
Что можно и чего нельзя делать с помощью SQL VARCHAR для более быстрых баз данных
Пересказ статьи Edwin Sanchez. The Best SQL VARCHAR Do’s and Don’ts for Faster Databases
Мы собираемся глубоко изучить SQL VARCHAR, тип данных, который имеет дело со строками.
VARCHAR является лишь одним из строковых типов в SQL. Чем он отличается от остальных?
Что такое SQL VARCHAR? (с примерами)
VARCHAR - это строковый или символьный тип данных переменного размера. Вы можете хранить тут буквы, числа и символы. Начиная с SQL Server 2019, вы можете использовать полный диапазон символов Unicode при использовании коллации с поддержкой UTF-8.
Вы можете объявить или переменные этого типа, используя VARCHAR[(n)], где n обозначает размер строки в байтах. n меняется в диапазоне от 1 до 8000. Это множество символьных данных. Более того, вы можете объявить тип, используя VARCHAR(MAX), если вам требуются гигантские строки до 2Гб. Этого достаточно, чтобы сохранить ваш список секретов и личных вещей в дневнике! Однако следует отметить, что этот тип можно объявить без указания размера, и тогда по умолчанию принимается 1.
Давайте возьмем пример.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie 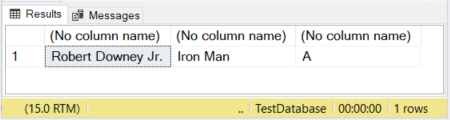
На рисунке первые два столбца имеют заданный размер. Для третьего столбца размер не указан. Поэтому слово “Avengers” усекается, поскольку в этом случае по умолчанию принимается 1 символ.
Теперь давайте попробуем что-нибудь огромное. Но отметьте, что выполнение этого запроса займет некоторое время - 23 секунды на моем ноутбуке.
-- Это займет время
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)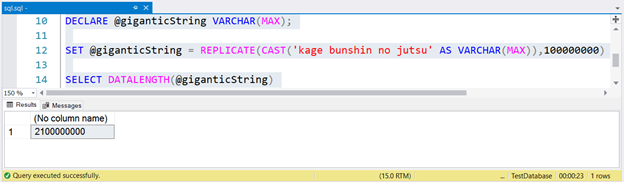
Для генерации огромных строк мы реплицировали kage bunshin no jutsu 100 миллионов раз. Обратите внимание на CAST внутри REPLICATE. Если вы не преобразуете строковое выражение к VARCHAR(MAX), результат будет усечен только до 8000 символов.
Но что представляет собой SQL VARCHAR в сравнении с другими строковыми типами данных?
CHAR против VARCHAR
В отличие от VARCHAR, CHAR является символьным типом данных фиксированной длины. Вне зависимости от того, большое или малое значение вы поместите в переменную типа CHAR, окончательный размер будет равен размеру переменной. Проверьте следующие сравнения.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue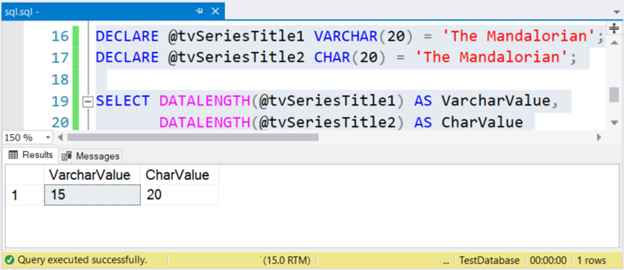
Размер строки “The Mandalorian” - 15 символов. Поэтому столбец VarcharValue правильно отображает его. Но CharValue сохраняет размер 20, добавляя 5 пробелов справа.
NVARCHAR против VARCHAR
Две основные вещи приходят на ум, когда сравниваются эти типы данных.
Во-первых, это размер в байтах. Каждый символ в NVARCHAR имеет удвоенный размер по сравнению с VARCHAR. Диапазон значений NVARCHAR(n) - от 1 только до 4000.
Второе, это символы, которые могут тут храниться. NVARCHAR может хранить мультиязычные символы, например, корейские, японские, арабские и т.д. Если вы планируете хранить корейский K-Pop в своей базе данных, этот тип данных вам подойдет.
Рассмотрим пример. Мы собираемся использовать группу K-Pop 세븐틴 или Seventeen (17) по-английски.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]Вышеприведенный код выведет строковое значение, его размер в байтах и число символов. Если эти символы не являются Юникодом, число символов равно размеру в байтах. Но не в этом случае. Посмотрите рисунок ниже.
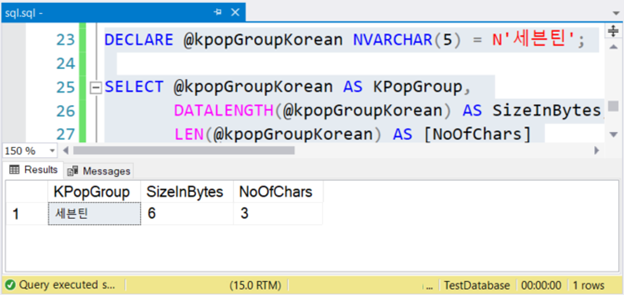
Видите? Если NVARCHAR содержит 3 символа, размер в байтах вдвое больше. Это также справедливо, если вы используете английские символы.
А как насчет NCHAR? NCHAR является альтернативой CHAR для символов Юникод.
SQL VARCHAR с поддержкой UTF-8
VARCHAR с поддержкой UTF-8 возможна на уровне сервера, уровне базы данных или уровне столбца таблицы при изменении информации о коллации. Используемая коллация должна поддерживать UTF-8.
Коллация сервера
На рис.5 представлено окно SQL Server Management Studio, где показана коллация сервера.

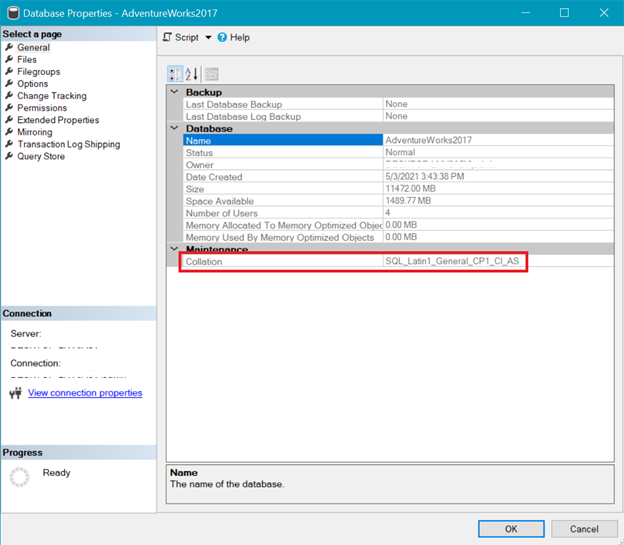
Коллация базы данных
А на рис.6 показаны коллация базы данных AdventureWorks.
Коллация столбца таблицы
Как серверная, так и коллация базы данных показали, что UTF-8 не поддерживается. Строка коллации должна иметь суффикс _UTF8 для поддержки UTF-8. Но, тем не менее, вы можете использовать поддержку UTF-8 на уровне столбца таблицы. Посмотрите пример.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)Код выше применяет коллацию Latin1_General_100_BIN2_UTF8 для столбца KoreanName. Хотя это VARCHAR, а не NVARCHAR, этот столбец будет принимать символы корейского языка. Давайте вставим несколько записей и просмотрим их.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
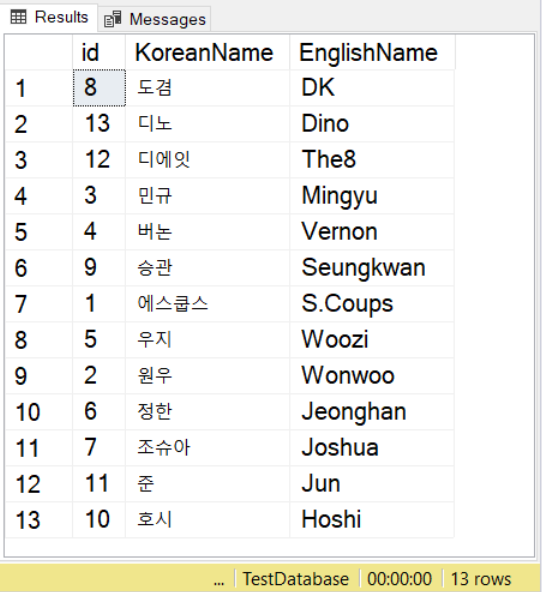
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8Мы используем имена из K-pop группы SEVENTEEN, используя корейские и английские варианты. Обратите внимание, что для корейских символов вы все же должны использовать префикс значения N, как и для значений NVARCHAR.
Затем, используя SELECT с ORDER BY вы также можете использовать коллацию. Вы можете это видеть на примере выше. Результат будет следовать правилам сортировки указанной коллации.
Хранение VARCHAR с поддержкой UTF-8
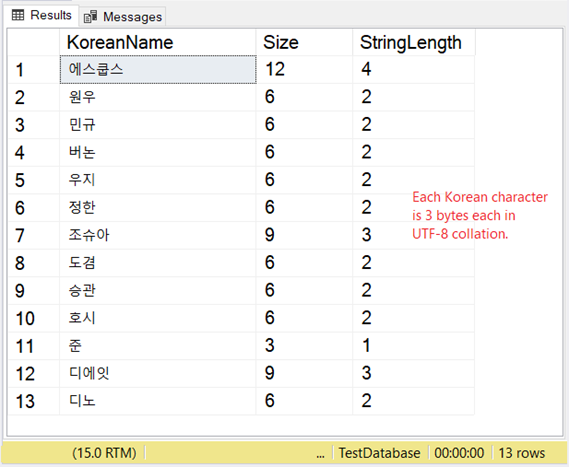
Но как хранятся эти символы? Если вы ожидаете 2 байта на символ, вас ждет сюрприз. Посмотрите рисунок 8.
Поэтому, если для вас большое значение имеет хранилище, рассмотрите таблицу ниже, когда используется VARCHAR с поддержкой UTF-8.
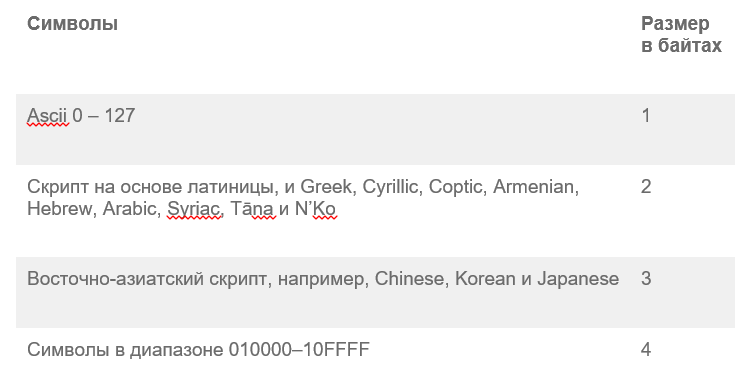
Таблица 1. Размер в байтах символов в VARCHAR с поддержкой UTF-8.
Наш корейский пример является восточно-азиатским скриптом, поэтому он содержит 3 байта на символ.
Теперь, когда мы описали и сравнили VARCHAR с другими строковыми типами данных, рассмотрим, что следует и чего не следует делать.
Делать при использовании SQL VARCHAR
1. Задавать размер
Что может пойти не так, если не указывать размер?
Усечение строки
Если вы ленитесь указывать размер, может произойти усечение строки. Вы уже видели пример этого выше.
Влияние на хранение и производительность
Другой вопрос - это хранение и производительность. Вам нужно устанавливать правильный размер для ваших данных, не больше. Но как это узнать? Чтобы избежать усечения в будущем, вы могли бы просто установить наибольший размер. Это VARCHAR(8000) или даже VARCHAR(MAX). И 2 байта будут сохранены как есть. То же самое с 2Гб. Это имеет значение?
Ответ на этот вопрос приводит нас к концепции хранения данных в SQL Server. У меня есть другая статья, подробно объясняющая это с примерами и иллюстрациями.
Вкратце, данные хранятся на 8-килобайтных страницах. Когда строка данных превышает этот размер, SQL Server перемещает её на другую единицу распределения страниц, называемую ROW_OVERFLOW_DATA.
Предположим, что у нас есть 2-х байтовые данные типа VARCHAR, которые могут поместиться на исходной единице распределения страниц. Когда вы сохраняете строку свыше 8000 байт, данные будут перемещаться на страницу переполнения строк. Затем снова уменьшите её размер, и она будет перемещена обратно на исходную страницу. Перемещение взад и вперед вызывает множество операций ввода/вывода, что становится узким местом в производительности. Извлечение её из двух страниц вместо одной также требует лишних операций ввода/вывода.
Другая причина - индексирование. VARCHAR(MAX) - это большое "НЕТ" в качестве ключа индекса. Между тем, VARCHAR(8000) превышает максимальный размер ключа индекса. Это 1700 байт для некластеризованных индексов и 900 байт - для кластеризованных индексов.
Влияние на преобразование данных
Есть еще один момент: преобразование данных. Попробуйте применить CAST без размера, как показано в коде ниже.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength Этот код выполнит преобразование даты/времени с информацией часового пояса к VARCHAR.

Итак, если мы поленимся указать размер при использовании CAST или CONVERT, результат ограничивается только 30-ю символами.
Как насчет преобразования NVARCHAR к VARCHAR с поддержкой UTF-8? Ниже будет дано подробное объяснение, так что продолжайте чтение.
2. Используйте VARCHAR, если размер строки варьируется в широких пределах
Имена в базе данных AdventureWorks меняются по размеру. Одно из самых коротких имен - Min Su, в то время как самое длинное - Osarumwense Uwaifiokun Agbonile. т.е. между 6 и 31 символами, включая пробелы. Давайте импортируем эти имена в 2 таблицы и сравним VARCHAR и CHAR.
-- Таблица, использующая VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Таблица, использующая CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GOКакой вариант из 2 лучше? Давайте посмотрим на логические чтения с помощью нижеприведенного кода и проверим вывод STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF Логические чтения:
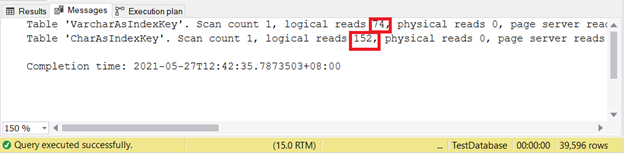
Чем меньше логических чтений, тем лучше. Здесь столбец CHAR использует их более чем в два раза больше по сравнению с VARCHAR. Таким образом, в этом примере побеждает VARCHAR.
3. Используйте VARCHAR в качестве ключа индекса вместо CHAR, когда значения варьируются по размеру
Что случится, если использовать их в качестве ключей индекса? Будет ли CHAR лучше, чем VARCHAR? Давайте использовать данные из предыдущего раздела, и ответим на этот вопрос.
Мы выполним запрос к тем же данным и проверим число логических чтений. В этом примере фильтр использует ключ индекса.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFFЛогические чтения:
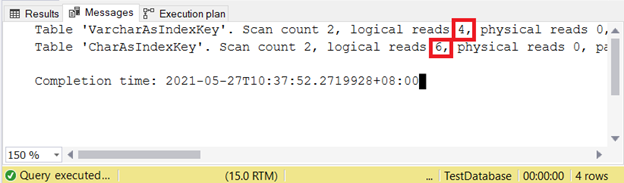
Рис.11. Запрос к таблице, использующей ключ индекса типа CHAR требует больше логических чтений, чем при использовании VARCHAR
Следовательно, ключи индекса типа VARCHAR лучше, чем ключи индекса типа CHAR, когда ключ имеет переменный размер. А как для INSERT и UPDATE, которые будут изменять индексные записи?
При использовании INSERT и UPDATE
Давайте протестируем 2 случая, а затем проверим число логических чтений, как мы обычно делаем.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFFЛогические чтения:
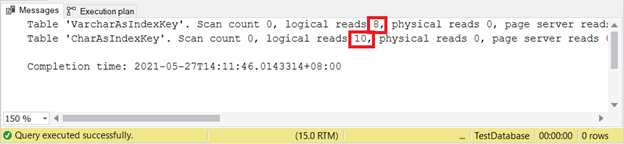
VARCHAR все еще лучше при вставке записей. А как для UPDATE?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFFЛогические чтения:
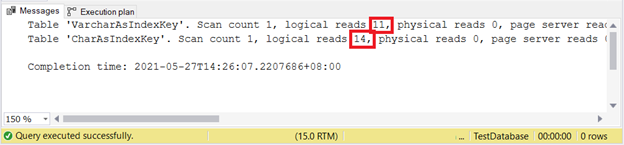
Похоже, что VARCHAR опять побеждает.
В конце концов, он побеждает в нашем тесте, хотя и небольшого размера. У вас есть более крупный тестовый пример, который доказывает обратное?
4. Рассмотрите VARCHAR с поддержкой UTF-8 для мультиязычных данных (SQL Server 2019+)
Если в вашей таблице имеется смесь символов Юникод и не Юникод, вы можете рассмотреть использование VARCHAR с поддержкой UTF-8 вместо NVARCHAR Если бОльшая часть символов находится в диапазоне ASCII 0 - 127, это позволит сэкономить пространство по сравнению с использованием NVARCHAR.
Давайте выполним сравнение, чтобы увидеть что я имею в виду.
От NVARCHAR к VARCHAR с поддержкой UTF-8
Вы уже перевели свои базы данных на SQL Server 2019? Планируете ли вы перевести строковые данные на коллацию UTF-8? Наш пример будет использовать смесь японских и неяпонских символов, чтобы вы получили представление.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8Теперь проверим размер в байтах этих двух значений:

Сюрприз! При использовании NVARCHAR размер составляет 30 байт. Т.е. в 15 раз больше, чем 2 символа. Но при конвертациив в VARCHAR с поддержкой UTF-8 размер составляет только 27 байт. Почему 27? Посмотрите, как это вычисляется.

Таким образом, 9 символов имеют по одному байту каждый. Это интересно, поскольку при NVARCHAR английские буквы также занимают по 2 байта. Остальные японские символы занимают по 3 байта каждый.
Если бы все символы были японскими, то 15-символьная строка была бы 45 байтов длиной и так же занимала бы максимальный размер столбца VarcharUTF8. Обратите внимание, что размер столбца NVarcharValue меньше, чем размер VarcharUTF8.
Размеры могут быть не равны при преобразовании из NVARCHAR, или данные могут не поместиться. Вы можете обратиться к предыдущей таблице 1.
Рассмотрите влияние на размер при преобразовании NVARCHAR в VARCHAR с поддержкой UTF-8.
Что не следует делать при использовании SQL VARCHAR
1. Если размер строки фиксированный и не допускает NULL-значений, используйте CHAR вместо VARCHAR
Общее практическое правило гласит: когда требуется строка фиксированного размера, используйте CHAR. Я следую этому правилу, когда требованием к данным является дополнение строки пробелами справа. В противном случае, я использую VARCHAR. У меня есть несколько случаев применения, когда необходимо получить дамп строк фиксированной длины без разделителей в текстовом файле для передачи клиенту.
Кроме того, я использую столбцы типа CHAR, только если столбцы не будут содержать NULL. Почему? Поскольку размер столбцов CHAR при наличии NULL равен размеру столбца. Да, когда VARCHAR есть NULL, размер равен 1 вне зависимости от того, какой размер был определен. Выполните код ниже, чтобы убедиться в этом.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize2. Не используйте VARCHAR(n), если n будет превышать 8000 байт. Используйте вместо этого VARCHAR(MAX)
Есть ли у вас строка, которая превышает 8000 байт? Самое время использовать VARCHAR(MAX). Но для самых общих представлений данных, например, имен и адресов, VARCHAR(MAX) - это перебор и влияние на производительность. В моем профессиональной деятельности я не помню требования, которое привело бы к использованию VARCHAR(MAX).
3. При использовании мультиязычных символов в SQL Server 2017 и ниже. Используйте в этом случае NVARCHAR
Это очевидный выбор, если вы еще используете SQL Server 2017 и ниже.
Выводы
Тип данных VARCHAR хорошо послужил нам во многих аспектах. Я использовал его, начиная с SQL Server 7. Увы, иногда мы все еще делаем плохой выбор. Здесь мы определили и сравнили SQL VARCHAR с другими строковыми типами данных на примерах. Вот что следует делать и чего следует избегать, чтобы сделать базы данных быстрей:
Делать:
- Определять размер n в VARCHAR[(n)], хотя этот параметр не является обязательным.
- Используйте его, когда размер строки значительно варьируется.
- Рассмотрите столбцы VARCHAR в качестве ключей индекса вместо CHAR.
- Если вы уже используете SQL Server 2019, рассмотрите вариант VARCHAR для мультиязычных строк с поддержкой UTF-8.
Не делать:
- Не используйте VARCHAR, когда размер строки фиксирован и не допускает NULL-значений.
- Не используйте VARCHAR(n), когда размер строки будет превышать 8000 байт.
- Не используйте VARCHAR для мультиязычных данных, если используется SQL Server 2017 и ранее.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой