
Что на самом деле означает толщина стрелки в плане запроса
Пересказ статьи Brent Ozar. What the Arrow Sizes in Query Plans Really Mean
Несколько ранее я просил вас предположить, что означают стрелки в предварительном и актуальном планах. Я просил вас догадаться без проведения каких-либо исследований. И вот результаты:
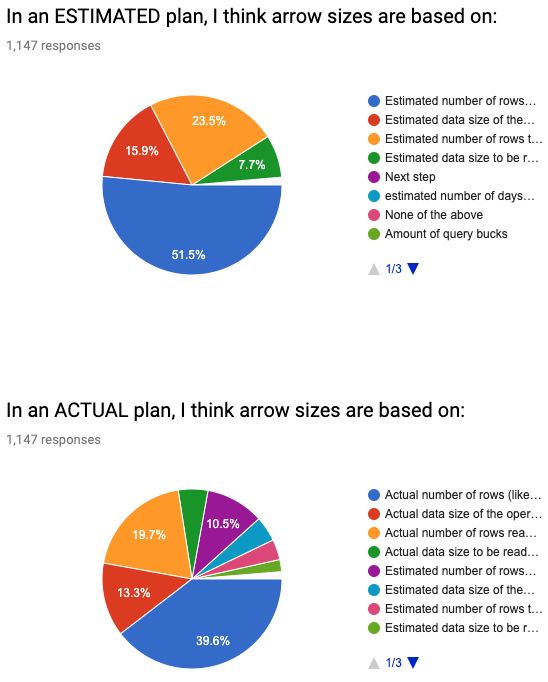
Множество различных вариантов, и я понимаю, что вас смущает. Books Online не проясняет ситуацию, а объяснения в интернет покрывают всю карту:
- Simple Talk: "Толщина стрелки отражает количество передаваемых данных, чем толще, тем больше строк."
- TuneUpSQL.com также отбрасывает размер столбца: "толщина стрелки базируется на числе строк, а не размере данных на диске. Например, 100 битовых строк дадут более толстую стрелку, чем 5 строк в 5000 бит каждая."
- SQLShack.com идет еще дальше, используя размер стрелки в анализе производительности: "Толщина стрелки может быть также индикатором проблем с производительностью. Например, если в начале плана присутствуют толстые стрелки, т.е. число передаваемых строк по этим стрелкам велико, а число строк, передаваемых по последней стрелке к оператору SELECT и возвращаемых запросом мало, то оператор сканирования таблицы применен некорректно или следует поправить индекс."
- Однако Hugo Kornelis на SQLServerFast.com дает правильный намек: "Видите ли, источником каждого плана выполнения является большой кусок XML (который, в свою очередь, является представлением внутренних структур, которые использует SQL Server). А в этом XML нет ничего, что представляло бы эти стрелки."
Это означает, что вся концепция стрелки зависит от приложениий визуализации - подобных SQL Server Management Studio (SSMS), Azure Data Studio, SentryOne Plan Explorer и других инструментов визуализации третьих фирм. Они принимают решение относительно размеров стрелки - здесь нет стандарта.
Алгоритм размера стрелки в SSMS вернулся к первоначальному в SQL Server Management Studio 17, но большинство пользователей этого не заметило. Теперь размер не опирается на чтения строк, чтения столбцов, общем размере данных или что-то еще, что связано с перемещением данных от одного оператора к следующему.
Давайте проверим, как они строятся в SSMS.
Для демонстрации мы создадим пару таблиц с 100К строк в каждой, но одна будет иметь крошечное строковое поле, а другая - большое (что означает чтение большего числа страниц при сканировании):
CREATE TABLE dbo.Narrow (Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, String VARCHAR(8));
INSERT INTO dbo.Narrow(String)
SELECT TOP 100000 'Common'
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2;
INSERT INTO dbo.Narrow(String)
VALUES ('Rare');
GO
CREATE STATISTICS STAT_String ON dbo.Narrow(String) WITH FULLSCAN;
CREATE TABLE dbo.Wide (Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, String VARCHAR(8000));
INSERT INTO dbo.Wide(String)
SELECT TOP 100000 REPLICATE('X', 8000)
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2;
INSERT INTO dbo.Wide(String)
VALUES ('Rare');
GO
CREATE STATISTICS STAT_String ON dbo.Wide(String) WITH FULLSCAN;
GO
Теперь давайте выполним запрос к таблицам, специально используя UNION ALL, который дважды сканирует таблицы, но производит различное число строк:
SELECT String
FROM dbo.Narrow n / Читаем всю крошечную таблицу, производя 100K коротких строк /
UNION ALL
SELECT String
FROM dbo.Wide w / Читаем всю большую таблицу, производя 100K длинных строк /
UNION ALL
SELECT String
FROM dbo.Narrow n
WHERE String = 'Rare' / Читаем всю крошечную таблицу, производим 1 строку /
UNION ALL
SELECT String
FROM dbo.Wide w
WHERE String = 'Rare' / Читаем всю большую таблицу, производим 1K строку /
В предварительном плане величина стрелки представляет число строк на выходе (OUTPUT) оператора.
Хорошие новости! Примерно половина из вас оказались правы! (И половина ошиблась, но стакан наполовину полон.) Вот предварительный план выполнения:
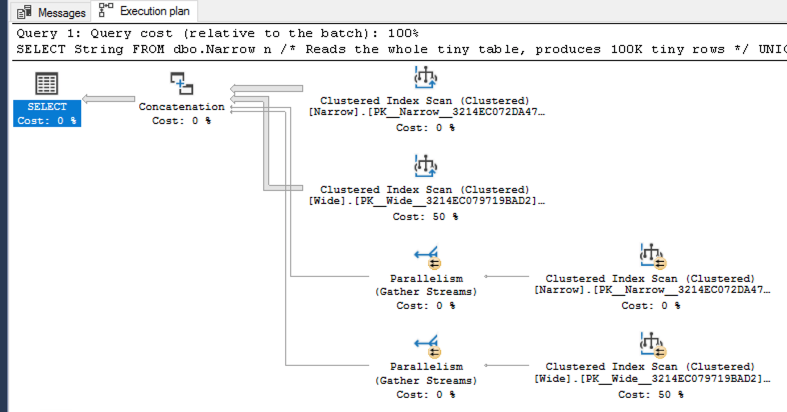
В предварительном плане размеры стрелок определяются числом строк на выходе оператора. Статистика, которую мы создали вручную, означает, что SQL Server точно оценил, что только 1 строка будет на выходе, когда мы применяем фильтр String = ‘Rare’.
Здесь стрелки для предварительного плана не имеют никакого отношения к размеру данных - обратите внимание, что две верхних стрелки имеют одинаковый размер, хотя один оператор производит 100К широких строк, а другой - 100К узких.
В актуальном плане это число строк, которые читаются оператором.
Хорошие новости: 20% из вас в курсе знаний SSMS!
Отличные новости: 80% из вас нужна эта статья, т.е. мои инстинкты меня не подвели, чтобы её написать. Теперь давайте сделаем это:
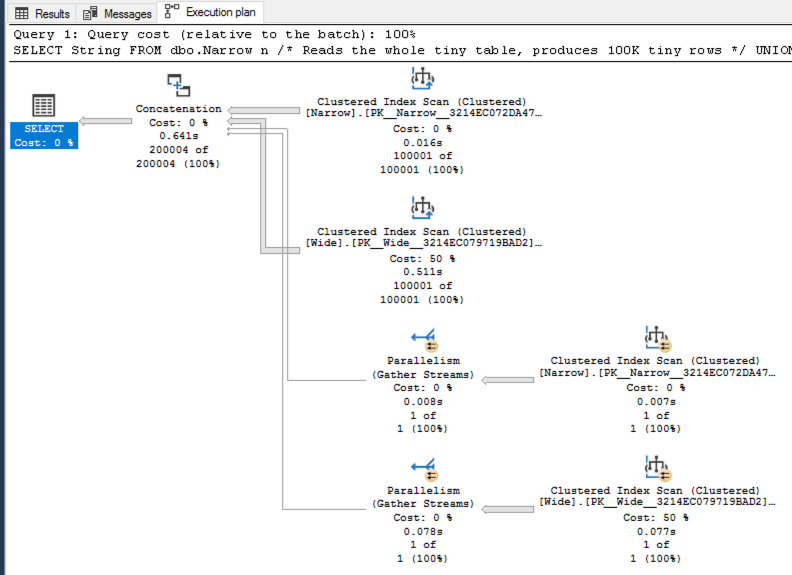
Обратите внимание, что стрелки, исходящие непосредственно от каждого сканирования кластеризованного индекса имеют одинаковый размер - несмотря на то, что они производят разное число строк - поскольку в актуальном плане размеры стрелок зависят от числа строк, прочитанных этим оператором. (И вот почему стрелки на выходе оператора, собирающего параллельные потоки, такие тонкие - этот оператор должен обработать только одну строку.)
Это противоречит интуиции, поскольку вы предполагали, что размеры стрелок, выходящих из оператора, должны представлять данные, выходящие из этого оператора - но это не так. Размеры стрелок зависят от работы, проделанной этим оператором.
Документация по этому вопросу весьма скудная - наиболее близкое к официальной документации изложение я нашел в баг репорте SSMS 17.4, где Майкрософт пишет:
Привет, Хьюго, теперь толщина принимает во внимание фактические строки, прочитанные оператором, если такие есть, что, согласно предыдущему обращению сообщества пользователей, является более точной мерой веса оператора в плане. И это облегчает определение проблемных мест. В некоторых случаях проблемный оператор имел самую узкую стрелку, когда фактическое число строк равнялось нулю, но число прочитанных строк было >0.
Вот почему я люблю Plan Explorer.
SentryOne Plan Explorer является свободно распространяемым инструментом визуализации и анализа плана выполнения, который конфигурирует все на свете, включая размеры стрелок. Когда вы рассматриваете план, щелкните правой кнопкой на нем и выберите предпочитаемую толщину линий (и вашу стоимость тоже, например, если вы хотите, чтобы процент стоимости определялся затратами процессора или чтениями):
<
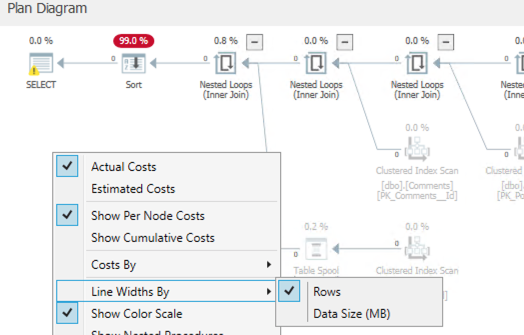
Кто из них "прав", SSMS или Plan Explorer? Ну, я бы сказал, что они оба правы - если вы понимаете смысл метрик, которые применяются для измерений.
Не расстраивайтесь, если вы ошибались. Я не был уверен, что предполагаемые планы делали то же самое (чтение строк), что и актуальные, поэтому сначала провел исследование, а затем сообщил об этом в блоге.
Лучший способ узнать больше о SQL Server - это закатать рукава и начать работу. Я буду ждать ваших открытий!
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой