Глава 1. MS Access как система управления реляционными базами данных
С самой общей точки зрения база данных представляет собой набор записей и файлов, организованных специальным образом. То есть информация в базах данных хранится в структурированном виде. Здесь мы познакомимся с базами, имеющими реляционную структуру организации данных.
Реляционная модель данных предполагает, что данные представляются только одним способом, а именно, в виде таблиц. Каждая строка в таблице содержит информацию, относящуюся к некоторому конкретному объекту. Эта информация представляет собой набор фактов, при этом в столбце (называемом также атрибутом или полем) содержится конкретный факт. Столбцы имеют заголовки (имена), которые и служат для извлечения нужных фактов. Поскольку порядок столбцов считается неопределенным, то имена столбцов являются единственным средством доступа к соответствующему факту. Например, таблица Сотрудники может иметь столбцы с именами имя и дата_рождения, что предполагает нахождение в этих столбцах информации об имени и дате рождения сотрудника соответственно.
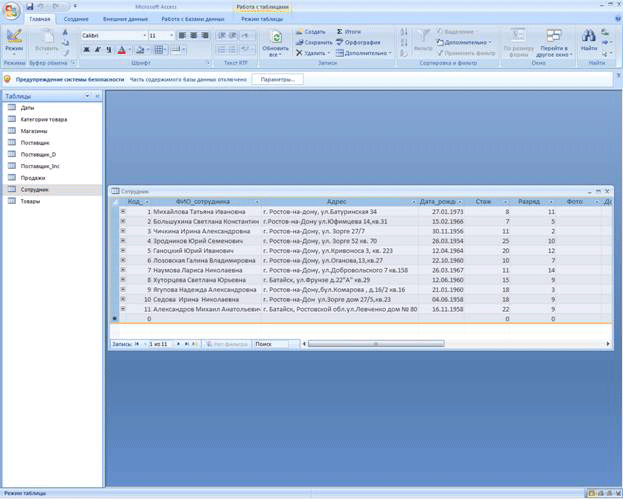 |
Значения столбцов являются атомарными, т.е. они могут быть определены только на простых типах данных, другими словами, значением столбца не может быть таблица. Строки таблицы (называемые также записями или кортежами) неупорядочены, что означает, что для доступа к определенной записи используется не ее порядковый номер, а лишь значение в определенном столбце или сочетание значений в нескольких столбцах.
В связи с этим особую важность приобретает потенциальный ключ – столбец или набор столбцов .
 |
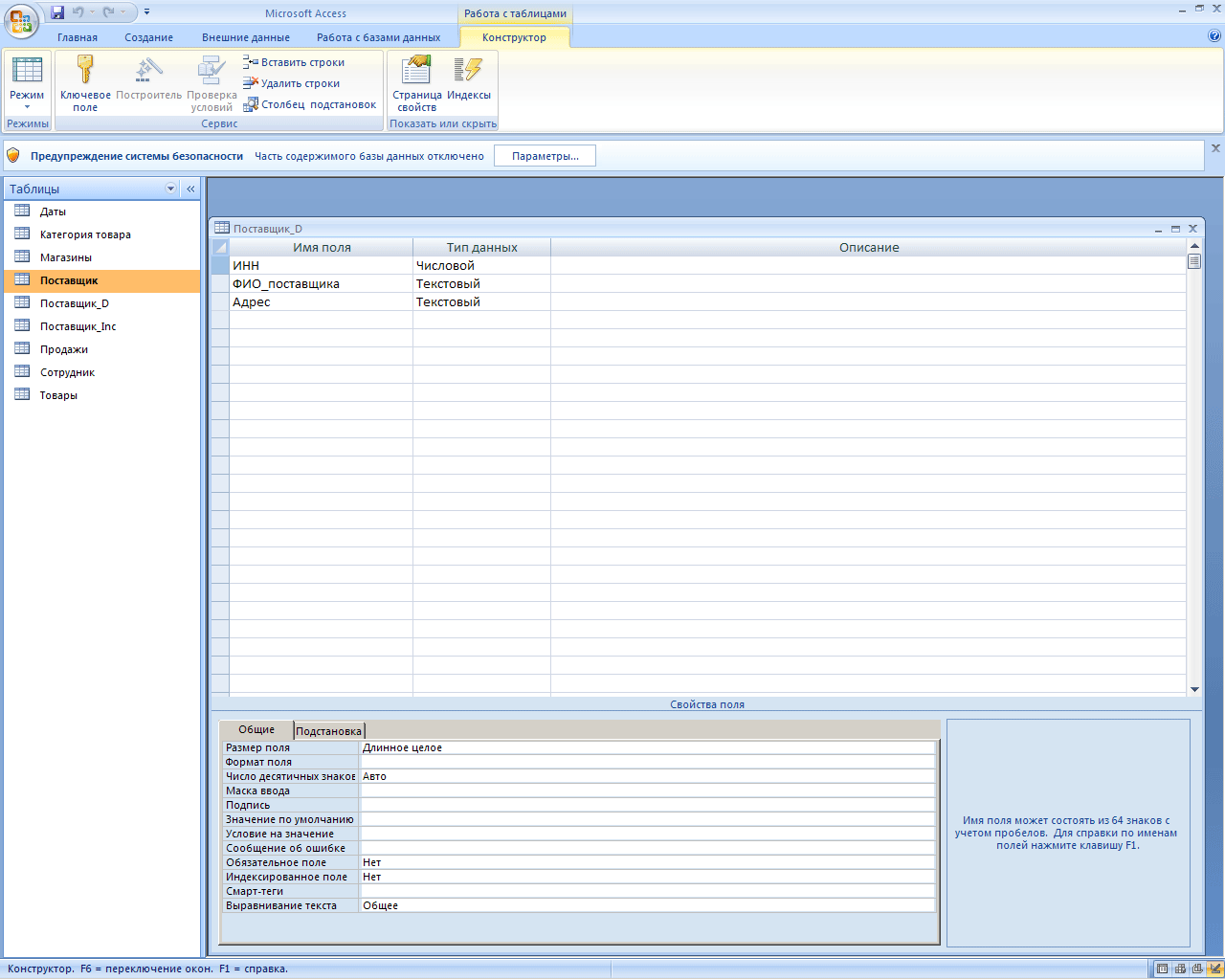 |
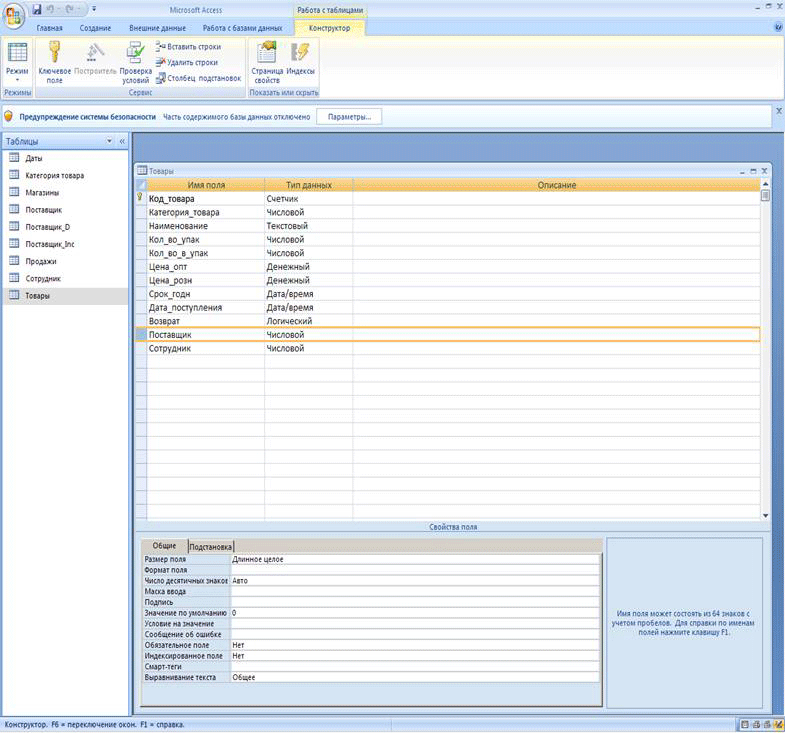
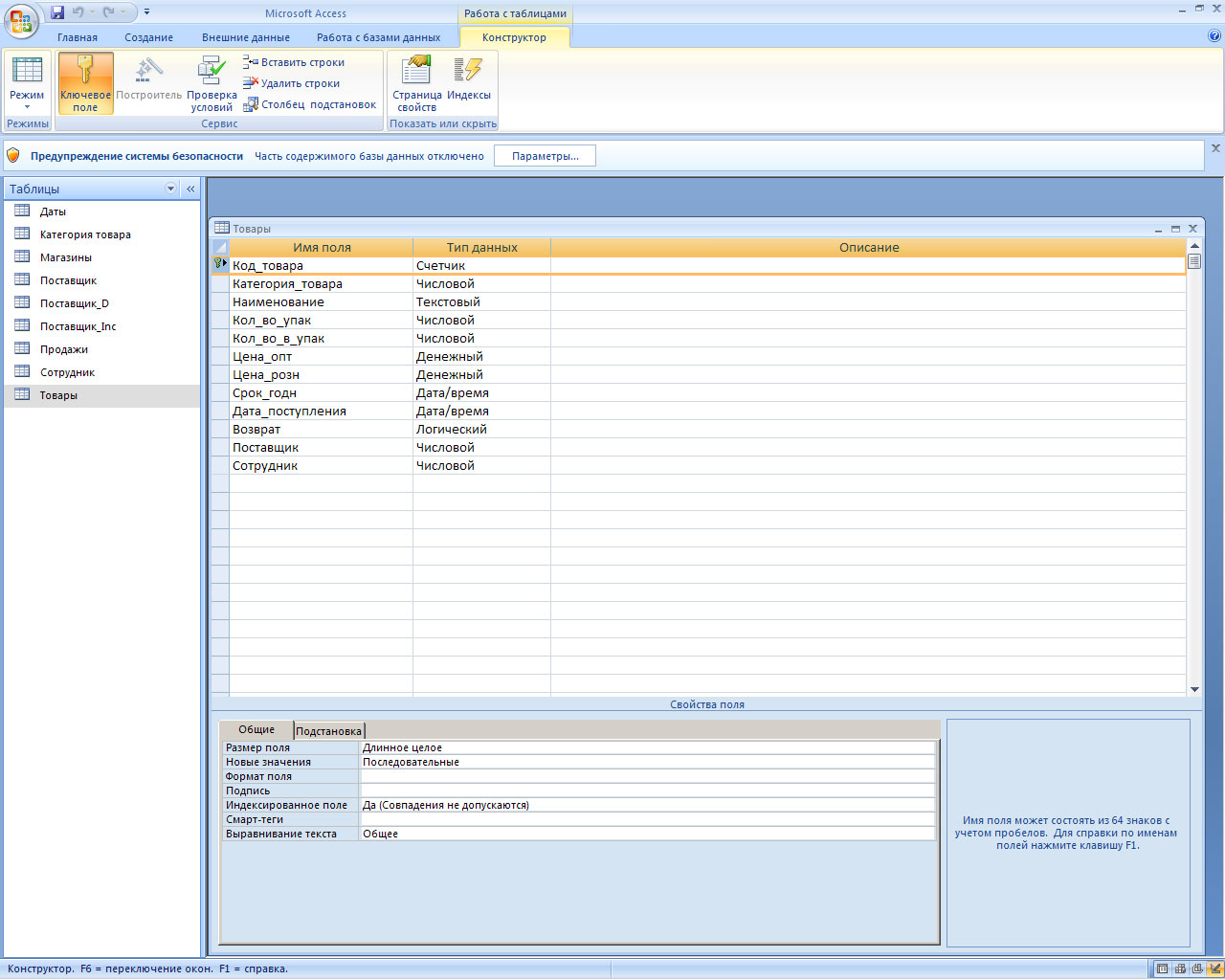
Итак, реляционная теория рассматривает базу данных как набор таблиц. Возьмем в качестве примера две таблицы – Поставщики и Товары. Информация в этих таблицах логически связана, поскольку каждый товар поставляется неким поставщиком. Такая связь обеспечивается наличием в таблице "Товары" столбца, идентифицирующего поставщика этого товара в таблице "Поставщики". Такой столбец (например, поставщик) будет содержать значения, совпадающие со значениями соответствующего столбца (скажем, ИНН) в таблице "Поставщики". Для осуществления связи значения в столбце ИНН должны быть уникальны, а именно, этот столбец должен быть потенциальным ключом, в противном случае мы не сможем сказать, какому поставщику принадлежит данный товар. Естественно, уникальность не требуется для столбца поставщик, поскольку один поставщик может поставлять любое количество товаров. Таким образом,
 |
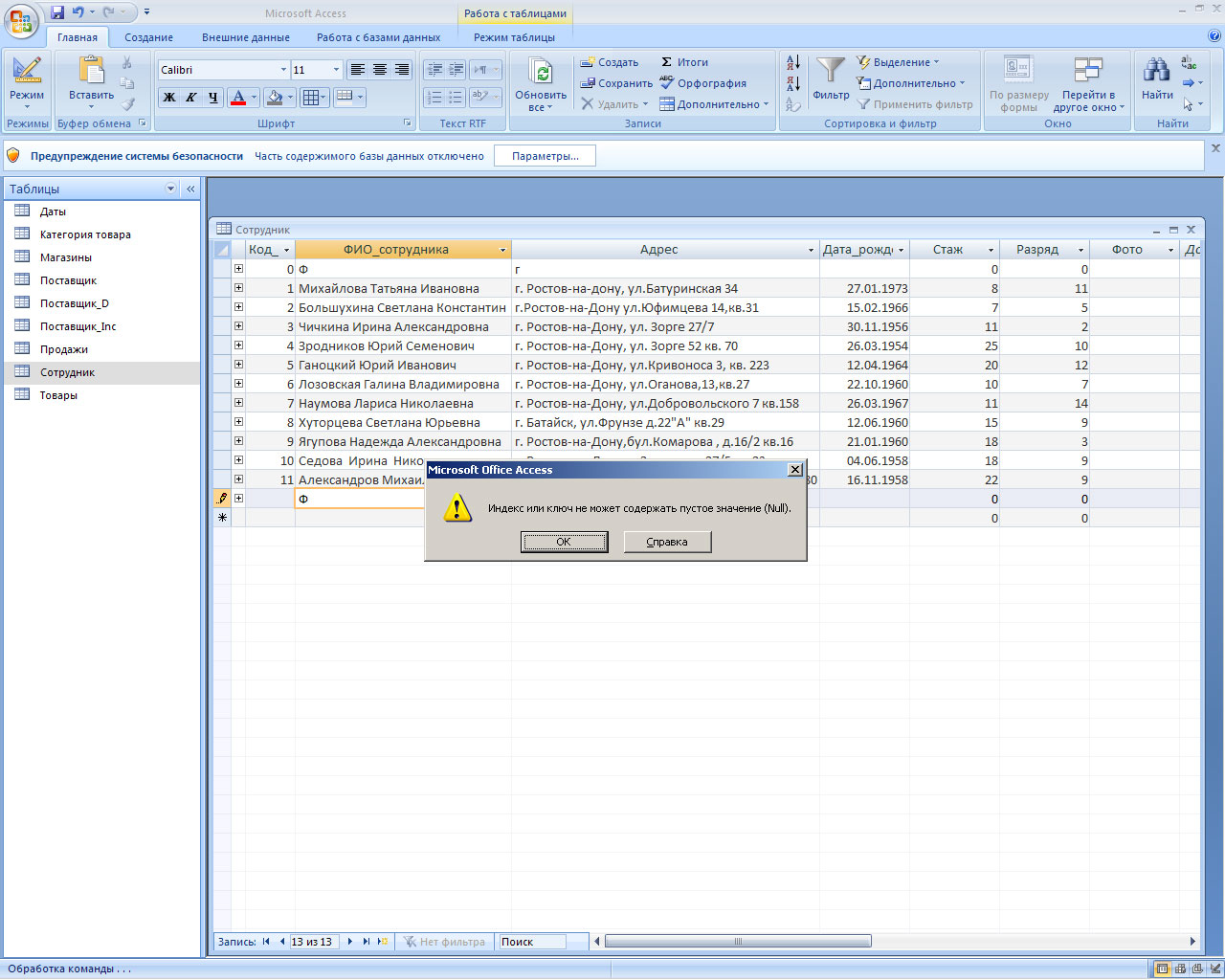
В любой реляционной таблице может оказаться более одного потенциального ключа. Среди этих потенциальных ключей может быть выбран один (и только один) первичный ключ. Первичный ключ, в отличие от потенциальных ключей, должен иметь значение в каждой строке таблицы, т.е информация должна быть известна.Потенциальный ключ не имеет этого ограничения, в результате чего поле потенциального ключа может содержать специальные NULL-значения, означающие отсутствие информации.
Наличие первичного ключа обеспечивает так называемое правило категорной целостности, которое гласит, что каждый объект в базе данных должен быть однозначно идентифицирован. Как следствие, сохранение записи в базе данных будет невозможно до тех пор, пока не будет заполнено значение первичного ключа.
 |
Вернемся к связи между таблицами. Состояние базы данных, когда в таблице "Товары" в столбце поставщик имеется значение, отсутствующее в столбце ИНН таблицы "Поставщики", называется несогласованным. Для такого товара поставщик неизвестен. Эта ситуация, которая может возникнуть при удалении строки из таблицы "Поставщики" или в результате ошибки при вводе информации о товаре, называется потерей ссылочной целостности.
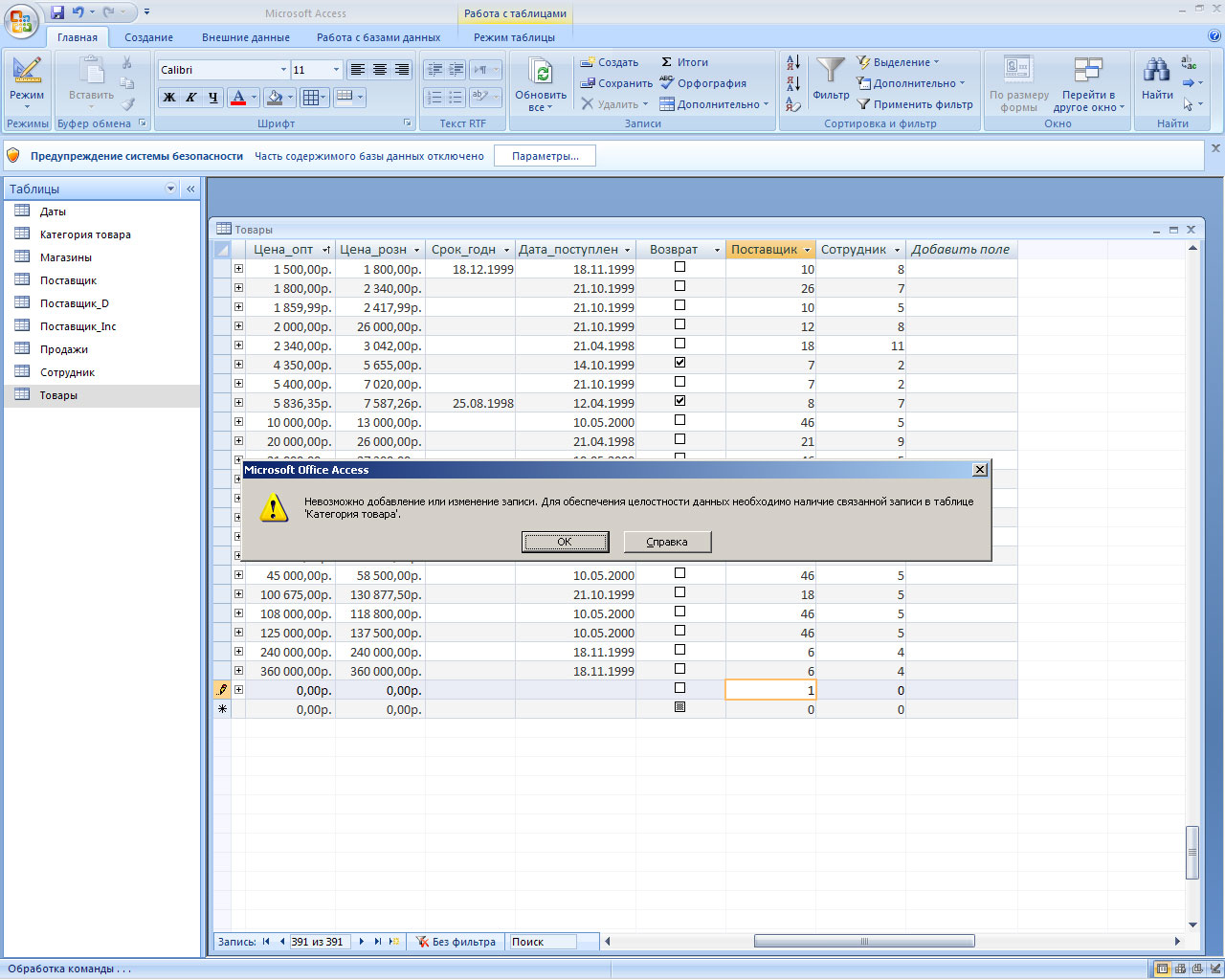 |
К счастью, СУБД автоматически обеспечивает ссылочную целостность посредством внешних ключей. Внешним ключом называют такой набор столбцов одной таблицы, который является потенциальным ключом другой (или той же самой) таблицы. Внешний ключ обеспечивает согласованное состояние двух таблиц. В нашем примере таким внешним ключом может быть столбец "поставщик" в таблице "Товары". Так вот, если назначить столбец "поставщик" внешним ключом к таблице "Поставщики", то тогда система будет следить за согласованностью данных, в частности, нельзя будет ввести в этот столбец значение, не соответствующее ни одному из поставщиков (отсутствующее в столбце ИНН). Также нельзя будет удалить поставщика (запись из таблицы Поставщики), если у этого поставщика есть товары (связанные записи в таблице Товары). Таким образом, действия, нарушающие ссылочную целостность, не будут выполнены; вместо этого будет генерироваться сообщение об ошибке.
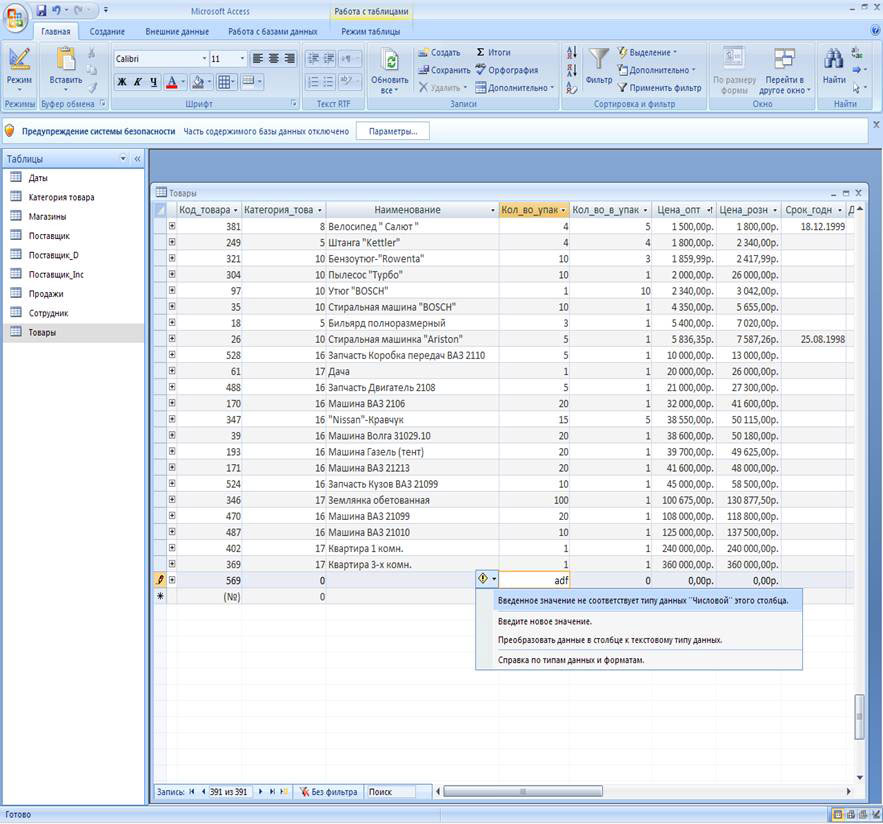 |
Помимо категорной и ссылочной целостности реляционная модель декларирует еще один тип ограничений, который называется проверочным ограничением.Проверочное ограничение устанавливается для столбца – это ограничение на ввод допустимых значений в данный столбец. Это может быть простое перечисление значений или диапазон (например, between 1 and 100 – число между 1 и 100). Однако здесь допускаются и более сложные выражения, которые могут иметь ссылки на другие таблицы базы данных. Проверочные ограничения проверяются при всяком изменении значения в соответствующем столбце.
Реляционная модель была впервые предложена в 1970 г. К.Ф.Коддом, который также ввел два языка манипуляции данными – реляционную алгебру и реляционное исчисление.Ни один из этих языков не используется непосредственно в реализациях СУБД. Однако они послужили базой для создания языка SQL, который является на сегодняшний день единственным стандартизированным языком взаимодействия с реляционными базами данных и поддерживается всеми ведущими производителями на рынке реляционных СУБД. MS Access не является здесь исключением.
Логическая модель данных и нормальные формы
Итак, мы выяснили, что в реляционной модели информация представляется пользователю только в виде таблиц. Поэтому логическое моделирование структур данных при создании информационного приложения состоит, в первую очередь, в отображении знаний разработчика о предметной области в форме таблиц и связей между ними. Тут возникает вопрос: сколько таблиц следует использовать? Вопрос далеко не праздный. Ведь для одной и той же модели предметной области можно разработать различные логические модели данных, содержащие разное число таблиц с разным числом атрибутов (столбцов). В логическом моделировании есть определенный произвол, который может быть обусловлен индивидуальными предпочтениями и накопленным опытом разработчиков. Однако есть вполне формальные требования к логической структуре, которые базируются на теории нормализации или теории нормальных форм отношений.
В качестве примера рассмотрим фрагмент таблицы, которая содержит информацию о поставщиках, поставляемых ими товарах и категориях товара.
| код_кат | наименование_кат | код_тов | наименование | код_пост | поставщик |
| 1 | Книги | 28 | История России | 34 | Костин Михаил Александрович |
| 1 | Книги | 231 | Камю. Бунтующий человек | 4 | Круглов Силантий Иванович |
| 1 | Книги | 232 | Юнг. Человек и его символы | 5 | Шевляков Иван Иванович |
| 4 | Парфюмерия | 186 | Дезодорант "Fa" | 4 | Круглов Силантий Иванович |
| 4 | Парфюмерия | 200 | Дезодорант "Mennen speed stick | 4 | Круглов Силантий Иванович |
| 7 | Хозтовары | 274 | Паста зубная "Помарин" | 6 | Иванов Сидор Петрович |
| 4 | Парфюмерия | 200 | Дезодорант "Mennen speed stick | 25 | Смирнов Сергей Александрович |
Первого взгляда на таблицу достаточно, чтобы увидеть, что данные в ней хранятся с избыточностью, что выражается в неоднократном упоминании наименования категории, наименования товара и имени поставщика. Само по себе это уже может стать причиной несогласованности данных из-за ошибок ввода. Если, например, ошибиться в фамилии или имени поставщика, то запрос на выдачу списка товаров по имени и идентификатору поставщика будет давать результаты, которые не совпадут с теми, которые будут получены при использовании только идентификатора этого поставщика. Но это не самое плохое в такой структуре таблицы. Более плохие ситуации возникнут не при выборке, а при модификации данных. Эти ситуации называют аномалиями. Каждая из аномалий связана с соответствующей модифицирующей операцией – вставкой, удалением и обновлением записей.
Прежде, чем перейти к обсуждению этих аномалий, определим первичный ключ таблицы "Категория_товар_поставщик". Поскольку один и тот же товар могут поставлять разные поставщики, а один и тот же поставщик может предлагать товары разных категорий и разные товары одной категории, то первичным ключом здесь может быть только набор из трех столбцов {код_кат, код_тов, код_пост}.
Аномалия вставки заключается в том, что мы не можем вставить, например, в таблицу поставщика, который еще не поставлял никакие товары. Это запрещает первичный ключ, который не может иметь NULL-значения. Следовательно, при вставке записи требуется ввести значения в столбцы код_кат и код_тов. Аналогично мы не может добавить категорию товара без товара и поставщика, а также занести информацию о товаре, поставщик которого еще неизвестен.
Аномалия удаления проявляется, в частности, в том, что при удалении товара с кодом 232 (например, в результате продажи всей партии данной книги) теряется информация о поставщике, который мог ничего другого не поставлять до текущего момента времени. А значит, мы потеряем его адрес, банковские реквизиты и т.п. Напомним, что удаление в базе данных выполняется строками.
Аномалию обновления рассмотрим на примере изменения имени поставщика Круглова Силантия Ивановича. Достаточно реальная ситуация такого события может произойти при создании данным человеком фирмы, в результате чего его фамилию потребуется поменять на название фирмы. Аномалия же состоит в том, что такое изменение требуется выполнить во всех строках таблицы, где он фигурирует в качестве поставщика. Чтобы автоматизировать этот процесс, нам потребуется написать дополнительный код.
Итак, аномалии модификации либо делают логическую модель, представленную в нашем примере таблицей "Категория_товар_поставщик", неадекватной предметной области, либо усложняют разработку приложения.
Причиной аномалий является объединение в одной таблице информации о разных сущностях предметной области. Чтобы избежать аномалий, следует разбить нашу таблицу на несколько таблиц (по числу независимых сущностей). Такой процесс называется декомпозицией. При этом информация, относящаяся к самостоятельной сущности, переносится в новую таблицу, а в исходной таблице остается столбец (столбцы), являющийся идентификатором этой сущности. В новой таблице этот идентификатор становится первичным ключом, чем обеспечивается связь между таблицами. Следует отметить, что исходная таблица восстанавливается без потери информации (декомпозиция без потерь) посредством реляционной операции естественного соединения. Если декомпозиция выполнена правильно, то это гарантируется теоремой Хеза.
Есть вполне формальная процедура нормализации, построенная на понятии функциональной зависимости.Начнем с определения функциональной зависимости. Атрибут Y функционально зависит от атрибута X (обозначается X -> Y), если значение атрибута Y однозначно определяется значением атрибута X.
Например, в нашем примере значение атрибута "поставщик" - Круглов Силантий Иванович однозначно определяется его идентификатором – 4 –значением атрибута "код_пост". Это, в отличии от математического понятия функциональной зависимости, не означает, что для любой записи в таблице "Категория_товар_поставщик", у которой в поле код_пост находится значение 4, в поле поставщик будет находиться именно Круглов Силантий Иванович. Это означает, что для одинаковых значений в поле код_пост, в поле поставщик также будут находиться одинаковые значения. Сейчас это может быть Круглов Силантий Иванович. Однако имя может измениться на название фирмы, и тогда это будет название фирмы, но важно, что везде для идентификатора 4 это будет одна и та же фирма.
Первой нормальной формой (1НФ) называется просто реляционное отношение. В частности, это предполагает атомарность атрибутов и наличие первичного ключа. Безусловно, таблица "Категория_товар_поставщик" находится в 1НФ, т.к. отвечает этим условиям.
Второй нормальной формой (2НФ) называется отношение, которое находится в 1НФ и которое не содержит неключевых атрибутов, зависящих от части составного ключа. Неключевым назовем атрибут, который не входит ни в какой потенциальный ключ. Вот тут у нас проблемы. В таблице Категория_товар_поставщик имеются такие зависимости:
Код_пост -> поставщикКод_тов -> наименованиеКод_кат -> наименование_катСправа в этих зависимостях стоят неключевые атрибуты, а слева – атрибуты, входящие в состав первичного ключа. Согласно теореме Хеза, которую мы здесь не будем доказывать, для выполнения декомпозиции без потерь следует вынести в отдельные отношения зависимые атрибуты вместе с тем атрибутом, от которого они зависят. Последний становится первичным ключом в новом отношении. Выполнив эту процедуру, мы получим четыре таблицы:
Таблица "Категория_товара"
| код_кат | наименование_кат |
| 1 | Книги |
| 4 | Хозтовары |
| 7 | Парфюмерия |
Таблица "Категория_товар_поставщик_1"
| код_кат | код_тов | код_пост |
| 1 | 28 | 34 |
| 1 | 231 | 4 |
| 1 | 232 | 5 |
| 4 | 186 | 4 |
| 4 | 200 | 4 |
| 7 | 224 | 6 |
| 4 | 200 | 25 |
Таблица "Товар"
| код_тов | наименование |
| 28 | История России |
| 231 | Камю. Бунтующий человек |
| 232 | Юнг. Человек и его символы |
| 186 | Дезодорант "Fa" |
| 200 | Дезодорант "Mennen speed stick" |
| 224 | Паста зубная "Помарин" |
Таблица "Поставщик"
| код_пост | поставщик |
| 34 | Костин Михаил Александрович |
| 4 | Круглов Силантий Иванович |
| 5 | Шевляков Иван Иванович |
| 6 | Иванов Сидор Петрович |
| 25 | Смирнов Сергей Александрович |
Все эти таблицы находятся в 2НФ. Действительно, новые таблицы содержат только два атрибута, один из которых (неключевой) зависит от ключевого. Исходная же таблица превратилась в полностью ключевую таблицу Категория_товар_поставщик_1, которая вообще не содержит неключевых атрибутов.
Исчезла и избыточность хранения информации; имя поставщика, название категории товара и название товара упоминается в базе данных только один раз. Одновременно с этим устранились и аномалии. Например, мы можем добавить поставщика, который пока не поставлял никакого товара; при удалении товара с кодом 232 мы не теряем информации о поставщике; изменение в названии поставщика теперь выполняется для одной строки, что никак не затрагивает другой информации в базе данных.