
3 лучших совета для написания более быстрых представлений SQL
Пересказ статьи Edwin Sanchez. Top 3 Tips You Need to Know to Write Faster SQL Views
Друг или враг? Представления SQL Server были предметом жарких дебатов, когда я только начал использовать SQL Server. Говорилось, что это плохо, поскольку медленно. Но как обстоят дела сейчас?
Находитесь ли вы в том же состоянии, в котором я был много лет назад? Тогда присоединяйтесь к обсуждению, чтобы выяснить реальное положение дел с представлениями SQL и быть способными написать их максимально быстрыми.
Представления SQL - это виртуальные таблицы. Записи в представлении являются результатом выполнения запроса, лежащего в их определении. Всякий раз, когда обновляются базовые таблицы, используемые в представлении, представление обновляется также. В некоторых случаях вы можете даже использовать операторы UPDATE, INSERT, DELETE с представлением, как будто это таблица. Хотя я не пытался сам это делать.
Как и для таблицы, вы можете использовать CREATE, ALTER или DROP с представлением. Вы можете даже создать индекс при некоторых ограничениях.
Замечу, что в примерах я использую SQL Server 2019.
Начнем с основ.
Для чего предназначены представления SQL?
Это ключевой момент. Если использовать его как молоток вместо отвертки, забудьте о более быстрых представлениях SQL. Сначала перечислим варианты правильного использования:
Когда НЕ использовать представления SQL?
Неправильное использование представлений, если допускается, сделает неясной настоящую причину, зачем вы создаете представления. Как будет показано ниже, реальные преимущества перевешивают предполагаемые выгоды от неправильного использования.
Давайте проверим пример от Microsoft. Это представление vEmployee из AdventureWorks. Вот код:
Цель этого представления - сфокусироваться на основной информации о сотрудниках. Если потребуется, отдел кадров может отобразить её на веб-странице. Было ли оно повторно использовано в других представлениях?
Выясним это:
Если вы видите другое представление, зависящее от этого, которое, в свою очередь, зависит от другого представления, то Microsoft дало бы нам плохой пример. Но здесь нет других зависимостей от данного представления.
Пойдем дальше.
Когда SQL Server обрабатывает SELECT от представления, он оценивает код в представлении ПРЕЖДЕ предложения WHERE или любого соединения во внешнем запросе. Когда соединяется большое число таблиц, это будет медленней по сравнению с SELECT с базовыми таблицами при тех же результатах.
По крайней мере, это то, что мне говорили, когда я начинал использовать SQL. Миф или нет, есть только один способ это проверить. Вернемся к практическому примеру.
Microsoft не оставило нас бесконечно дебатировать в темноте. Мы имеем инструменты, позволяющие наблюдать, как работают запросы, такие как STATISTICS IO (статистика ввода/вывода) и Actual Execution Plan (фактический план выполнения). Мы будем использовать их в наших примерах. Вот первый из них.
Чтобы увидеть, что происходит, когда SQL Server обрабатывает представление, рассмотрим фактический план выполнения на рис.1. Мы сравним его с кодом в CREATE VIEW для vEmployee в предыдущем разделе.
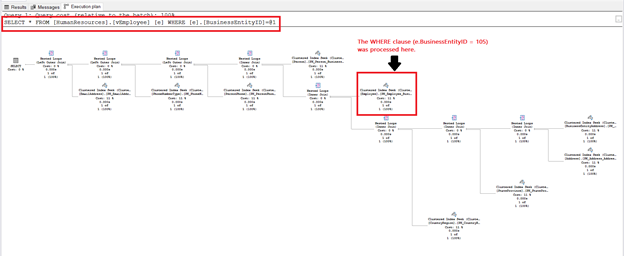
Рис.1. План выполнения запроса с представлением SQL. Предложение WHERE не обрабатывалось последним.
Как видно, первыми SQL Server обрабатывает узлы, использующие INNER JOIN. Затем обработка переходит к соединениям LEFT OUTER JOIN.
Поскольку мы нигде не находим узла Filter для предложения WHERE, он должен быть в одном из тех узлов. Если вы раскроете свойства всех узлов, то увидите предложение WHERE, обрабатываемое в таблице Employee. Я обвел его рамкой на Рис.1. В доказательство посмотрите Рис.2 со свойствами этого узла:
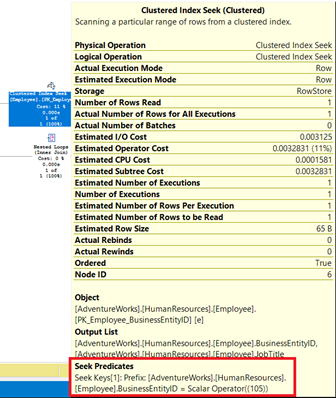
Рис.2. Свойства узла таблицы Employee, показывающие использование Seek Predicate (поисковый предикат). Это также предложение WHERE e.BusinessEntityID = 105.
Итак, должен ли оператор SELECT в представлении vEmployee оцениваться или обрабатываться ДО применения предложения WHERE? План выполнения показывает, что не должен. Если это было так, то он должен появиться в ближайшем узле SELECT.
То, что мне говорили, было мифом. Я избегал чего-то хорошего из-за неправильного понимания использования представлений SQL.
Теперь, когда мы знаем как SQL Server обрабатывает SELECT из представления, остается вопрос: это медленнее, чем без использования представления?
Во-первых, нам нужно извлечь оператор SELECT из представления vEmployee и произвести тот же результат, который мы имели при использовании представления. В коде ниже показано то же самое предложение WHERE:
Затем мы смотрим статистику ввода/вывода и сравниваем планы. Как много ресурсов потребуется запросу из представления по сравнению с запросом из базовых таблиц? Посмотрите Рис.3.
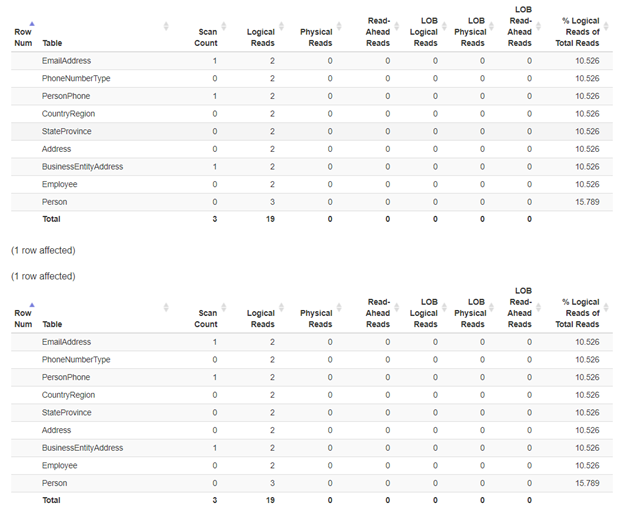
Рис.3. STATISTICS IO для запроса из представления и запроса из базовых таблиц. Для обоих запросов совпадает количество логических чтений. (Результаты STATISTICS IO отформатированы с помощью http://statisticsparser.com/)
Здесь для запросов из представления или базовых таблиц потребуется одно и то же число логических чтений. Оба используют 19*8Кб страниц. Исходя из этого, выясняеся, кто быстрее. А именно, использование представления не ухудшает производительность. Давайте сравним фактические планы выполнения, используя Compare Showplan:
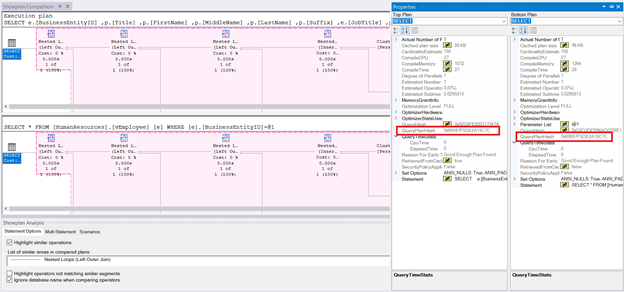
Рис.4. Сравнение планов для запроса, использующего представление, и запроса, использующего базовые таблицы. Планы одинаковы. Итак, они обрабатываются одинаково.
Вы видите заштрихованную часть диаграммы? Как насчет QueryPlanHash для обоих? Поскольку оба запроса имеют равный QueryPlanHash и те же операторы, что представление, что базовые таблицы, будут обрабатываться одинаково SQL Server'ом.
Одно и то же число логических чтений и одинаковые планы примера говорят о том, что оба запроса будут выполняться одинаково. Таким образом, чем больше логических чтений, тем медленее запрос будет выполняться вне зависимости от того, используются представления или нет. Этот факт поможет вам решить проблему и сделать ваши представления более быстрыми.
К сожалению, есть и плохие новости.
Ранее у нас SELECT из представлени я не использовал соединения. Что если соединить представление с таблицей?
Рассмотрим еще один пример. Теперь мы используем представление vSalesPerson в AdventureWorks - список продавцов с контактной информацией и квотой продаж. И снова сравним оператор с SELECT из базовых таблиц:
Если вы полагаете получить одно и то же, проверьте STATISTICS IO:
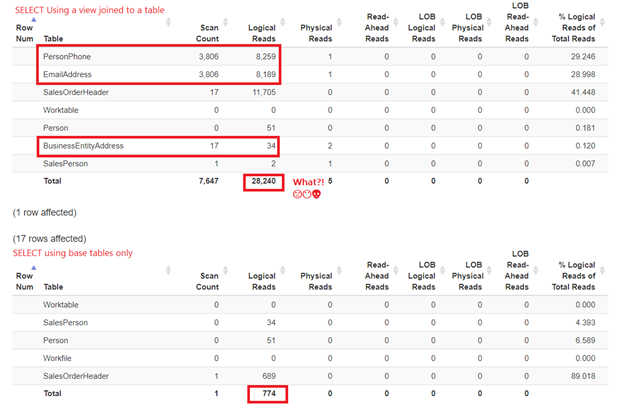
Рис.5. Сравнение STATISTICS IO соединения с таблицей и использование базовых таблиц. Использование соединения ухудшает производительность в числе логических чтений.
Удивлены? Соединение представления vSalesPerson с таблицей SalesOrderHeader требует огромных ресурсов (28,240 x 8Кб) по сравнению с использованием одних только базовых таблиц (774 x 8Кб). Обратите внимание также на то, что включены некоторые таблицы, которые нам не требуются (таблицы в красных рамках). Не говоря уже о более высоком числе логических чтений SalesOrderHeader при использовании представления.
Но это еще не все.
Вот фактический план выполнения запроса к базовым таблицам:
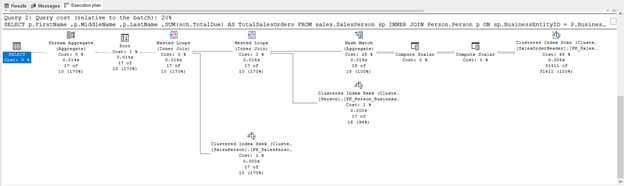
Рис.6. Фактический план выполнения запроса к базовым таблицам
На иллюстрации показан вполне нормальный план выполнения. Но оцените план с представлением:
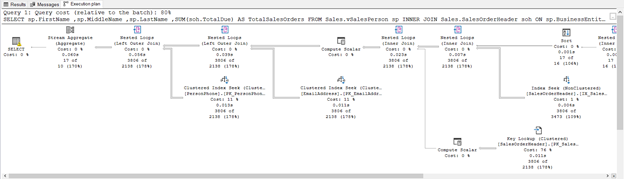
Рис.7. В узле SELECT запроса с представлением появляется предупреждение.
План выполнения на Рис.7 согласуется с STATISTICS IO на Рис.5. Можно увидеть таблицыЮ которые нам не требуются из представления. Имеется также узел Key Lookup с оценкой числа строк, которая более чем на тысячу записей отличается от фактического числа строк. Наконец, появляется еще и предупреждение на узле SELECT. Что это может быть?
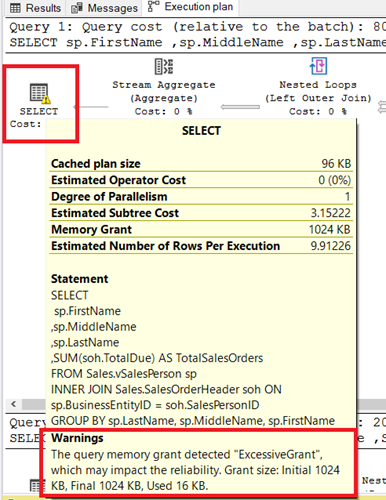
Рис.8. Предупреждение Memory Grant о чрезмерном выделении памяти. Чрезмерное потому, что запрос использует 16Кб, а рассчитанная память для его выполнения - 1024Кб.
Что это за предупреждение ExcessiveGrant в узле SELECT?
Excessive Grant имеет место, когда максимум использованной памяти слишклом мал по сравнению с выделенной памятью. В этом случае выделено 1024Кб, а использовано только 16Кб.
Memory Grant - это оценка количества памяти в Кб, требуемая для выполнения плана.
Это может быть неверная оценка в узле Key Lookup, и/или это может быть причиной включения в план таблиц, в которых мы не нуждаемся. Кроме того, большое выделение памяти может стать причиной блокировок. Лишние 1008Кб могли бы использоваться другими операторами.
В конце концов, что-то пошло не так, когда представление соединялось с таблицей. Мы не сталкиваемся с этими проблемами, если запрос использует базовые таблицы.
Это было длинное объяснение. Тем не менее, мы знаем, что представления не оцениваются или обрабатываются ДО оценивания предложения WHERE или соединений во внешнем запросе. Мы также подтвердили, что оба будут выполняться обинаково.
С другой стороны, имеется случай, когда мы соединяем представление с таблицей. Он использует соединения таблиц, которые нам не нужны из представления. Они не видны, пока мы не проверим STATISTICS IO и фактический план выполнени. Это может ухудшить производительность, и проблемы могут возникнуть из ниоткуда.
Следовательно:
Тогда мы можем быть уверены, что не напишем представлений, которые будут давать верные результаты, но двигаться как улитка.
Название определяет суть индексированных представлений. Это может дать прирост производительности для операторов SELECT. Но, как и в случае табличных индексов, может повлиять на производительность, если базовые таблицы большие и постоянно обновляются.
Чтобы увидеть как индексированные представления могут улучшить производительность, проверим представление vStateProvinceCountryRegion в AdventureWorks. Данное представление проиндексоровано по StateProvinceID и CountryRegionCode. Это кластеризованный уникальный индекс.
Сравним STATISTICS IO для представления с индексом и без него. При этом мы узнаем, сколько 8-килобайтных страниц прочитает наш SQL Server:
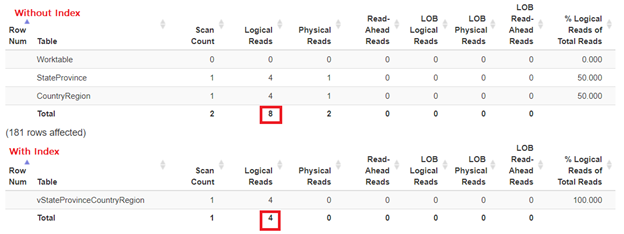
Рис.9. Сравнение логических чтений для представления с индексом и без.
Ри.9 показывает, что наличие индекса на представлении vStateProvinceCountryRegion уменьшает число логических чтений вдвое. Это 50% улучшение по сравнению с представлением без индекса.
Это хорошая новость.
Но опять таки, не добавляйте индексы в ваши представления бездумно. Помимо наличия длинного списка ограничительных правил для наличия одного уникального кластеризованного индекса, это может ухудшить производительность, подобно необдуманному добавлению индексов для таблиц. Кроме того, проверяйте STATISTICS IO на предмет уменьшения числа логических чтений после добавления индекса.
Выводы
Как видно из нашего примера, индексированные представления могут улучшить производительность представлений SQL.
Представления SQL - это виртуальные таблицы. Записи в представлении являются результатом выполнения запроса, лежащего в их определении. Всякий раз, когда обновляются базовые таблицы, используемые в представлении, представление обновляется также. В некоторых случаях вы можете даже использовать операторы UPDATE, INSERT, DELETE с представлением, как будто это таблица. Хотя я не пытался сам это делать.
Как и для таблицы, вы можете использовать CREATE, ALTER или DROP с представлением. Вы можете даже создать индекс при некоторых ограничениях.
Замечу, что в примерах я использую SQL Server 2019.
1. О правильном и неправильном использовании представлений SQL
Начнем с основ.
Для чего предназначены представления SQL?
Это ключевой момент. Если использовать его как молоток вместо отвертки, забудьте о более быстрых представлениях SQL. Сначала перечислим варианты правильного использования:
- Чтобы сфокусировать, упростить и персонализировать базу данных для каждого пользователя.
- Чтобы в целях безопасности позволить пользователям доступ только к той информации, которая им требуется.
- Чтобы обеспечить обратную совместимость со старой таблицей или старой схемой, не повредив зависящие приложения. Это временная мера до тех пор, пока не завершатся необходимые изменения.
- Чтобы разделить данные, приходящие с разных серверов. Тем самым создается впечатление, что это одна таблица на одном сервере или экземпляре.
Когда НЕ использовать представления SQL?
- Не использовать представление в другом представлении, которое будет использоваться, в свою очередь, еще в одном представлении. Короче говоря, речь идет о глубоко вложенных представлениях. Такое повторное использование кода имеет несколько недостатков.
- Экономия при наборе. Это связано с первым случаем, который уменьшает количество нажатий клавиш и, кажется, ускоряет написание кода.
Неправильное использование представлений, если допускается, сделает неясной настоящую причину, зачем вы создаете представления. Как будет показано ниже, реальные преимущества перевешивают предполагаемые выгоды от неправильного использования.
Пример
Давайте проверим пример от Microsoft. Это представление vEmployee из AdventureWorks. Вот код:
-- Имена сотрудников и основная контактная информация
CREATE VIEW [HumanResources].[vEmployee]
AS
SELECT
e.[BusinessEntityID]
,p.[Title]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,p.[Suffix]
,e.[JobTitle]
,pp.[PhoneNumber]
,pnt.[Name] AS [PhoneNumberType]
,ea.[EmailAddress]
,p.[EmailPromotion]
,a.[AddressLine1]
,a.[AddressLine2]
,a.[City]
,sp.[Name] AS [StateProvinceName]
,a.[PostalCode]
,cr.[Name] AS [CountryRegionName]
,p.[AdditionalContactInfo]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[BusinessEntityAddress] bea
ON bea.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[Address] a
ON a.[AddressID] = bea.[AddressID]
INNER JOIN [Person].[StateProvince] sp
ON sp.[StateProvinceID] = a.[StateProvinceID]
INNER JOIN [Person].[CountryRegion] cr
ON cr.[CountryRegionCode] = sp.[CountryRegionCode]
LEFT OUTER JOIN [Person].[PersonPhone] pp
ON pp.BusinessEntityID = p.[BusinessEntityID]
LEFT OUTER JOIN [Person].[PhoneNumberType] pnt
ON pp.[PhoneNumberTypeID] = pnt.[PhoneNumberTypeID]
LEFT OUTER JOIN [Person].[EmailAddress] ea
ON p.[BusinessEntityID] = ea.[BusinessEntityID];
GOЦель этого представления - сфокусироваться на основной информации о сотрудниках. Если потребуется, отдел кадров может отобразить её на веб-странице. Было ли оно повторно использовано в других представлениях?
Выясним это:
- В SQL Server Management Studio выберем базу данных AdventureWorks.
- Развернем папку Views и выберем [HumanResources].[vEmployee].
- Щелкнем правой кнопкой и выберем View Dependencies.
Если вы видите другое представление, зависящее от этого, которое, в свою очередь, зависит от другого представления, то Microsoft дало бы нам плохой пример. Но здесь нет других зависимостей от данного представления.
Пойдем дальше.
2. Развенчиваем миф о представлениях SQL
Когда SQL Server обрабатывает SELECT от представления, он оценивает код в представлении ПРЕЖДЕ предложения WHERE или любого соединения во внешнем запросе. Когда соединяется большое число таблиц, это будет медленней по сравнению с SELECT с базовыми таблицами при тех же результатах.
По крайней мере, это то, что мне говорили, когда я начинал использовать SQL. Миф или нет, есть только один способ это проверить. Вернемся к практическому примеру.
Как работают представления SQL
Microsoft не оставило нас бесконечно дебатировать в темноте. Мы имеем инструменты, позволяющие наблюдать, как работают запросы, такие как STATISTICS IO (статистика ввода/вывода) и Actual Execution Plan (фактический план выполнения). Мы будем использовать их в наших примерах. Вот первый из них.
USE AdventureWorks
GO
SELECT * FROM HumanResources.vEmployee e
WHERE e.BusinessEntityID = 105Чтобы увидеть, что происходит, когда SQL Server обрабатывает представление, рассмотрим фактический план выполнения на рис.1. Мы сравним его с кодом в CREATE VIEW для vEmployee в предыдущем разделе.
Рис.1. План выполнения запроса с представлением SQL. Предложение WHERE не обрабатывалось последним.
Как видно, первыми SQL Server обрабатывает узлы, использующие INNER JOIN. Затем обработка переходит к соединениям LEFT OUTER JOIN.
Поскольку мы нигде не находим узла Filter для предложения WHERE, он должен быть в одном из тех узлов. Если вы раскроете свойства всех узлов, то увидите предложение WHERE, обрабатываемое в таблице Employee. Я обвел его рамкой на Рис.1. В доказательство посмотрите Рис.2 со свойствами этого узла:
Рис.2. Свойства узла таблицы Employee, показывающие использование Seek Predicate (поисковый предикат). Это также предложение WHERE e.BusinessEntityID = 105.
Анализ
Итак, должен ли оператор SELECT в представлении vEmployee оцениваться или обрабатываться ДО применения предложения WHERE? План выполнения показывает, что не должен. Если это было так, то он должен появиться в ближайшем узле SELECT.
То, что мне говорили, было мифом. Я избегал чего-то хорошего из-за неправильного понимания использования представлений SQL.
Теперь, когда мы знаем как SQL Server обрабатывает SELECT из представления, остается вопрос: это медленнее, чем без использования представления?
SELECT из представления или SELECT из базовых таблиц - что будет выполняться быстрей?
Во-первых, нам нужно извлечь оператор SELECT из представления vEmployee и произвести тот же результат, который мы имели при использовании представления. В коде ниже показано то же самое предложение WHERE:
USE AdventureWorks
GO
-- SELECT FROM a view
SELECT * FROM HumanResources.vEmployee e
WHERE e.BusinessEntityID = 105
-- SELECT FROM Base Tables
SELECT
e.[BusinessEntityID]
,p.[Title]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,p.[Suffix]
,e.[JobTitle]
,pp.[PhoneNumber]
,pnt.[Name] AS [PhoneNumberType]
,ea.[EmailAddress]
,p.[EmailPromotion]
,a.[AddressLine1]
,a.[AddressLine2]
,a.[City]
,sp.[Name] AS [StateProvinceName]
,a.[PostalCode]
,cr.[Name] AS [CountryRegionName]
,p.[AdditionalContactInfo]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[BusinessEntityAddress] bea
ON bea.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[Address] a
ON a.[AddressID] = bea.[AddressID]
INNER JOIN [Person].[StateProvince] sp
ON sp.[StateProvinceID] = a.[StateProvinceID]
INNER JOIN [Person].[CountryRegion] cr
ON cr.[CountryRegionCode] = sp.[CountryRegionCode]
LEFT OUTER JOIN [Person].[PersonPhone] pp
ON pp.BusinessEntityID = p.[BusinessEntityID]
LEFT OUTER JOIN [Person].[PhoneNumberType] pnt
ON pp.[PhoneNumberTypeID] = pnt.[PhoneNumberTypeID]
LEFT OUTER JOIN [Person].[EmailAddress] ea
ON p.[BusinessEntityID] = ea.[BusinessEntityID]
WHERE e.BusinessEntityID = 105Затем мы смотрим статистику ввода/вывода и сравниваем планы. Как много ресурсов потребуется запросу из представления по сравнению с запросом из базовых таблиц? Посмотрите Рис.3.
Рис.3. STATISTICS IO для запроса из представления и запроса из базовых таблиц. Для обоих запросов совпадает количество логических чтений. (Результаты STATISTICS IO отформатированы с помощью http://statisticsparser.com/)
Здесь для запросов из представления или базовых таблиц потребуется одно и то же число логических чтений. Оба используют 19*8Кб страниц. Исходя из этого, выясняеся, кто быстрее. А именно, использование представления не ухудшает производительность. Давайте сравним фактические планы выполнения, используя Compare Showplan:
Рис.4. Сравнение планов для запроса, использующего представление, и запроса, использующего базовые таблицы. Планы одинаковы. Итак, они обрабатываются одинаково.
Вы видите заштрихованную часть диаграммы? Как насчет QueryPlanHash для обоих? Поскольку оба запроса имеют равный QueryPlanHash и те же операторы, что представление, что базовые таблицы, будут обрабатываться одинаково SQL Server'ом.
Одно и то же число логических чтений и одинаковые планы примера говорят о том, что оба запроса будут выполняться одинаково. Таким образом, чем больше логических чтений, тем медленее запрос будет выполняться вне зависимости от того, используются представления или нет. Этот факт поможет вам решить проблему и сделать ваши представления более быстрыми.
К сожалению, есть и плохие новости.
Соединение представлений с таблицами
Ранее у нас SELECT из представлени я не использовал соединения. Что если соединить представление с таблицей?
Рассмотрим еще один пример. Теперь мы используем представление vSalesPerson в AdventureWorks - список продавцов с контактной информацией и квотой продаж. И снова сравним оператор с SELECT из базовых таблиц:
-- получить общие отчеты продаж для каждого продавца
-- используя представление, соединенное с SalesOrderHeader
SELECT
sp.FirstName
,sp.MiddleName
,sp.LastName
,SUM(soh.TotalDue) AS TotalSalesOrders
FROM Sales.vSalesPerson sp
INNER JOIN Sales.SalesOrderHeader soh ON sp.BusinessEntityID = soh.SalesPersonID
GROUP BY sp.LastName, sp.MiddleName, sp.FirstName
-- использование базовых таблиц
SELECT
p.FirstName
,p.MiddleName
,p.LastName
,SUM(soh.TotalDue) AS TotalSalesOrders
FROM sales.SalesPerson sp
INNER JOIN Person.Person p ON sp.BusinessEntityID = P.BusinessEntityID
INNER JOIN Sales.SalesOrderHeader soh ON sp.BusinessEntityID = soh.SalesPersonID
GROUP BY p.LastName, p.MiddleName, p.FirstNameЕсли вы полагаете получить одно и то же, проверьте STATISTICS IO:
Рис.5. Сравнение STATISTICS IO соединения с таблицей и использование базовых таблиц. Использование соединения ухудшает производительность в числе логических чтений.
Удивлены? Соединение представления vSalesPerson с таблицей SalesOrderHeader требует огромных ресурсов (28,240 x 8Кб) по сравнению с использованием одних только базовых таблиц (774 x 8Кб). Обратите внимание также на то, что включены некоторые таблицы, которые нам не требуются (таблицы в красных рамках). Не говоря уже о более высоком числе логических чтений SalesOrderHeader при использовании представления.
Но это еще не все.
Фактический план выполнения обнаруживает еще кое-что
Вот фактический план выполнения запроса к базовым таблицам:
Рис.6. Фактический план выполнения запроса к базовым таблицам
На иллюстрации показан вполне нормальный план выполнения. Но оцените план с представлением:
Рис.7. В узле SELECT запроса с представлением появляется предупреждение.
План выполнения на Рис.7 согласуется с STATISTICS IO на Рис.5. Можно увидеть таблицыЮ которые нам не требуются из представления. Имеется также узел Key Lookup с оценкой числа строк, которая более чем на тысячу записей отличается от фактического числа строк. Наконец, появляется еще и предупреждение на узле SELECT. Что это может быть?
Рис.8. Предупреждение Memory Grant о чрезмерном выделении памяти. Чрезмерное потому, что запрос использует 16Кб, а рассчитанная память для его выполнения - 1024Кб.
Что это за предупреждение ExcessiveGrant в узле SELECT?
Excessive Grant имеет место, когда максимум использованной памяти слишклом мал по сравнению с выделенной памятью. В этом случае выделено 1024Кб, а использовано только 16Кб.
Memory Grant - это оценка количества памяти в Кб, требуемая для выполнения плана.
Это может быть неверная оценка в узле Key Lookup, и/или это может быть причиной включения в план таблиц, в которых мы не нуждаемся. Кроме того, большое выделение памяти может стать причиной блокировок. Лишние 1008Кб могли бы использоваться другими операторами.
В конце концов, что-то пошло не так, когда представление соединялось с таблицей. Мы не сталкиваемся с этими проблемами, если запрос использует базовые таблицы.
Выводы
Это было длинное объяснение. Тем не менее, мы знаем, что представления не оцениваются или обрабатываются ДО оценивания предложения WHERE или соединений во внешнем запросе. Мы также подтвердили, что оба будут выполняться обинаково.
С другой стороны, имеется случай, когда мы соединяем представление с таблицей. Он использует соединения таблиц, которые нам не нужны из представления. Они не видны, пока мы не проверим STATISTICS IO и фактический план выполнени. Это может ухудшить производительность, и проблемы могут возникнуть из ниоткуда.
Следовательно:
- Мы должны знать, как запросы, включающие представления, работают изнутри.
- STATISTICS IO и фактический план выполнения покажут, как будут работать запросы и представления.
- Мы не можем просто соединить представление с таблицей и небрежно использовать его повторно. Всегда проверяйте STATISTICS IO и фактический план выполнения!
Тогда мы можем быть уверены, что не напишем представлений, которые будут давать верные результаты, но двигаться как улитка.
Попробуйте индексированные представления
Название определяет суть индексированных представлений. Это может дать прирост производительности для операторов SELECT. Но, как и в случае табличных индексов, может повлиять на производительность, если базовые таблицы большие и постоянно обновляются.
Чтобы увидеть как индексированные представления могут улучшить производительность, проверим представление vStateProvinceCountryRegion в AdventureWorks. Данное представление проиндексоровано по StateProvinceID и CountryRegionCode. Это кластеризованный уникальный индекс.
Сравним STATISTICS IO для представления с индексом и без него. При этом мы узнаем, сколько 8-килобайтных страниц прочитает наш SQL Server:
Рис.9. Сравнение логических чтений для представления с индексом и без.
Ри.9 показывает, что наличие индекса на представлении vStateProvinceCountryRegion уменьшает число логических чтений вдвое. Это 50% улучшение по сравнению с представлением без индекса.
Это хорошая новость.
Но опять таки, не добавляйте индексы в ваши представления бездумно. Помимо наличия длинного списка ограничительных правил для наличия одного уникального кластеризованного индекса, это может ухудшить производительность, подобно необдуманному добавлению индексов для таблиц. Кроме того, проверяйте STATISTICS IO на предмет уменьшения числа логических чтений после добавления индекса.
Выводы
Как видно из нашего примера, индексированные представления могут улучшить производительность представлений SQL.
Дополнительный совет
Как и любой другой запрос, представления SQL будут выполняться быстро, если:
- Статистика обновляется
- Добавлены отсутствующие индексы
- Индексы дефрагментированы
- Индексы используют правильный коэффициент заполнения (FILLFACTOR)
Заключение
Хороши или плохи представления SQL?
Представлени я SQL хороши, если написать их правильно и проверить, как они обрабатываются. У нас имеется инструменты типа STATISTICS IO и Actual Execution Plan - используйте их! Индексированные представления также могут улучшить производительность.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой