
Функция LAG в SQL Server
Пересказ статьи Mike Byrd. The SQL Server LAG Function
Функция LAG (как и многие другие оконные функции) впервые появилась в SQL Server 2012.
Майкрософт описывает функцию LAG как "доступ к данным из предыдущей строки в том же самом результирующем наборе без использования самосоединения. LAG обеспечивает доступ к строке с заданным физическим смещением, которая предшествует текущей строке." Оказалось, что это очень полезно для вычисления накопительных итогов и разности между строками.
В своём проекте я тестировал производительность запроса, который определял дату предыдущего заказа клиента и вычислял разность между предыдущей и текущей датами заказа, используя базу данных AdventureWorks2012Big. Эта база данных представляет собой базу данных AdventureWorks2012, модифицированную скриптом Jonathan Keyayias, который увеличивает число данных в таблице Sales.SalesOrderHeader с 31465 до 1290065 строк.
Приведенные ниже тесты выполнялись на следующей конфигурации:
Мой исходный запрос выглядел так
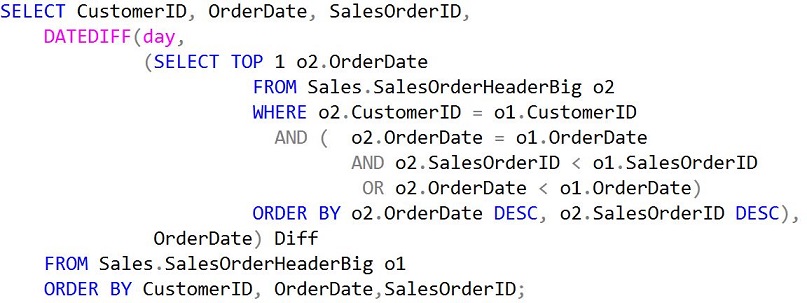
и при выполнении при оригинальных индексах AdventureWorks2012 (кластеризованном и некластеризованных) имел следующий план выполнения:

На плане имеется два отдельных сканирования кластеризованного индекса Sales.SalesOrderHeader.
После изучения этого плана я задумался и вспомнил о функции LAG. Тогда я переписал запрос следующим образом:
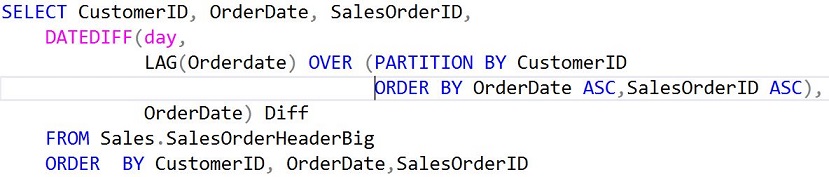
Полученные результаты были идентичны с результатами исходного запроса, но план стал значительно лучше; вот он:

Этот план имел только одно сканирование кластерного индекса (значительно меньше логических чтений) таблицы Sales.SalesOrderHeader.
Сравнение показателей производительности каждого из запросов дало следующий результат:
Время выполнения оригинального запроса составило около 28 секунд, в то время как с функцией LAG - 8 секунд. Улучшились также показатели логических чтений и времени процессора. Такое повышение производительности действительно может привлечь внимание менеджера, ожидающего отчет.
В своём проекте я тестировал производительность запроса, который определял дату предыдущего заказа клиента и вычислял разность между предыдущей и текущей датами заказа, используя базу данных AdventureWorks2012Big. Эта база данных представляет собой базу данных AdventureWorks2012, модифицированную скриптом Jonathan Keyayias, который увеличивает число данных в таблице Sales.SalesOrderHeader с 31465 до 1290065 строк.
Приведенные ниже тесты выполнялись на следующей конфигурации:
Microsoft SQL Server 2017 (RTM-CU12) (KB4464082) - 14.0.3045.24 (X64)
Oct 18 2018 23:11:05
Copyright (C) 2017 Microsoft Corporation
Developer Edition (64-bit) on Windows 10 Pro 10.0(Build 17134: )
Мой исходный запрос выглядел так
и при выполнении при оригинальных индексах AdventureWorks2012 (кластеризованном и некластеризованных) имел следующий план выполнения:
На плане имеется два отдельных сканирования кластеризованного индекса Sales.SalesOrderHeader.
После изучения этого плана я задумался и вспомнил о функции LAG. Тогда я переписал запрос следующим образом:
Полученные результаты были идентичны с результатами исходного запроса, но план стал значительно лучше; вот он:
Этот план имел только одно сканирование кластерного индекса (значительно меньше логических чтений) таблицы Sales.SalesOrderHeader.
Сравнение показателей производительности каждого из запросов дало следующий результат:
| Query 1 | Query 2 (LAG) | |
|---|---|---|
| Scan Count | 10 | 0 |
| Logical Reads | 59,842 | 30,022 страниц |
| CPU time | 123,827 | 5,499 мс |
| Elapsed time | 28,209 | 8,246 мс |
| Query Cost | 15,731.6 | 63.0 |
Время выполнения оригинального запроса составило около 28 секунд, в то время как с функцией LAG - 8 секунд. Улучшились также показатели логических чтений и времени процессора. Такое повышение производительности действительно может привлечь внимание менеджера, ожидающего отчет.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой