AddressTypeID)) = 2;Обратите внимание на то, сколько времени выполняется команда ALTER - почти мгновенно. Давайте проверим индексы, чтобы убедиться, что они все еще в рабочем порядке и не требуют дефрагментации. Для этого я снова запущу наш запрос, чтобы проверить индексы и их размеры.
SELECT o.name AS ObjName
, i.name AS IdxName
, SUM(ps.page_count) AS page_count
, SUM(ps.record_count) AS record_count
, SUM(ps.page_count) / 128.0 AS SizeMB
FROM sys.indexes i
INNER JOIN sys.objects o
ON i.object_id = o.object_id
INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'detailed') ps
ON ps.object_id = o.object_id
WHERE o.name LIKE 'vperson%'
GROUP BY o.name
, i.name;На этот раз меня ждет небольшой сюрприз: у меня больше нет индексов в этом представлении. Изменение определения представления сразу удаляет все индексы, которые были построены на нём. Если это делается в производственной системе, представьте себе последствия и проблемы, которые могут возникнуть.
Заключение
Эту статью я посвятил индексируемым представлением и трем моментам, которые часто упускаются из виду при внедрении материализованных представлений. Этими обсуждаемыми моментами являются: хранилище, изменения представления и эффект пластыря. Игнорирование стоимости хранения может иметь серьезные последствия для производственной среды. Реализация индексированного представления без предварительной настройки кода может привести к тому, что вы просто потеряете ресурсы. Последний момент заключается в том, что любое изменение индексированного представления приведет к удалению индексов. Это часто упускаемая из виду особенность индексированных представлений. Если вы забыли пересоздать индексы в представлении после внесения изменений, вы можете столкнуться с производственным сбоем.
Есть еще несколько критических соображений относительно индексированных представлений, которые также часто упускаются из виду: это блокировка, взаимоблокировка (тупик) и обслуживание.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой