
Что такое статистика в SQL Server?
Пересказ статьи Matthew McGiffen. What are Statistics in SQL Server?
Статистика жизненно важна для SQL Server, позволяя ему находить наиболее эффективный способ выполнять ваши запросы. Здесь мы узнаем больше о том, что представляет собой статистика, и как она используется.
Оценка кардинального числа
Кардинальное число - это термин, пришедший из математики и означающий "число объектов в данном множестве или группе". В SQL мы постоянно имеем дело с множествами, поэтому это весьма актуальный термин, который в нашем контексте просто означает «количество строк».
Когда в запросе используется несколько таблиц, имеется множество способов, которые SQL Server может применить для физического доступа к данным, чтобы дать вам требуемый результат. Он может запросить и соединить таблицы в любом порядке, и он может использовать различные методы для сопоставления записей из разных таблиц, которые вы соединяете. Также необходимо знать сколько памяти выделить для операции - и, чтобы сделать это, необходимо иметь представление о количестве данных, генерируемых на каждом этапе обработки.
Многое из этого требует оценки кардинального числа, и SQL Server использует то, что называется объектами статистики, для выполнения таких вычислений.
Рассмотрим простой пример:
SELECT *
FROM Person.Person p
INNER JOIN Person.[Address] a
ON p.AddressId = a.AddressId
WHERE p.LastName = 'Smith'
AND a.City = 'Bristol'Когда дело доходит до получения результатов по этому запросу, имеется много способов, с помощью которых движок базы данных может к ним прийти. Например:
а) Он может найти все записи в таблице Person, у которых LastName равен Smith, просмотреть все их адреса и вернуть только тех, кто живет в Bristol.
б) Он может найти все адреса в Bristol, найти людей, связанных с каждым адресом, и вернуть только тех, чье имя Smith.
в) Он может собрать множество людей с именем Smith из таблицы People, собрать все адреса в Bristol и, только потом сопоставить записи в этих двух множествах.
Каждая из этих операций может быть наиболее эффективна в зависимости от числа записей, возвращаемых из каждой таблицы. Песть у нас имеется миллион людей с именем Smith, но только один адрес во всей нашей базе данных относится к Bristol (и пусть этот адрес действительно принадлежит человеку с именем Smith).
В первом методе я должен буду выбрать миллион Смитов, а затем проверять их адреса по одному, пока не найду того, кто живет в Bristol.
Хотя, если бы я использовал метод б), я бы сначала обнаружил один подходящий адрес, а затем просто нашел владельца этого адреса. Из этого надуманного примера ясно, что это было бы намного быстрей. Поэтому, если SQL Server знает наперед приблизительно сколько записей следует ожидать при выполнении каждой части запроса, можно надеяться, что он сделает правильный выбор того, как получать данные.
Но как определить, сколько строк будет возвращено без выполнения запроса?
Статистика
Тут на сцену выходят объекты статистики. SQL Server поддерживает в фоновом режиме данные, которые представляют собой гистограмму, показывающую распределение данных в определенных столбцах таблицы. Это происходит всякий раз, когда вы создаете индекс - статистика будет генерироваться на столбцах, для которых определен индекс, но и тогда, когда сервер считает, что это будет полезно. Поэтому, если SQL встречает предложение WHERE на Person.LastName - и этот столбец не включен в полезный индекс, SQL SQL может сгенерировать объект статистики, чтобы сообщать о распределении данных в этом столбце.
Я говорю "может", поскольку это фактически зависит от настроек вашего экземпляра SQL Server. Конфигурация сервера лежит за рамками этой статьи, но достаточно сказать, что вы можете позволить SQL автоматически создавать объекты статистики, или же нет. Вы можете позволить ему автоматически обновлять их, когда данные изменяются более чем на заданное пороговое значение, или не позволять. И вы можете указать, асинхронно или синхронно должна обновляться статистика - т.е. в последнем случае, если запрос определяет, что статистику требуется обновить, то он прервется и будет ждать, пока статистика не обновится, прежде чем продолжить выполнение.
Обычно рекомендуется включать автоматическое создание и обновление статистики и отключать асинхронное обновление.
Просмотр объектов статистики
Давайте бросим взгляд на некоторые актуальные объекты статистики и посмотрим, что они содержат. Есть пара способов сделать это, и первый - с помощью SSMS. Если посмотреть на ветку таблицы в браузере объектов, то вы увидите папку Statistics, которая содержит некоторые объекты статистики, имеющие отношение к этой таблице:
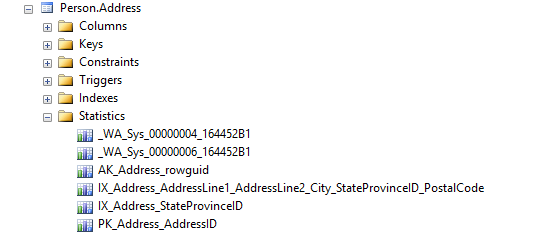
В данном примере некоторые объекты имеют дружественные имена, это статистика, которая связана с актуальный индексом, который был определен на таблице, и эти объекты имеют то же имя, что и индекс, например, IX_Address_StateProvinceId.
Видны также некоторые объекты с префиксом _WA_Sys и последующими случайными номерами. Это объекты статистики, которые SQL Server создал автоматически на столбцах, которые не имеют индексов - или, по крайней мере, они не были проиндексированы к тому времени, когда создавались объекты статистики.
Вы можете развернуть их двойным щелчком и посмотреть, что находится внутри:
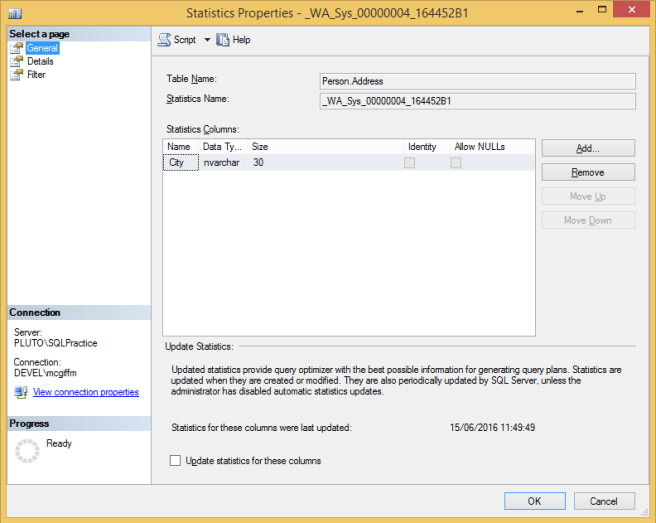
Открывается вкладка General (общие). Здесь указывается к какой таблице относится статистика и для каких столбцов. Имеются опции для добавления столбцов и изменения порядка - но вам никогда не следует этого делать - а также информация о том, когда последний раз обновлялась статистика, и чекбокс, если вы хотите сейчас обновить статистику.
На вкладке Details (подробно) содержится значительно больше информации:
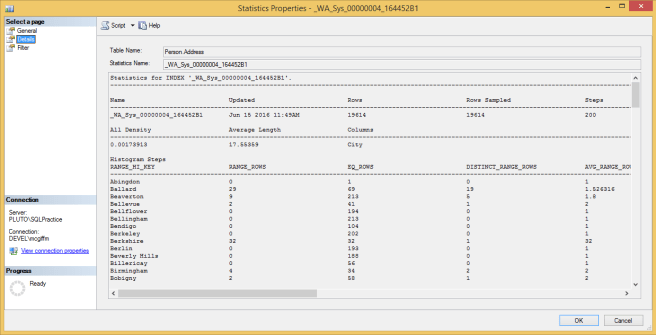
Я не нахожу, что это самый простой для работы формат отображения, поэтому вместо того, чтобы копаться в том, что это означает, давайте рассмотрим другой способ просмотра статистики, который достигается выполнением следующей команды:
DBCC SHOW_STATISTICS('Person.Address', '_WA_Sys_00000004_164452B1')Формат простой, вы лишь указываете таблицу, статистика которой вас интересует, и нужное вам имя объекта статистики. Вы увидите ту же информацию, которую получали двойным щелчком, но результаты выводятся в панель результатов, как и для любых других запросов, и представляются (я полагаю) значительно более простыми для чтения. Якобы вскоре в SQL Server ожидается третий способ для просмотра статистики, поскольку команды DBCC считаются немного «неуклюжими», но мы пока не знаем, как это будет выглядеть.
Вывод команды представляет собой три результирующих набора:

Данная статья является лишь введением в статистику, и обычно нет необходимости знать все, а лишь понимать основы. Поэтому давайте просто пробежимся по ключевым моментам информации, которую вы видите выше.
В первую очередь, в первом наборе записей, известном как...
Заголовок статистики (Stats Header)
Rows - это число строк в таблице.
Rows Sampled - сколько строк было выбрано для генерации статистики. SQL может генерировать или обновлять статистику, используя выборку, вместо чтения всех строк. В данном случае видно, что он фактически читает всю таблицу.
Steps (шаги) - если представить статистику как столбцовую диаграмму, то это число столбцов на диаграмме. Объекты статистики имеют максимум 200 шагов, поэтому, если вы имеете больше уникальных значений в столбце, то они будут сгруппированы в шаги.
Density - предполагается, что это вероятность того, что строка будет иметь определенное значение (вычисляется как 1/число различных значений в столбце). Согласно документации (Books Online) "Это значение плотности (Density) не используется оптимизатором запросов и отображается для обратной совместимости с версиями до SQL Server 2008". Я использую SQL 2012, и это число просто неверно, поэтому не используйте его...
Набор записей №2: вектор плотности
All Density - это точная версия статистики плотности, описанной выше. Поэтому вероятность того, что данная строка имеет указанное значение, составляет примерно 0.0017. Это немного меньше, чем один из 500. Я знаю, что в таблице имеется 575 различных городов, поэтому это имеет смысл. Иногда SQL будет использовать это значение при построении плана - если он знает, что вы собираетесь найти в этой таблице конкретный город (City), но не знает города при построении плана, тогда он может догадаться, что примерно одна пятисотая строк будет отвечать вашему критерию.
Average Length - средняя длина данных в этом столбце.
Columns - Имена всех столбцов, измеренных в этих объектах статистики. Вы можете иметь статистику по множеству столбцов, но я не буду объяснять это в данной статье. В нашем примере сообщается, что эта статистика основана на столбце "City".
Набор записей №3: гистограмма
Этот последний набор записей показывает распределение данных и то, что вы можете эффективно использовать для построения графика относительной частоты различных групп значений. Каждая строка представляет шаг - или столбик на диаграмме - и, как отмечалось выше, таких шагов не может быть больше 200. Как видно, объект статистики довольно прост даже для объемной таблицы.
RANGE_HI_KEY - это верхний предел каждого шага, поэтому каждый шаг содержит все значения больше чем RANGE_HI_KEY последнего шага, вплоть до этого значения включительно.
RANGE_ROWS - как много строк в таблице попадает в этот диапазон - не включая число, которое соответствуют самому RANGE_HI_KEY.
EQ_ROWS - количество строк, равное HI_KEY.
DISTINCT_RANGE_ROWS - количество различных значений в диапазоне, для которого есть данные (за исключением HI_KEY).
AVERAGE_RANGE_ROWS - среднее число строк для данного значения в диапазоне.
Это краткий обзор того, как SQL Server хранит ваши данные.
Алгоритмы, которые SQL затем использует для вычисления числа строк для данной части вашего запроса, довольно прозрачны, когда участвует только один столбец. Если мы посмотрим на вышеприведенный пример и, допустим, хотим найти строки, где город равен "Abingdon", статистика скажет нам, что имеется одна совпадающая строка, и это число SQL будет использовать для оценки кардинального числа. Когда значение лежит в диапазоне, то будет использоваться вычисление на основе AVERAGE_RANGE_ROWS.
Когда включается несколько столбцов, имеются более сложные алгоритмы и предположения, принимаемые в расчет. Если вам интересны детали, есть очень хороший источник по оценщику кардинального числа для SQL Server 2014, написанный Joe Sack.
Заключение
Основным выводом из этого должно быть понимание объема и границ информации о распределении ваших данных, которые SQL сохраняет в фоновом режиме.
Если при настройке запросов вы замечаете, что оценка числа строк не согласуется с фактическим числом, это может заставить SQL построить плохой план для запроса. В этих случаях вы можете захотеть выяснить, что происходит со статистикой.
Возможно ваш запрос написан так, что он не может эффективно использовать статистику; таким примером может служить случай, когда вы сохраняете постоянные значения в переменных, а затем запрос использует эти переменные в предложении WHERE. Тогда SQL будет выполнять оптимизацию на основе средних, а не ваших фактических значений.
Возможно план основывается на одном значении данных, которое очень сильно отличается о текущего значения, используемого в запросе. Например, когда вы первый раз выполнили хранимую процедуру, план был построен на основе переданных параметров. Эти параметры могли иметь кардинальное число, которое довольно сильно отличается от тех, которые использовались в последующих запусках.
Возможно статистика устарела и требуется обновление. Статистика обновляется, когда меняется приблизительно 20% данных в таблице. Для больших таблиц это может быть слишком большой порог, поэтому текущая статистика не всегда содержит хорошую информацию о тех данных, которые вы запрашиваете.
А может быть SQL справляется как нельзя лучше при имеющейся информации. Тогда вам потребуется поработать над тем, чтобы помочь ему.
Вот несколько свежих статей о статистике, которые вы можете счесть полезными:
Когда обновляется статистика?
Rowcount estimates when there are no Statistics
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой