
Использование триггеров для замены скалярных UDF на вычисляемых столбцах
Пересказ статьи Brent Ozar. Using Triggers to Replace Scalar UDFs on Computed Columns
Ваша база данных усеяна вычисляемыми столбцами, чье определение включает скалярную пользовательскую функцию. Даже вплоть до SQL Server 2019, который быстрей обрабатывает скалярную функцию, любая таблица, которая включает скалярную функцию приводит к однопоточному доступу к таблице. В этом случае, триггер может реально стать отличной заменой.
Но, постойте. Триггеры имеют довольно плохую репутацию в сообществе баз данных, поскольку:
Но имеется несколько мест, где триггер подойдет с минимумом недостатков, и это одно из них. Для демонстрации проблемы я возьму среднего размера базу данных Stack Overflow на 50Гб и сделаю простой подсчет числа строк:
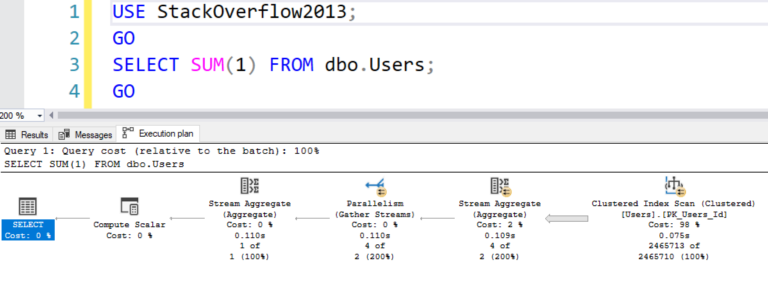
План выполнения получается параллельным:
Однако добавим вычисляемый столбец в таблицу, и снова выполним наш подсчет:
И запрос больше не будет выполняться параллельно, даже несмотря на то, что он не вызывает этой функции:
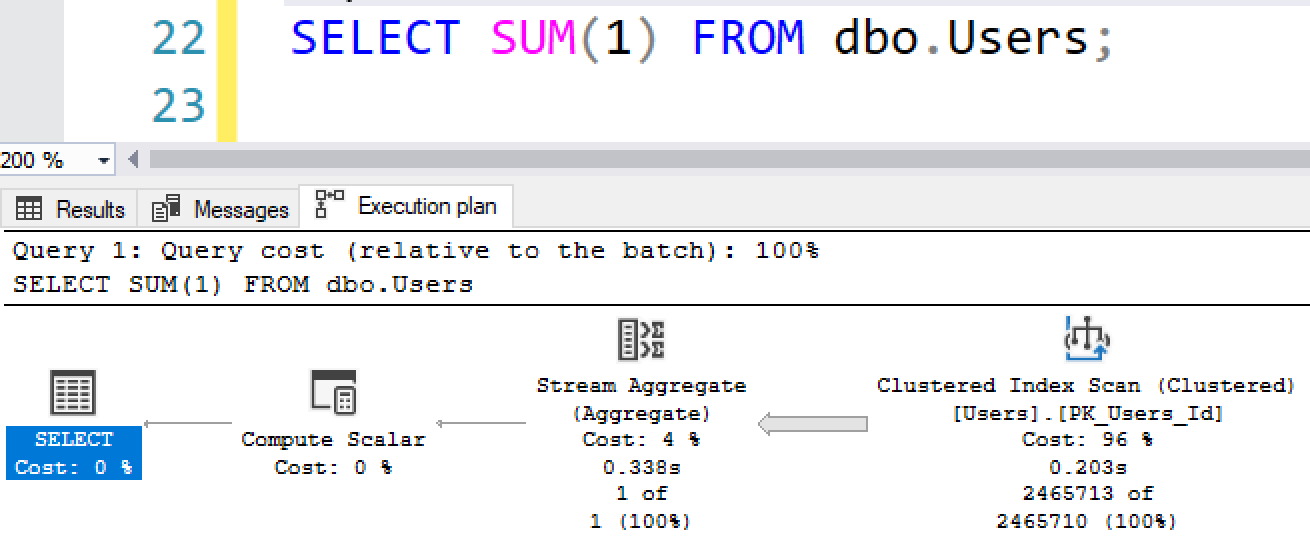
Если посмотреть свойства плана запроса, мы можем увидеть, что SQL Server не смог построить параллельный план выполнения, хоть и непонятно почему:

Вместо того, чтобы основывать столбец Seniority на вычисляемой пользовательской функции, мы можем:
Вот так:
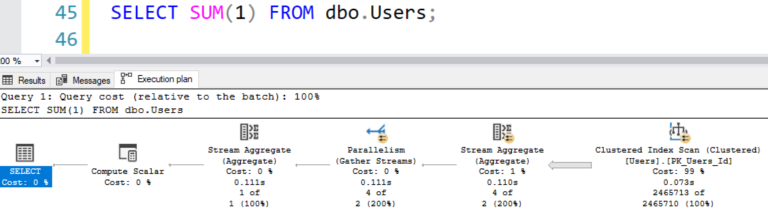
Когда я вставляю или обновляю таблицу Users, триггер становится однопоточным, поскольку он обновляет столбец Seniority - но это все. Теперь, если я выполню подсчет опять, он может стать многопоточным:
Конечно, я бы предпочел, чтобы собственники приложений перекомпилировали их и сами актуализировали столбец Seniority, когда они делают вставки и обновления, но я зачастую не имею такой роскоши - особенно, когда множество приложений обращаются к таблице Users, и они привыкли к тому, что вычисляемый столбец Seniority обновляется автоматически.
Эта публикация не является исчерпывающим руководством по написанию самых быстрых триггеров - это всего лишь 500 слов, чтобы напомнить вам, что в этом сценарии триггеры лучше, чем альтернатива со скалярными UDF в качестве вычисляемых столбцов.
- Вы можете завалить его кучей работы, приводящей к удивительному замедлению при масштабировании.
- Вы можете удерживать открытыми блокировки в течение длительного времени, если вы работаете с множеством таблиц.
- Поиск проблем может оказаться непростым, поскольку авторы редко журнализируют ошибки, возникающие в триггерах.
- Они почти всегда содержат баг, связанный с множественной обработкой записей.
Но имеется несколько мест, где триггер подойдет с минимумом недостатков, и это одно из них. Для демонстрации проблемы я возьму среднего размера базу данных Stack Overflow на 50Гб и сделаю простой подсчет числа строк:
USE StackOverflow2013;
GO
SELECT SUM(1) FROM dbo.Users;
GOПлан выполнения получается параллельным:
Однако добавим вычисляемый столбец в таблицу, и снова выполним наш подсчет:
CREATE OR ALTER FUNCTION dbo.fn_GetSeniority(@Reputation INT)
RETURNS VARCHAR(10)
AS
BEGIN
DECLARE @Seniority VARCHAR(10)
IF @Reputation > 10000
SET @Seniority = 'Senior';
ELSE
SET @Seniority = 'Junior';
RETURN @Seniority;
END;
GO
ALTER TABLE dbo.Users
ADD Seniority AS dbo.fn_GetSeniority(Reputation);
GO
SELECT SUM(1) FROM dbo.Users;И запрос больше не будет выполняться параллельно, даже несмотря на то, что он не вызывает этой функции:
Если посмотреть свойства плана запроса, мы можем увидеть, что SQL Server не смог построить параллельный план выполнения, хоть и непонятно почему:
Мы можем исправить это с помощью триггера.
Вместо того, чтобы основывать столбец Seniority на вычисляемой пользовательской функции, мы можем:
- Удалить вычисляемый столбец.
- Добавить обычный столбец.
- Поддерживать его актуальность при помощи триггера.
Вот так:
ALTER TABLE dbo.Users
DROP COLUMN Seniority;
GO
ALTER TABLE dbo.Users
ADD Seniority VARCHAR(10);
GO
/* Введем начальные значения */
UPDATE dbo.Users
SET Seniority = dbo.fn_GetSeniority(Reputation);
GO
CREATE OR ALTER TRIGGER Users_Seniority ON dbo.Users
AFTER INSERT, UPDATE
AS
BEGIN
UPDATE u
SET Seniority = dbo.fn_GetSeniority(u.Reputation)
FROM dbo.Users u
INNER JOIN inserted i ON u.Id = i.Id;
END;
GO Когда я вставляю или обновляю таблицу Users, триггер становится однопоточным, поскольку он обновляет столбец Seniority - но это все. Теперь, если я выполню подсчет опять, он может стать многопоточным:
Конечно, я бы предпочел, чтобы собственники приложений перекомпилировали их и сами актуализировали столбец Seniority, когда они делают вставки и обновления, но я зачастую не имею такой роскоши - особенно, когда множество приложений обращаются к таблице Users, и они привыкли к тому, что вычисляемый столбец Seniority обновляется автоматически.
Эта публикация не является исчерпывающим руководством по написанию самых быстрых триггеров - это всего лишь 500 слов, чтобы напомнить вам, что в этом сценарии триггеры лучше, чем альтернатива со скалярными UDF в качестве вычисляемых столбцов.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой