
Функции работы со строками в SQL Server, Oracle и PostgreSQL
Пересказ статьи Andrea Gnemmi. SQL String functions in SQL Server, Oracle and PostgreSQL
Строковые функции широко используются для манипуляции, извлечения, форматирования и поиска текста для типов данных char, nchar (unicode), varchar, nvarchar (unicode) и т.д. К сожалению, имеются некоторые отличия в строковых функциях SQL Server, Oracle и PostgreSQL, которые обсуждаются в этой статье.
Как всегда мы будет использовать свободно загружаемую с github базу данных Chinook, т.к. она доступна в форматах множества РСУБД. Она представляет собой имитацию магазина цифровых носителей с некоторым количеством данных, и вы можете загрузить ту версию, которая вам нужна, и получить все скрипты для создания структуры данных и операторы для вставки данных.
Начнем с самой простой и наиболее часто используемой операции - конкатенации двух (или большего числа) строк, и рассмотрим различные методы для ее выполнения.
Для конкатенации строк с помощью T-SQL в SQL Server имеется два основных метода, первый использует для конкатенации оператор +. Для примера соединим в один столбец имя и фамилию наших клиентов:
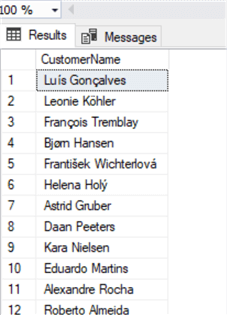
Делается легко с добавлением пробела посередине.
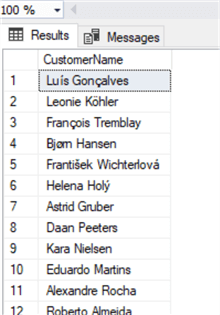
Тот же результат можно получить с помощью функции CONCAT, используя запятую как разделитель между параметрами функции:
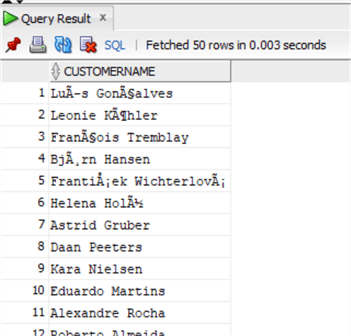
В Oracle оператором конкатенации является двойной символ "|", т.е. ||:
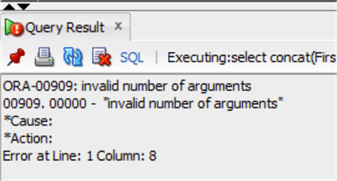
В Oracle функция CONCAT может использоваться только с двумя строками, поэтому следующий оператор не работает:
Будет возвращена ошибка:
А так работает:
И результат:
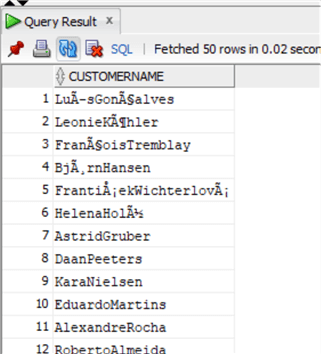
В PostgreSQL оператор конкатенации такой же, как и в Oracle:
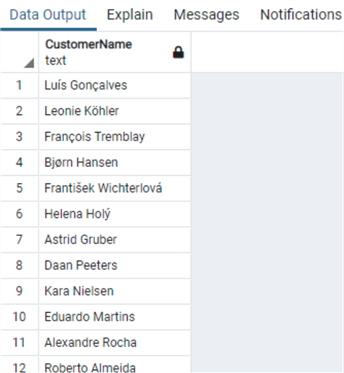
А функция CONCAT работает в PostgreSQL, как в SQL Server:
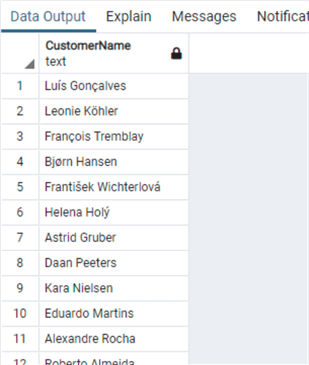
Другой типичной операцией является извлечение некоторой части строки. Например, представим, что нам нужно извлечь инициал имени (Firstname) и дополнить его точкой с последующей фамилией (Lastname) для каждого заказчика.
В SQL Server мы используем функцию SUBSTRING:
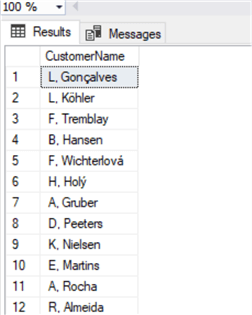
Функция SUBSTRING принимает в качестве первого параметра строку, второго - начальную позицию подстроки и третьего - количество символов, которые нужно извлечь.
Тот же результат можно получить с помощью функции LEFT:
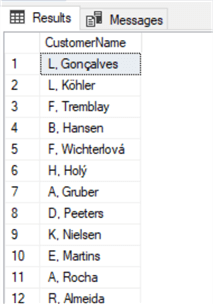
Функция LEFT извлекает указанное число символов от начала строки (слева).
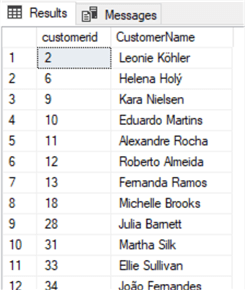
Имеется также и функция RIGHT. Предположим, что нам требуется получить всех заказчиков, чьи имена заканчиваются на гласную букву:
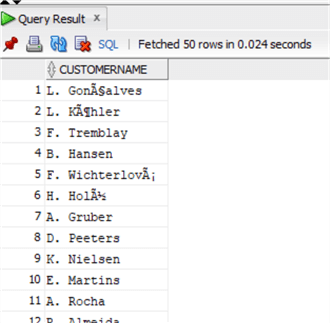
В Oracle эта функция похожа, хотя несколько отличается ее имя - SUBSTR:
Остальное аналогично SQL Server.
К сожалению, в Oracle PL/SQL нет функций LEFT или RIGHT, поэтому мы будем всегда использовать SUBSTR для извлечения подстроки.
В PostgreSQL, как и в SQL Server, есть функция SUBSTRING:
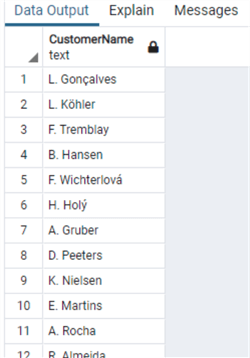
Мы также можем использовать функцию LEFT:
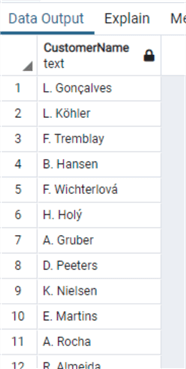
и использовать функцию RIGHT:
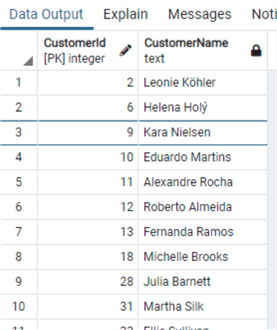
Подобно функциям LEFT и RIGHT, имеются функции LTRIM and RTRIM, которые используются для удаления пробелов слева или справа заданной строки. Они часто используются для очистки данных, с чем я часто сталкивался при работе с ETL в хранилищах данных.
Сначала мы испортим данные добавлением некоторого числа пробелов в начале некоторых строк столбца FirstName:
Теперь посмотрим, как выглядят данные:
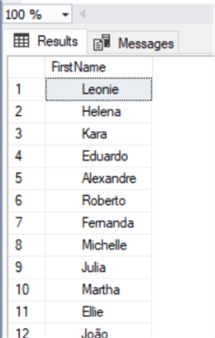
Как ожидалось, в начале каждой строки появились пробелы.
Теперь почистим данные:
И снова проверим:
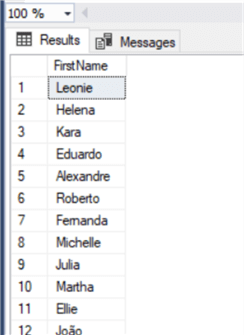
Мы можем сделать то же самое с RTRIM для удаления пробелов с правой стороны строки.
В SQL Server 2017 и выше мы можем удалить пробелы слева и справа одновременно с помощью функции TRIM.
Давайте снова испортим данные, и на этот раз добавим пробелы ко всем строкам таблицы:
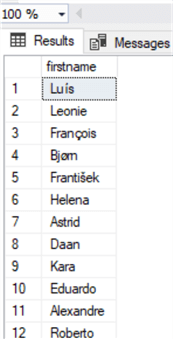
Посмотрим на наши данные:
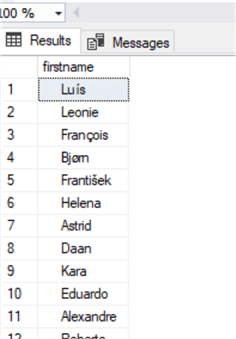
Почистим их с помощью TRIM:
Вот что получилось:
В Oracle мы имеем в точности те же самые функции. Давайте сначала испортим наш данные:
Заметьте, что поскольку у нас нет функции RIGHT в Oracle, мы должны использовать слегка обходной путь с привлечением функции LENGTH, которая возвращает значение длины в символах строки. Такая же функция также существует в SQL Server и PostgreSQL, хотя в SQL Server она называется LEN. Тогда, используя это число в качестве начальной точки для функции SUBSTR, мы можем вернуть последний символ строки.
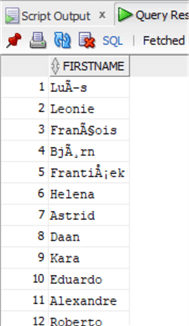
Посмотрим на данные:
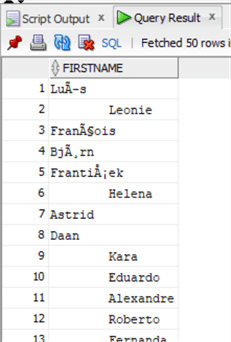
Теперь почистим их с помощью функции LTRIM:
Снова проверим данные:
Теперь давайте испортим данные для функции TRIM:
Получим такие данные:
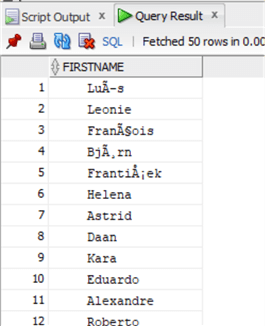
И снова почистим их:
Данные снова в порядке:
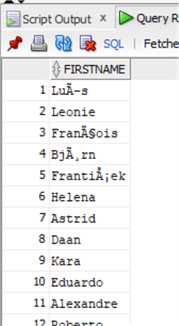
Заметим, что в Oracle есть отличие в использовании функций TRIM, LTRIM и RTRIM, которые могут применяться для удаления других заданных символов, а не только пробелов, как в SQL Server. Давайте сделаем пример, добавив некоторое символы в начале столбца с именем:
update chinook.Customer
set FirstName='... '||FirstName
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;
Проверим данные:
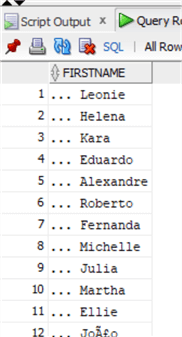
А теперь почистим их с помощью функции LTRIM:
Наши данные вернулись к предыдущему состоянию:
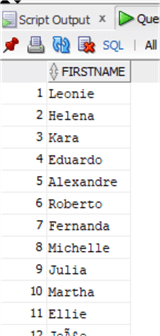
Обратите внимание, что все функции TRIM для каждого символа в наборе удаляют самые крайние справа или слева вхождения каждого из них в строке. Поэтому, как вы заметили, я указал только одну точку в LTRIM:
В PostgreSQL мы имеем те же самые функции, с тем же синтаскисом и смыслом.
Начнем с порчи данных:
Посмотрим, что у нас находится в таблице:
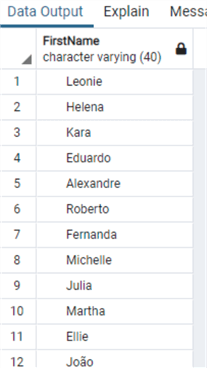
LTRIM и RTRIM работают точно так же, но здесь мы имеем функциональность, подобную Oracle, удаления не только пробелов, что принимается по умолчанию. Протестируем на тех же тестах, которые мы использовали в случае с Oracle:
Данные:
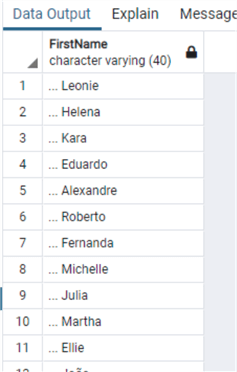
Теперь почистим данные:
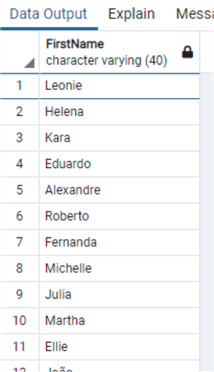
Другой полезной функцией манипуляции строками является REPLACE, которая, как предполагает имя, используется для замены заданной строки другой строкой.
Перейдем к примеру: представим, что нам нужно заменить в столбце Company слово "Inc." на "Co.".
Эту задачу легко решить с использованием функции REPLACE. Сначала посмотрим на данные:
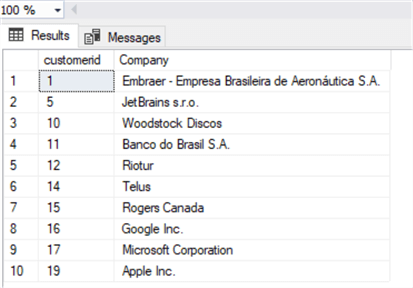
Теперь обновим их:
Мы можем увидеть изменения:
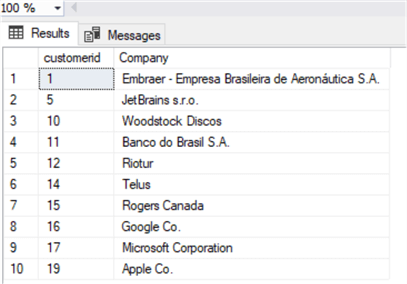
Аналогичная функциональность есть в Oracle, но сначала посмотрим на данные:
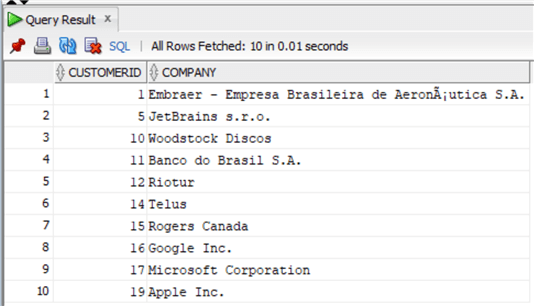
А теперь REPLACE:
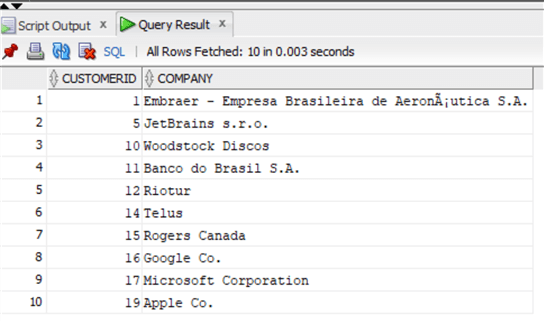
Теперь PostgreSQL:
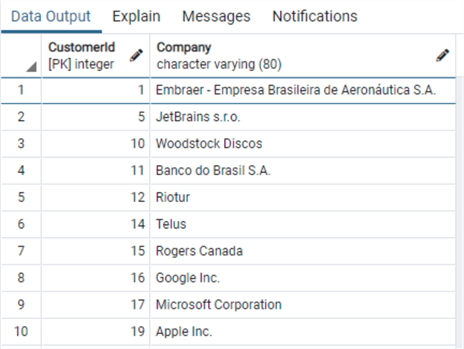
Обатите внимание, что мне потребовалось добавить ORDER BY, чтобы получить заказчиков в том же порядке, что и в других двух РСУБД.
Давайте используем REPLACE:
И последний взгляд на данные:
Строковые функции SQL для конкатенации строк
Начнем с самой простой и наиболее часто используемой операции - конкатенации двух (или большего числа) строк, и рассмотрим различные методы для ее выполнения.
SQL Server
Для конкатенации строк с помощью T-SQL в SQL Server имеется два основных метода, первый использует для конкатенации оператор +. Для примера соединим в один столбец имя и фамилию наших клиентов:
select FirstName + ' ' + LastName as CustomerName
from CustomerДелается легко с добавлением пробела посередине.
Тот же результат можно получить с помощью функции CONCAT, используя запятую как разделитель между параметрами функции:
select concat(FirstName,' ',LastName) as CustomerName
from CustomerOracle
В Oracle оператором конкатенации является двойной символ "|", т.е. ||:
select Firstname||' '||LastName as CustomerName
from chinook.customer;В Oracle функция CONCAT может использоваться только с двумя строками, поэтому следующий оператор не работает:
select concat(FirstName,' ',LastName) as CustomerName
from chinook.customer;Будет возвращена ошибка:
А так работает:
select concat(FirstName,LastName) as CustomerName
from chinook.customer;И результат:
PostgreSQL
В PostgreSQL оператор конкатенации такой же, как и в Oracle:
select "FirstName"||' '||"LastName" as "CustomerName"
from "Customer"А функция CONCAT работает в PostgreSQL, как в SQL Server:
select concat("FirstName",' ',"LastName") as "CustomerName"
from "Customer"Функции SQL для получения подстроки
Другой типичной операцией является извлечение некоторой части строки. Например, представим, что нам нужно извлечь инициал имени (Firstname) и дополнить его точкой с последующей фамилией (Lastname) для каждого заказчика.
SQL Server
В SQL Server мы используем функцию SUBSTRING:
select substring(FirstName,1,1) + '. ' + LastName as CustomerName
from CustomerФункция SUBSTRING принимает в качестве первого параметра строку, второго - начальную позицию подстроки и третьего - количество символов, которые нужно извлечь.
Тот же результат можно получить с помощью функции LEFT:
select left(FirstName,1) + '. ' + LastName as CustomerName
from CustomerФункция LEFT извлекает указанное число символов от начала строки (слева).
Имеется также и функция RIGHT. Предположим, что нам требуется получить всех заказчиков, чьи имена заканчиваются на гласную букву:
select customerid, FirstName + ' ' + LastName as CustomerName
from Customer
where right(FirstName,1) in ('a','e','i','o','u')Oracle
В Oracle эта функция похожа, хотя несколько отличается ее имя - SUBSTR:
select substr(FirstName,1,1)||'. '||LastName as CustomerName
from chinook.Customer;Остальное аналогично SQL Server.
К сожалению, в Oracle PL/SQL нет функций LEFT или RIGHT, поэтому мы будем всегда использовать SUBSTR для извлечения подстроки.
PostgreSQL
В PostgreSQL, как и в SQL Server, есть функция SUBSTRING:
select substring("FirstName",1,1)||'. '||"LastName" as "CustomerName"
from "Customer"Мы также можем использовать функцию LEFT:
select left("FirstName",1)||'. '||"LastName" as "CustomerName"
from "Customer"и использовать функцию RIGHT:
select "CustomerId", "FirstName"||' '||"LastName" as "CustomerName"
from "Customer"
where right("FirstName",1) in ('a','e','i','o','u')Удаление начальных и концевых пробелов в строке
Подобно функциям LEFT и RIGHT, имеются функции LTRIM and RTRIM, которые используются для удаления пробелов слева или справа заданной строки. Они часто используются для очистки данных, с чем я часто сталкивался при работе с ETL в хранилищах данных.
SQL Server
Сначала мы испортим данные добавлением некоторого числа пробелов в начале некоторых строк столбца FirstName:
update Customer
set FirstName = ' ' + FirstName
where right(FirstName,1) in ('a','e','i','o','u') Теперь посмотрим, как выглядят данные:
select FirstName
from Customer
where right(FirstName,1) in ('a','e','i','o','u') Как ожидалось, в начале каждой строки появились пробелы.
Теперь почистим данные:
update Customer
set FirstName = ltrim(FirstName)
where right(Firstname,1) in ('a','e','i','o','u') И снова проверим:
select FirstName
from Customer
where right(FirstName,1) in ('a','e','i','o','u') Мы можем сделать то же самое с RTRIM для удаления пробелов с правой стороны строки.
В SQL Server 2017 и выше мы можем удалить пробелы слева и справа одновременно с помощью функции TRIM.
Давайте снова испортим данные, и на этот раз добавим пробелы ко всем строкам таблицы:
update Customer
set FirstName= ' ' + FirstName + ' 'Посмотрим на наши данные:
select FirstName
from CustomerПочистим их с помощью TRIM:
update Customer
set FirstName = trim(FirstName)Вот что получилось:
select firstName
from CustomerOracle
В Oracle мы имеем в точности те же самые функции. Давайте сначала испортим наш данные:
update chinook.Customer
set FirstName=' '||FirstName
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;Заметьте, что поскольку у нас нет функции RIGHT в Oracle, мы должны использовать слегка обходной путь с привлечением функции LENGTH, которая возвращает значение длины в символах строки. Такая же функция также существует в SQL Server и PostgreSQL, хотя в SQL Server она называется LEN. Тогда, используя это число в качестве начальной точки для функции SUBSTR, мы можем вернуть последний символ строки.
Посмотрим на данные:
select firstname
from chinook.Customer;Теперь почистим их с помощью функции LTRIM:
update chinook.Customer
set FirstName=ltrim(FirstName)
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;Снова проверим данные:
select firstname
from chinook.Customer;Теперь давайте испортим данные для функции TRIM:
update chinook.Customer
set FirstName=' '||FirstName||' ';
commit;Получим такие данные:
select firstname
from chinook.Customer;И снова почистим их:
update chinook.Customer
set FirstName=trim(FirstName);
commit;Данные снова в порядке:
Заметим, что в Oracle есть отличие в использовании функций TRIM, LTRIM и RTRIM, которые могут применяться для удаления других заданных символов, а не только пробелов, как в SQL Server. Давайте сделаем пример, добавив некоторое символы в начале столбца с именем:
set FirstName='... '||FirstName
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;
Проверим данные:
select FirstName
from chinook.Customer
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');А теперь почистим их с помощью функции LTRIM:
update chinook.Customer
set FirstName=ltrim(FirstName,'. ')
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;Наши данные вернулись к предыдущему состоянию:
Обратите внимание, что все функции TRIM для каждого символа в наборе удаляют самые крайние справа или слева вхождения каждого из них в строке. Поэтому, как вы заметили, я указал только одну точку в LTRIM:
set FirstName=ltrim(FirstName,'. ') PostgreSQL
В PostgreSQL мы имеем те же самые функции, с тем же синтаскисом и смыслом.
Начнем с порчи данных:
update "Customer"
set "FirstName"=' '||"FirstName"
where right("FirstName",1) in ('a','e','i','o','u')Посмотрим, что у нас находится в таблице:
select "FirstName"
from "Customer"
where right("FirstName",1) in ('a','e','i','o','u')LTRIM и RTRIM работают точно так же, но здесь мы имеем функциональность, подобную Oracle, удаления не только пробелов, что принимается по умолчанию. Протестируем на тех же тестах, которые мы использовали в случае с Oracle:
update "Customer"
set "FirstName"='... '||("FirstName")
where right("FirstName",1) in ('a','e','i','o','u')Данные:
select "FirstName"
from "Customer"
where right("FirstName",1) in ('a','e','i','o','u')Теперь почистим данные:
update "Customer"
set "FirstName"=ltrim("FirstName", '. ')
where right("FirstName",1) in ('a','e','i','o','u')Замена текста в строке
Другой полезной функцией манипуляции строками является REPLACE, которая, как предполагает имя, используется для замены заданной строки другой строкой.
Перейдем к примеру: представим, что нам нужно заменить в столбце Company слово "Inc." на "Co.".
SQL Server
Эту задачу легко решить с использованием функции REPLACE. Сначала посмотрим на данные:
SELECT customerid, Company
FROM Customer
where Company is not nullТеперь обновим их:
update Customer
set Company = replace(Company, 'Inc.','Co.')
where Company is not nullМы можем увидеть изменения:
Oracle
Аналогичная функциональность есть в Oracle, но сначала посмотрим на данные:
SELECT customerid, Company
FROM chinook.Customer
where Company is not null;А теперь REPLACE:
update chinook.customer
set Company=replace(Company, 'Inc.','Co.')
where Company is not null;
commit;PostgreSQL
Теперь PostgreSQL:
SELECT "CustomerId", "Company"
FROM "Customer"
where "Company" is not null
order by "CustomerId"Обатите внимание, что мне потребовалось добавить ORDER BY, чтобы получить заказчиков в том же порядке, что и в других двух РСУБД.
Давайте используем REPLACE:
update "Customer"
set "Company"=replace("Company", 'Inc.','Co.')
where "Company" is not nullИ последний взгляд на данные:
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой